
详细分析ResNet | 用CarNet教你如何一步一步设计轻量化模型


本文引入了橄榄型分布来衡量编码器中不同网络阶段卷积层数的测试精度和推理效率。此外,在解码器中提出了一个轻量级的上采样特征金字塔块(UFPB),以融合编码器最后3个阶段的特征。CarNet在推理效率和测试精度之间取得了较好的平衡,优于现有的最先进的方法。
1简介
Pixel-wise裂纹检测是一项具有挑战性的任务,因为裂纹的连续性差,对比度低。现有框架通常采用复杂的模型,精度较高,但推理效率较低。
在本文中提出了一个轻量级的编码器-解码器体系结构CarNet,其可以高效和高质量地进行裂缝检测。为此,首先提出理想的编码器在不同阶段卷积层数的橄榄型分布。具体来说,随着编码器中网络阶段的加深,在初始网络阶段对模型输入进行压缩后,卷积层数呈下降趋势。
同时,在解码器中引入了一个轻量级的上采样特征金字塔模块,学习丰富的层次特征用于裂纹检测。特别将最后三个网络阶段的特征图压缩到相同的通道,然后使用不同倍数的上采样将其调整为相同的分辨率进行信息融合。
最后,在Sun520、Rain365、BJN260和Crack360四个公共数据库上进行的大量实验表明,CarNet在推理效率和测试精度之间取得了较好的平衡,优于现有的最先进的方法。
由于整个编码器-解码器网络看起来像一辆小汽车,因此作者将其称之为CarNet。该文章的主要贡献如下:
建立了2个新的路面裂缝数据集Sun520和Rain365。Sun520是目前最大的一个,而Rain365是雨场景下的第一个。
为了降低模型复杂度,提高推理效率,提出了一种关于网络各阶段卷积层数的Olive-type编码器。
在解码器中引入了一个轻量级模块UFPB,以获得丰富的层次特征,用于逐像素的裂缝检测。
在4个公共数据库上进行的大量实验表明,CarNet比现有的最先进的系统具有更好的测试精度,同时与最快的2个系统实现了相当的推断速度。
2所提方法
2.1 Olive-type编码器
在深度学习中,ResNet在防止梯度爆炸和梯度消失方面发挥了重要作用。由于ResNet最初是为ImageNet构建的,因此涉及到很高的模型复杂性。因此,如果直接使用ResNet作为裂纹检测模型的编码器,推理效率会不太友好,影响其在实际中的应用。
一般来说,模型复杂性包括空间复杂性和时间复杂性。通过模型参数可以粗略估计空间复杂度。时间复杂度可以通过浮点运算(FLOPs)反映出来。卷积运算是神经网络中常用的运算。以带偏置项的卷积运算为例,其参数和FLOPs分别为:
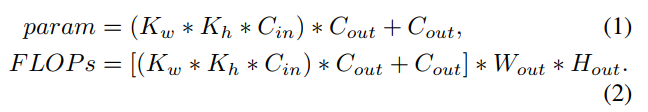
其中,
和
分别表示卷积核的宽度和高度。在VGG系列之后它们通常被设置为3。
和
分别表示输入通道和输出通道,
和
分别表示输出特征图的宽度和高度。
随着网络深度的加深,卷积通道数量会增加,特征图的分辨率会降低。由式(1)可知,为了降低模型空间复杂度,编码器中网络层次越深,卷积层越少。
另一方面,根据(2),为了降低模型的时间复杂度,理想的编码器在网络的不同阶段卷积层数应该呈橄榄型分布。换句话说,在中间网络阶段应该有更多的卷积层,在初始和尾部阶段应该有更少的卷积层。
该思想主要考虑了初始阶段的高分辨率和后阶段的大卷积通道。总之,提出卷积层的数量从网络的第2阶段开始减少。
具体来说,针对编码器,作者提出以下设计流程:
第一步,定义了网络阶段数量。分类模型通常分为5个阶段,如ResNet。为了降低编码器的时间和空间复杂度,本文采用了4个阶段对应4个降采样;
第二步,在初始阶段确定卷积层的数量。为了提高推理效率采用了ENet引入的早期降采样策略。该策略由下行采样块(DB)来执行;
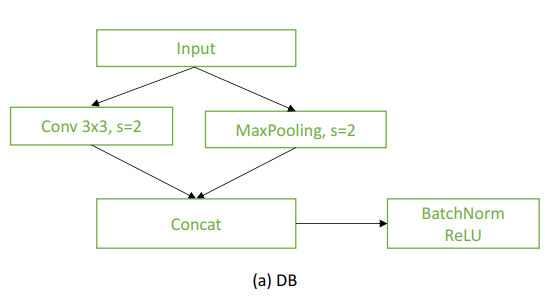
图(a)
如图(a)所示,在DB模块中,首先以并行方式将输入分别进入一个stride=2的3×3卷积和stride=2的最大池化层。然后,通过cat操作融合2分支的特征映射,再通过BN层和ReLU。
第三步,确定网络尾部和中间阶段的卷积层数。根据编码器的橄榄型分布,尾段卷积层数不超过一定值。
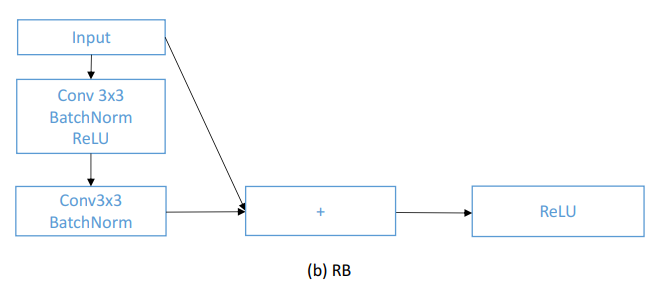
图(b)
例如,当使用ResNet34作为基准时,可以在编码器的靠后网络阶段使用2个残差块,对应4个卷积层。
注意,ResNet34在后部阶段有3个残差模块(RB),如图(b)所示,利用identity mapping作为一个shortcut,通过加法操作将2个叠置卷积层的输入和输出融合。
确定中间阶段的卷积层数。为了便于与ResNet34比较,设计的编码器也有34层。考虑到4个下采样块和尾网络阶段分别占用4个卷积层,编码器在第二和第三阶段可以分别使用7和6个残差块。注意,在ResNet34中,除了第一阶段的卷积层和最后的完全连接层外,其余阶段分别应用3个、4个、6个和3个残差模块。
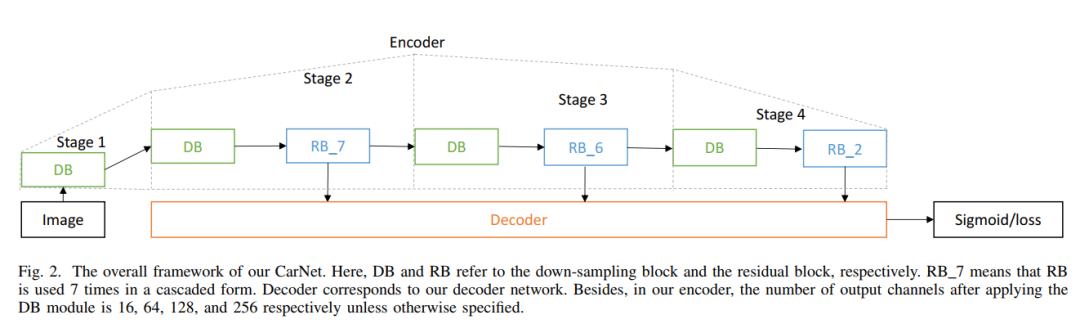
图2
最后,如图2所示的虚线框。通过上面的设计过程可以发现,虽然总层数相同,但是本文设计编码器和ResNet34在不同的网络阶段的网络阶段数和卷积层数是不同的。特别是,要求在初始网络阶段对模型输入进行压缩后,卷积层的数量开始减少。如表1所示,与原始的ResNet34编码器相比,编码器在像素方向的裂缝检测中更加高效和准确。
2.2 解码器
首先,受HED和Deeplab V3+的启发提出了一个轻量级的上采样特征金字塔块(UFPB)来捕获丰富的层次特征。
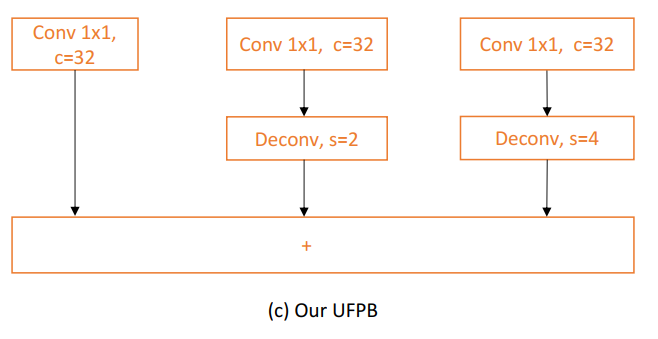
图(c)
具体来说,如图(c)所示:
首先,使用3个1×1卷积,分别在第2、第3和第4阶段压缩最后的卷积特征,使模块轻量化。注意3个分支中feature map的压缩通道是相同的,都是32个。
然后,分别对第3阶段和第4阶段的特征图进行2倍和4倍上采样,使其具有与第2阶段相同的分辨率。
最后,通过加法运算融合不同阶段的卷积特征。
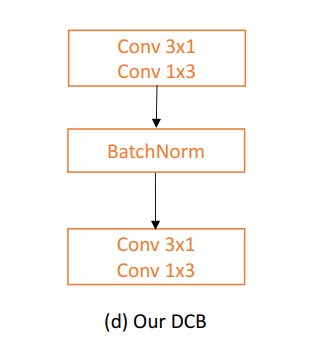
图(d)
接下来,构造一个分解卷积块(DCB)进一步增强了解码器的表示性。由于裂缝大多是线性结构,作者采用了2个级联分解卷积(即一个3×1和1×3卷积),替换解码器中一个常用的3×3卷积,如图(d)。
然后,利用1×1卷积将特征映射压缩到N−1个通道,其中N表示类别的数量。然后,通过四倍上采样将压缩后的特征映射恢复到模型输入大小。
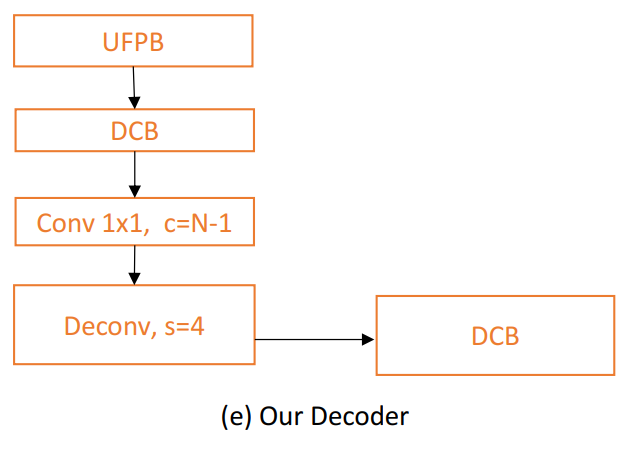
图e
最后,再次采用DCB模块开发丰富的卷积特征,然后将其提供给sigmoid分类器,如图(e)所示。
综上所述,所提出的编解码器网络构成了总体框架,如图2所示。因为它看起来像一辆车,所以我们叫它CarNet。此外,使用交叉熵损失来训练所提网络结构。
2.3 解码器对比
对于解码器网络,虽然模型是基于HED和Deeplab V3+,但在很多方面与他们不同。下面,简要说明它们在解码器上的差异。
1、Feature maps的恢复
Deeplab V3+依靠2次4倍上采样将编码器网络的输出逐渐恢复到模型输入的大小。除了2个4倍上采样外,所提模型还利用了一个额外的双重上采样来融合更多的特征信息,如UFPB模块所示。
同时,HED采用了更多不同倍数的上采样,将每个阶段的特征图直接还原到模型输入尺寸。因此HED在将低分辨率特征映射调整到模型输入尺寸时需要采用较大的反卷积核,因为其中的像素需要较大的接受域。同时,反卷积核在上采样过程中均为3个,减少了许多参数和计算量。
2、特征融合的对象和方法
所提模型利用了最后3个阶段的特性,HED利用了所有网络阶段的特性,而Deeplab V3+利用了第2和最后2个阶段的特性。另外,在信息融合方面,其他2个模型采用通道连接,而所提网络采用加法操作,在相同条件下可以减少参数和计算量。
3、进一步细化
与HED和Deeplab不同V3+,在将特征映射恢复到模型输入大小后,使用卷积进一步细化。考虑到裂缝大多为线性结构,为了节省计算,采用2个堆叠的非对称卷积核来代替一个普通的方形卷积核。
4、解码器的数量
所提模型和Deeplab V3+使用一个解码器,HED使用6个解码器分别对应一个融合输出和5个侧输出。因此HED需要对不同输出的损失函数进行权衡,这就造成了模型训练难度的加大。此外,更多的分支结构增加了内存访问成本,从而降低了模型的推理效率。
3实验
3.1 数据集
作者在4个公共数据库上评估网络,分别是Sun520、Rain365、bjn260和Crack360。
Sun520由520张在晴天拍摄的照片组成。它是目前最大的开源裂缝数据库。此外,裂缝图像的拍摄时间包括上午、下午和黄昏。换句话说,数据具有丰富的图像亮度。
Rain365包含了在雨后白天拍摄的365张图片。这些裂缝图像是指三种不同的背景,即完全湿润、部分湿润、部分干燥或完全干燥。其中全湿背景占多数。
BJN260包含260张北京夜景图片。夜晚的街道环境复杂多变,如光源、亮度强度等,造成裂缝检测困难。
为了节省计算资源,将上述三个数据库中图像的分辨率从3968×2240调整为480×320。在Sun520,Rain365,BJN260上分别随机选择400,300,200张图像进行训练,剩下的120,65,60张图像分别进行测试。
此外,为了验证模型对相对连续裂纹的影响,作者使用了cracktree260和CRKWH100分别用于训练和测试。前者包含260张图像,每个图像有800×600像素。这些图像在训练时被裁剪成512×512。后者包含100幅图像,每幅图像有512×512像素。为方便起见,将以上两个数据集统一为一个数据库,Crack360。
3.2 实验结果
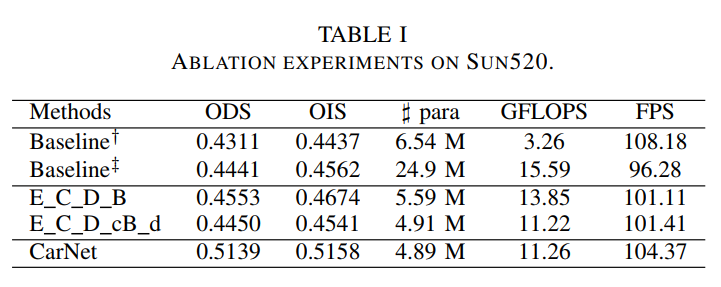
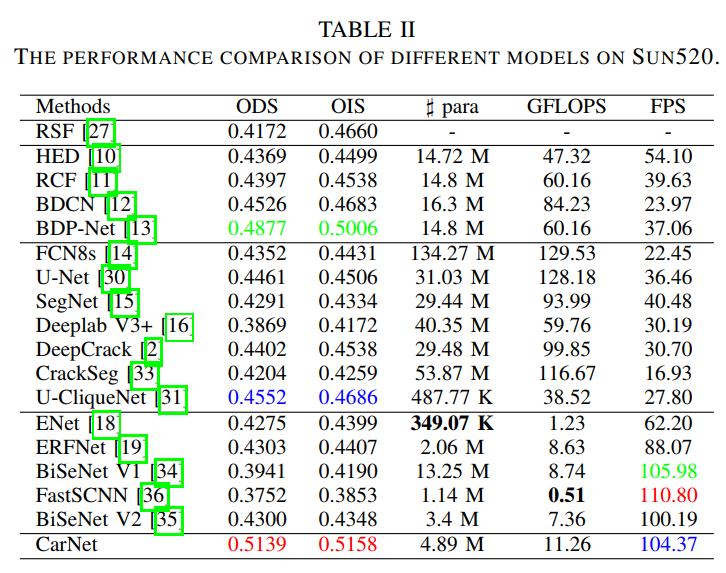

通过在SUN520数据的实验结果可以看出,CarNet有更好的结果以及鲁棒性,同时具有更快的推理速度。
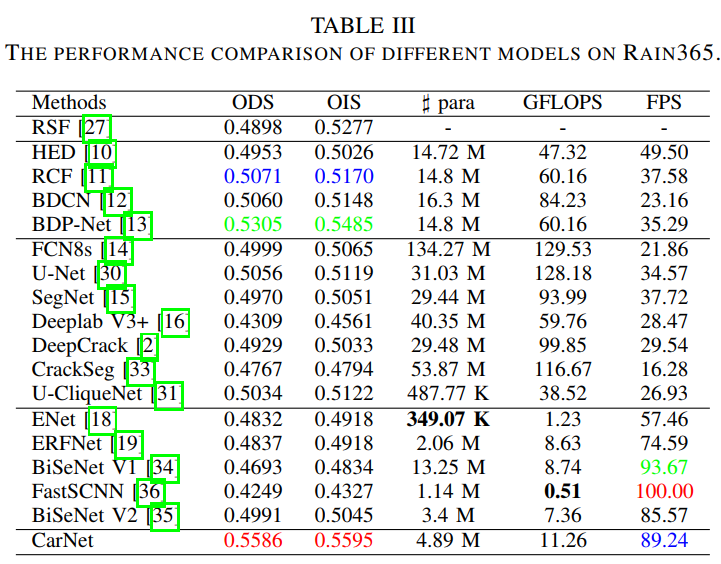
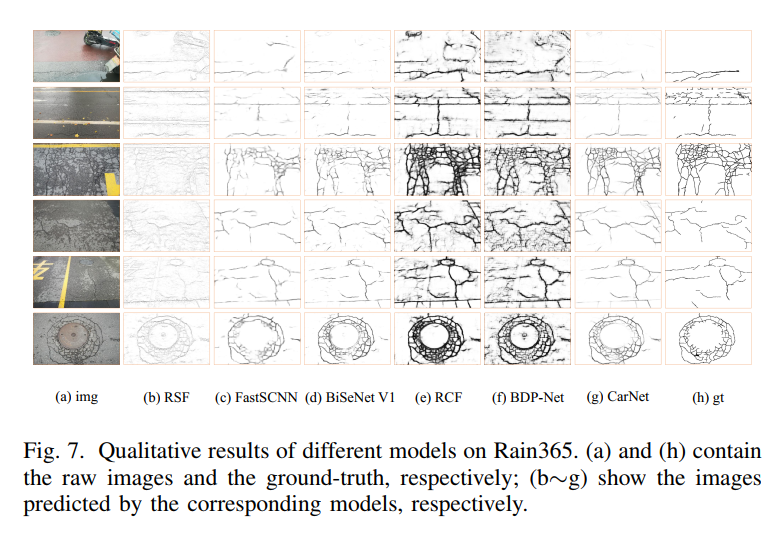
通过在RAIN365数据的实验结果可以看出,CarNet有更好的结果以及鲁棒性,同时具有更快的推理速度。
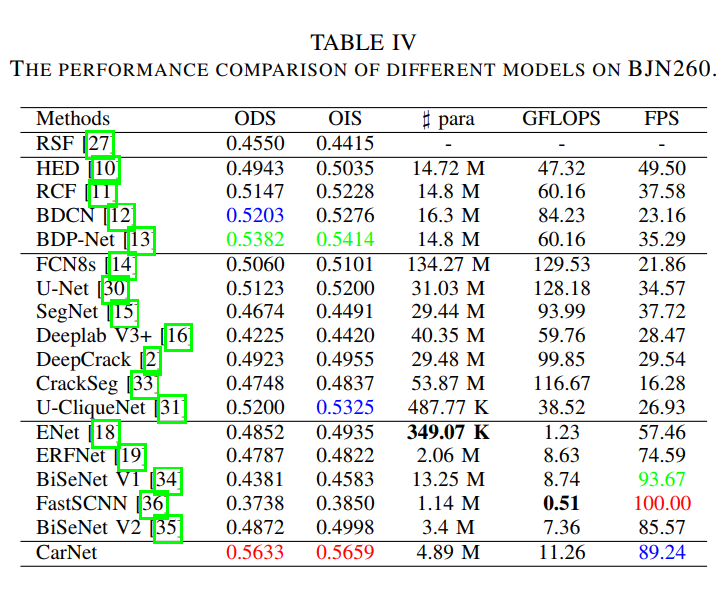

通过在BJN260数据的实验结果可以看出,CarNet有更好的结果以及鲁棒性,同时具有更快的推理速度。可以看出即使是夜间依然可以有很好的效果。
4参考
[1].CarNet: A Lightweight and Efficient Encoder-Decoder Architecture for High-quality Road Crack Detection
5推荐阅读

高效Transformer | 85FPS!CNN + Transformer语义分割的又一境界,真的很快!
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
