
高性能无锁并发框架Disruptor,太强了

源 /月伴飞鱼 文/
为什么会产生Disruptor框架
基本概念
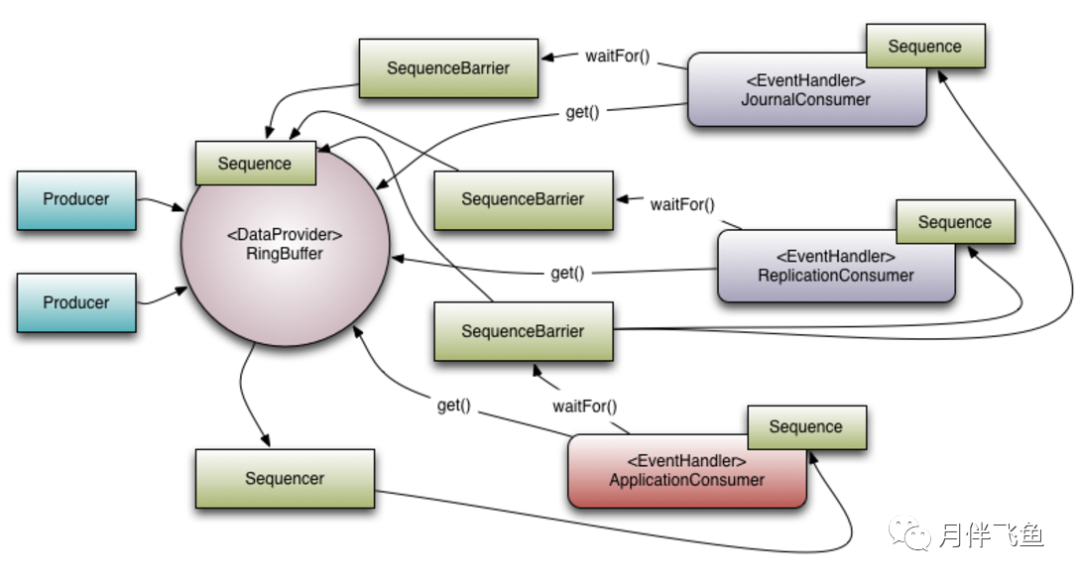
等待策略
LockSupport.parkNanos(1)来实现循环等待。Thread.yield()以允许其他排队的线程运行。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。使用举例
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
//定义事件event 通过Disruptor 进行交换的数据类型。
public class LongEvent {
private Long value;
public Long getValue() {
return value;
}
public void setValue(Long value) {
this.value = value;
}
}
public class LongEventFactory implements EventFactory<LongEvent> {
public LongEvent newInstance() {
return new LongEvent();
}
}
//定义事件消费者
public class LongEventHandler implements EventHandler<LongEvent> {
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception {
System.out.println("消费者:"+event.getValue());
}
}
//定义生产者
public class LongEventProducer {
public final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer byteBuffer) {
// 1.ringBuffer 事件队列 下一个槽
long sequence = ringBuffer.next();
Long data = null;
try {
//2.取出空的事件队列
LongEvent longEvent = ringBuffer.get(sequence);
data = byteBuffer.getLong(0);
//3.获取事件队列传递的数据
longEvent.setValue(data);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} finally {
System.out.println("生产这准备发送数据");
//4.发布事件
ringBuffer.publish(sequence);
}
}
}
public class DisruptorMain {
public static void main(String[] args) {
// 1.创建一个可缓存的线程 提供线程来出发Consumer 的事件处理
ExecutorService executor = Executors.newCachedThreadPool();
// 2.创建工厂
EventFactory<LongEvent> eventFactory = new LongEventFactory();
// 3.创建ringBuffer 大小
int ringBufferSize = 1024 * 1024; // ringBufferSize大小一定要是2的N次方
// 4.创建Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor,
ProducerType.SINGLE, new YieldingWaitStrategy());
// 5.连接消费端方法
disruptor.handleEventsWith(new LongEventHandler());
// 6.启动
disruptor.start();
// 7.创建RingBuffer容器
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
// 8.创建生产者
LongEventProducer producer = new LongEventProducer(ringBuffer);
// 9.指定缓冲区大小
ByteBuffer byteBuffer = ByteBuffer.allocate(8);
for (int i = 1; i <= 100; i++) {
byteBuffer.putLong(0, i);
producer.onData(byteBuffer);
}
//10.关闭disruptor和executor
disruptor.shutdown();
executor.shutdown();
}
}
核心设计原理
2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。数据结构
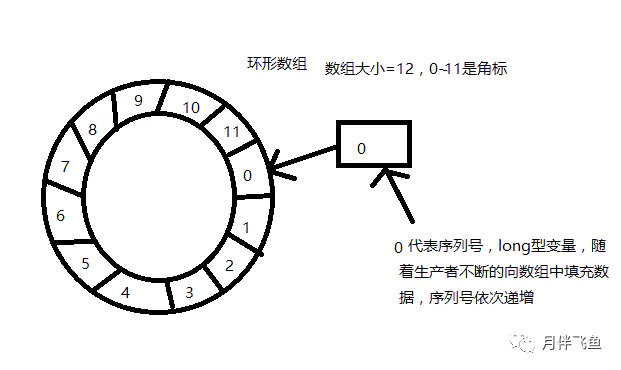
Sequence
index=sequence % table.length。当然也可以用位运算来计算效率更高,此时table.length必须是2的幂次方。写数据流程
申请写入m个元素; 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素; 若是返回的正确,则生产者开始写入元素。 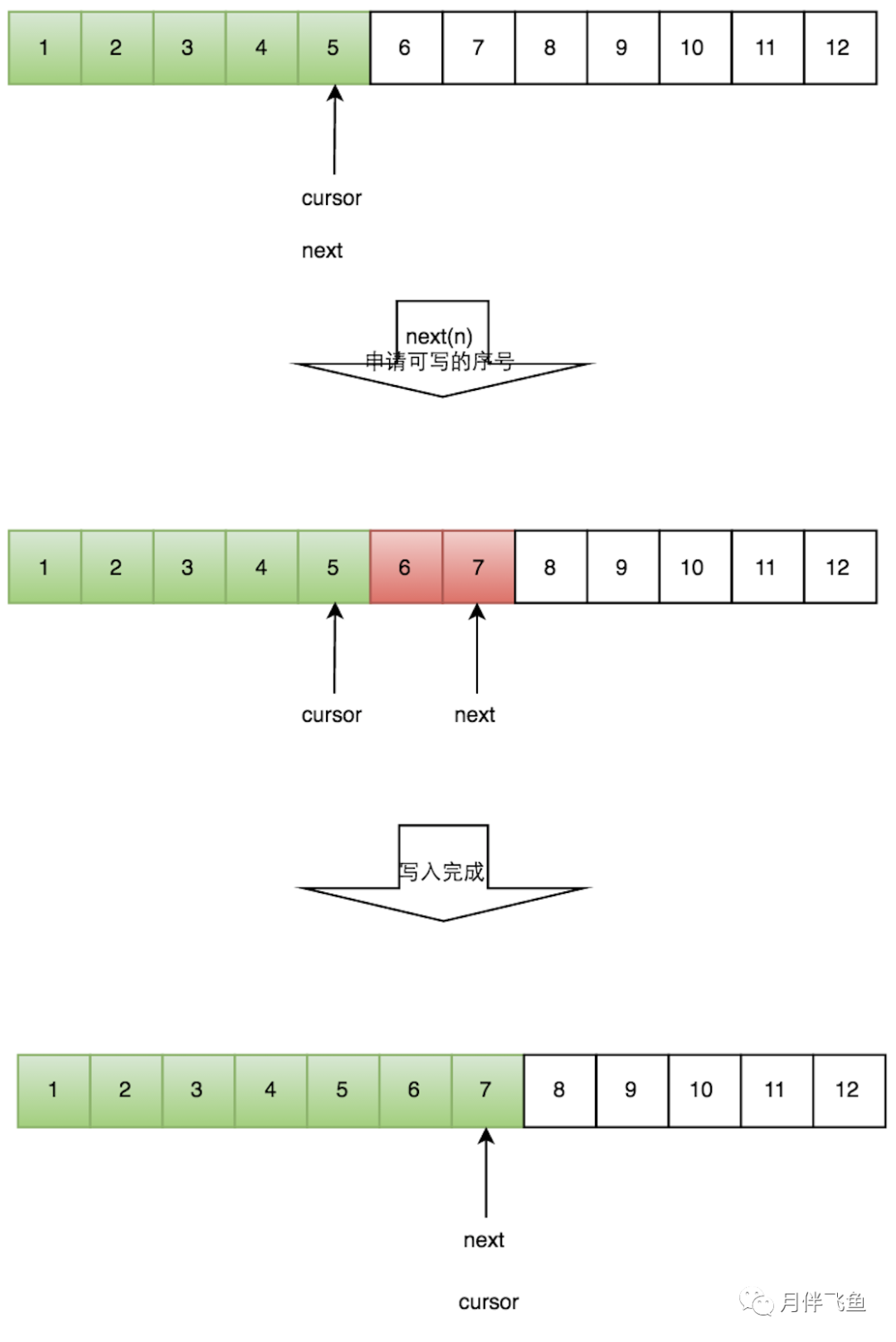
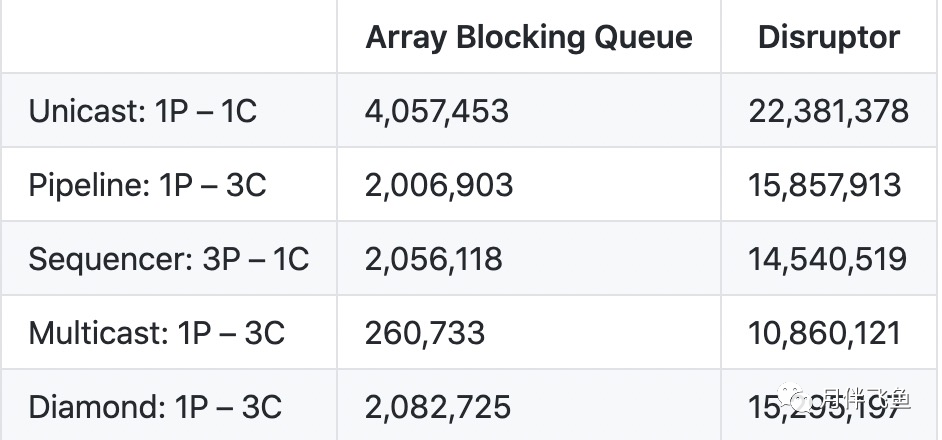
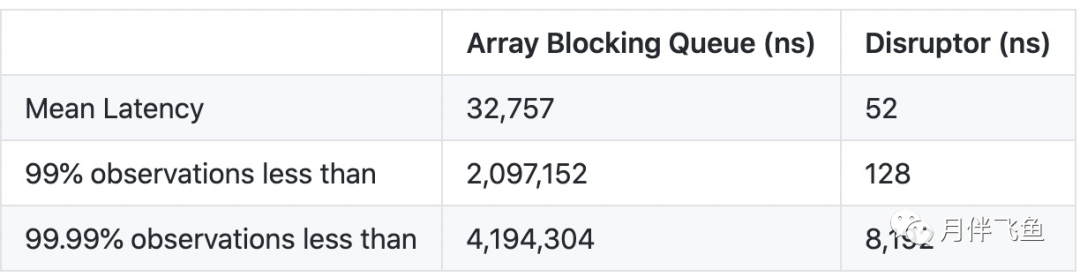
使用场景

好文推荐

阿里某P8征婚:年薪170万,择偶要求却被群嘲!

某程序员曝光美团面试骗局:还没发offer就让自己离职,提出离职后却说没有hc,拒绝发offer!

字节跳动小组长无意中得知整个部门的薪资!自己只有28K!手下人却拿35K!怎么办?
END


顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」
评论