
Disruptor高性能之道-无锁化
JUC中的队列BlockingQueue是通过加锁实现对生产者和消费者的协调。
加锁就意味着需要牺牲高性能,换来线程安全。
有没有办法既能高性能,还能线程安全?
Disruptor给出的答案是,“无锁”。
❝无锁,并不是完全消除锁,而是指没有OS层面的锁。
Disruptor通过CAS(Compare And Swap)指令实现了无锁化。具体的指令是cmpxchg,本文会做简单讲解。感兴趣的读者可以自行搜索资料了解详细内容。
❞
简单解释下CAS具体干了什么事情。
❝CAS, 比较并交换,Compare And Swap。顾名思义,就是通过比较值是否发生变化,决定是否要重新赋值。如果在操作期间,值没有被其他线程操作,那么就将期望的值赋值给它,否则发现期望的值与旧值不等,说明值已经变更,则不执行操作,返回操作失败。
❞
举个栗子
比如说,旧值oldValue为1,期望的值expectValue为1,新值newValue为2。如果没有其他线程修改旧值,那么
expectValue == oldValue 将newValue写入,当前值为2
如果在操作过程中,oldValue被其他线程操作修改为2,那么当前线程的expectValue(1)与oldValue(2)比较就不等,写入失败。
Disruptor如何进行CAS
我们知道Disruptor核心数据结构为RingBuffer,Disruptor为RingBuffer分配了一个Sequence对象,用于标识RingBuffer的头和尾,这个标识不是通过指针实现的,而是通过序号。
❝这个序号也就是Sequence。
❞
虽然逻辑上RingBuffer是一个环形数组,但是在内存中是以一个普通的数组形式存在的。
RingBuffer中通过对比序号的方式对生产者和消费者间的资源进行协调。
每当生产者要往队列中加入新数据,生产者都会将当前sequence + 准备加入队列的数据量,与消费者所在位置进行比较,以判断是否存在足够的空间放这些数据,而不至于覆盖掉消费者没有消费的数据。
用体育术语就叫“套圈”。
如图所示:ringBufferSize=16,生产者当前sequence指向20,消费者sequence指向27。
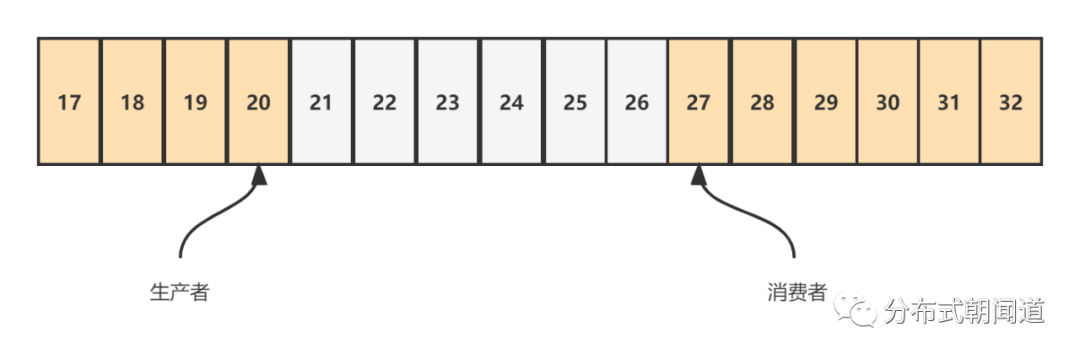
我们简单计算一下这个场景下,生产者能否继续写入4个元素。
对于消费者而言,27 MOD 16 = 11 对于生产者而言,20 + 4 = 24(预计写入的最大序号),24 MOD 16 = 8 生产者若成功写入4个元素,则sequence指向数组的第8个位置,8 < 11, 表明生产者没有覆盖消费者的进度。 生产者不需要等待消费者,直接生产数据即可。而且并不会覆盖消费者未处理完的数据。
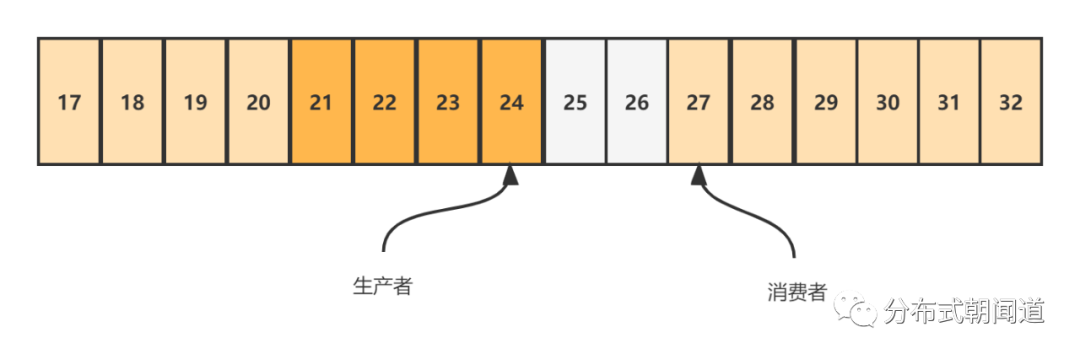
实际上,Disruptor的代码实现就是通过compareAndSet方法实现了CAS无锁化操作。
/**
* Atomically add the supplied value.
*
* @param increment The value to add to the sequence.
* @return The value after the increment.
*/
public long addAndGet(final long increment)
{
long currentValue;
long newValue;
do
{
currentValue = get();
newValue = currentValue + increment;
}
while (!compareAndSet(currentValue, newValue));
return newValue;
}
我们可以看到,这里通过while循环不断尝试CAS操作,如果CAS操作不成功就会自旋重试,这个操作并没有使用OS层面的锁,因此效率要大幅高于OS层面的锁机制(管程)。
addAndGet调用了compareAndSet方法:
/**
* Perform a compare and set operation on the sequence.
*
* @param expectedValue The expected current value.
* @param newValue The value to update to.
* @return true if the operation succeeds, false otherwise.
*/
public boolean compareAndSet(final long expectedValue, final long newValue)
{
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expectedValue, newValue);
}
可以看到最终是调用了UNSAFE的compareAndSwapLong方法,该方法为native方法,在JVM层面调用了CAS指令。
CAS指令
上文我们提到,Disruptor的CAS最终调用的是CPU层面的机器指令「cmpxchg」。
该指令的详细描述:
compxchg [ax] (隐式参数,EAX 累加器),
[bx] (源操作数地址),
[cx] (目标操作数地址)
简单解释下:
cmpxchg指令有三个操作数,操作数ax不在指令里面出现,是一个隐式的操作数,准确地说它是EAX累加寄存器里面的值。 操作数bx是源操作数,指令会对比这个操作数和上面的累加寄存器里面的值是否相等,如果相等
CPU 会把 ZF(也就是条件码寄存器里面零标志位的值)设置为 1,然后再把操作数cx(也就是目标操作数)设置到源操作数的地址上。如果不相等的话,就把源操作数里面的值设置到累加器寄存器里面
由于cmpxchg是cpu级别的指令,因此直接调用就可以保证cas操作的原子性。
由于去除了OS层面的锁,即便CAS存在比较操作与自旋操作,其本质也是无锁化操作,这种无锁化机制消除了上下文切换,对于CPU极为友好,因此运行效率很快。
事实上,在JUC包中,也提供了大量的CAS相关工作类方便我们操作,这些类一般以atomic开头,如果去研究其实现,我们同样会发现最终是通过UNSAFE调用了底层的CAS实现,实现无锁化操作,减少上下文切换,提升代码运行速率。
❝加锁导致的上下文切换之所以会显著影响代码运行速度,主要原因在于获取锁的过程中,CPU需要等待OS层面的锁竞争结果,对于没有获取锁的线程需要进行挂起,此时就需要进行上下文切换。
上下文切换会把挂起线程的寄存器中的数据放到线程栈,该操作会导致加载到高速缓存中的数据也失效,进而导致程序运行速率比无锁更慢。
❞
CAS就没有什么问题么?
当然CAS操作同样也会存在缺点,那就是由于CAS操作本身需要进行对比,如果不相等则会一直自旋(busy-wait),这样的操作会使得cpu的负载升高,全功率满负荷运行。