
MobX流程分析与最佳实践
大力辅导项目在首页多个 tab,课程详情、社区、语文字词和个人信息页等多个业务场景深度使用 Flutter 进行开发,而在 Flutter 开发过程中状态管理是绕不开的话题。
在进行 Native 开发时,我们命令式地来表述 UI 构建和更新逻辑,通过类似 setText、setImageUrl 的代码对界面 UI 进行构建与更新。和 Native 开发不同,在进行 Flutter 开发时,UI 的构建是声明式的,这种框架结构直接影响了我们对更新逻辑的表达形式。
Flutter 中触发状态更新的 API 即我们最熟悉的 setState 方法,但是项目中往往会碰到状态需要跨层级或者在兄弟组件之间共享,仅仅使用 setState 一般不足以覆盖复杂状态管理的场景。因此我们需要状态管理框架来帮助我们规范更新逻辑,同时也能更好地贴合 Flutter framework 的工作机制。
框架选型
我们在初期调研了多个开源的状态管理框架包括 BLoC、Redux 以及 MobX 等。
BLoC 使用流共享数据,并且 Dart 语言本身对流的亲和度很高,参考其它平台的 ReactiveX 的解决方案,开发者可以快速地使用这种模式进行开发。BLoC 的最大问题是,其它的 ReactiveX 每个数据源都是独立的 Stream,但是 BLoC 则是统一的单 Stream。单 Stream 表达整个页面的所有业务逻辑不具有普适性,其抽象层级过高,部分场景需要配合其他的方案。
就 Js 领域最流行的 Redux 框架而言,由于 Redux 本身的一些特点,Redux 的主打功能是应用状态可预知、可回溯,同时它也有使用上的成本,比如要求 reducer 是纯函数,store 之间的交流需要最佳实践指导,样板代码较多,可能需要开发同学有一定的 FP 开发背景。Redux 是诸多框架中编码最为繁琐,样板代码较多的一个。不过大量的模板代码也规范了代码风格,大型项目中,Redux 更规范易操作扩展和维护。
MobX 的数据响应对开发者几乎完全透明,开发者可以更加自由地组织自己的应用程序的状态,拥有比较高的易用性和扩展性,也易于学习,更加符合 OOP 的思想,也可以更快地支持业务迭代。使用 MobX,使得我们更加可以关注状态本身和状态引起的变化,不需要关心那么多复杂组件是如何组合连接起来的,所有的事情都被简单优雅的 API 抽象掉了。不过,MobX 自身过于自由的特性也带来了一些麻烦,由于编码没有模板约束,过于自由,容易导致团队代码风格不统一,不同的页面不同的风格,代码难以管理维护,对此往往需要制定统一的团队编码规范。
基于我们项目目前的规模,以及迭代速度,同一个页面相邻版本的两次迭代很有可能发生了很大的变化,MobX 的简单易用性最有利于我们的项目进行高强度快速迭代。最终我们在诸多框架中,选择了使用 MobX 作为我们项目的状态管理框架,本文着重分析 MobX 数据绑定和更新的主流程,以及最佳实践。
使用方法不再详述,参见 MobX.dart 官网,我们着重分析一下 MobX 驱动页面更新的主流程,包含两部分:数据绑定与数据更新。分析的代码基于 MobX 的 1.1.0 版本。
为了更直观的分析,我们直接使用官网经典的 MobX Counter 这个 demo 进行示例,通过 debug 的堆栈帮助我们去探究 MobX 中数据的绑定和更新的主流程。
数据绑定流程
Observer 和 @observable 对象一定通过某种方式建立了绑定关系,我们先来研究一下数据的绑定流程。
从 reportRead() 入手
Atom.reportRead()
在代码中获取显示的数字 counter.value 处打一个断点,从 demo app 打开开始,第一次页面 build 时,代码会执行到生成的. g.dart 中去。我们来看 value 相关的 get 方法和 Atom 对象:
final _$valueAtom = Atom(name: '_Counter.value');
@override
int get value {
_$valueAtom.reportRead();
return super.value;
}
复制代码
生成的. g.dart 文件中有一个 Atom 对象,其中覆写了 counter.value 的 get 方法,我们每次使用 @observable 标记一个字段,在 .g.dart 中就会生成该字段的 getter 跟 setter 及对应的 Atom 对象。Atom 对象是对原字段的一个封装,当我们读取 couter.value 字段时,会在该 Atom 上调用 reportRead():
extension AtomSpyReporter on Atom {
void reportRead() {
...
reportObserved();
}
...
}
void reportObserved() {
_context._reportObserved(this);
}
复制代码
ReactiveContext._reportObserved()
这个_context,追溯一下可以看到是一个全局的 ReactiveContext 单例,注释写的比较明白了:

它负责处理 Atom 跟 Reaction(下文会讲到) 的依赖关系, 及进行数据方法绑定、分发、解绑等逻辑。
最终走到了 context 中的_reportObserved 方法,这个 Atom 对象被添加到了一个 derivation 的_newObservables 字段中,该_newObservables 类型为 Set:
void _reportObserved(Atom atom) {
final derivation = _state.trackingDerivation;
if (derivation != null) {
derivation._newObservables.add(atom);
if (!atom._isBeingObserved) {
atom
.._isBeingObserved = true
.._notifyOnBecomeObserved();
}
}
}
复制代码
Atom 对象被类型为 Derivation 的变量 derivation 持有在一个_newObservables 的 Set 里面,我们回到之前打断点的堆栈,来看一下这里的 derivation 到底是什么。
回到起点
堆栈信息
下图为整个页面从 main.dart 的 runApp 开始到 MyHomePage 这个 Widget 的 build 的过程,从 debug 的堆栈信息入手:
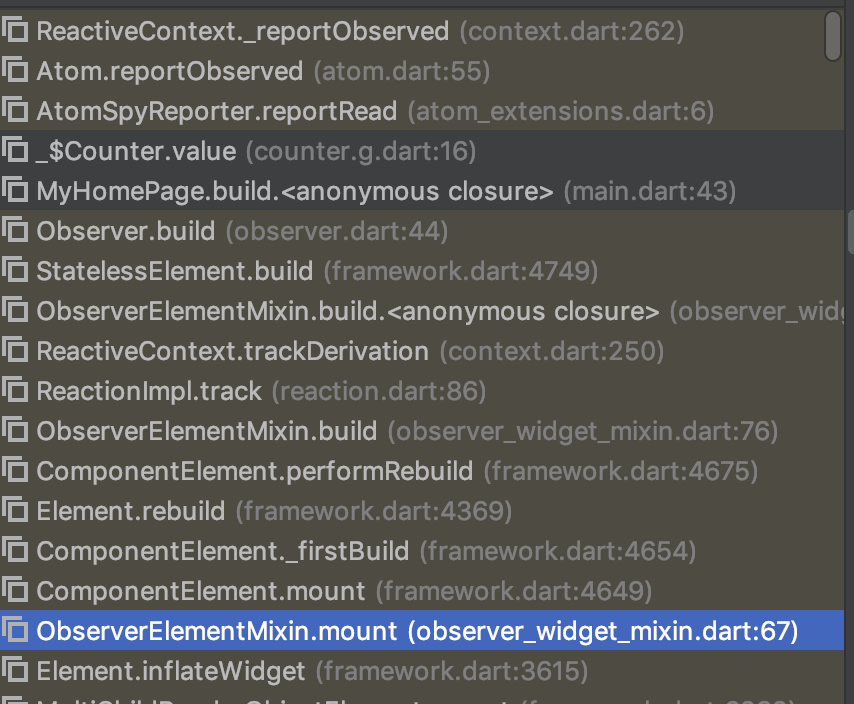
Observer 相关的 Widget 和 Element
首先我们简单看一下 Observer 以及相关的 Widget 和 Element 的概念。我们通常使用的 Observer 这个 Widget,它实际上是一个 StatelessObserverWidget(继承自 StatelessWidget),其 build 方法中的 Widget 就是 builder 中返回的 widget,该 StatelessObserverWidget 还 mixin 了 ObserverWidgetMixin,StatelessObserverWidget 的 Element 为 StatelessObserverElement,该 Element 也 mixin 了 ObserverElementMixin,他们之间的关系如图所示:

ObserverElementMixin.mount()
从该部分开始看起:
@override
void mount(Element parent, dynamic newSlot) {
_reaction = _widget.createReaction(invalidate, onError: (e, _) {
... ));
}) as ReactionImpl;
...
}
复制代码
ObserverElementMixin 的 mount 方法给_reaction 赋了值,再追溯一下,ObserverWidgetMixin 的 createReaction 方法传入了上文提到的核心的 ReactiveContext 单例,创建了 Reaction,而 Reaction 实现了 ReactionImpl 类,ReactionImpl 又实现自 Derivation,在 Derivation 类中我们看到了上一部分提到的_newobservables 这个 Set:
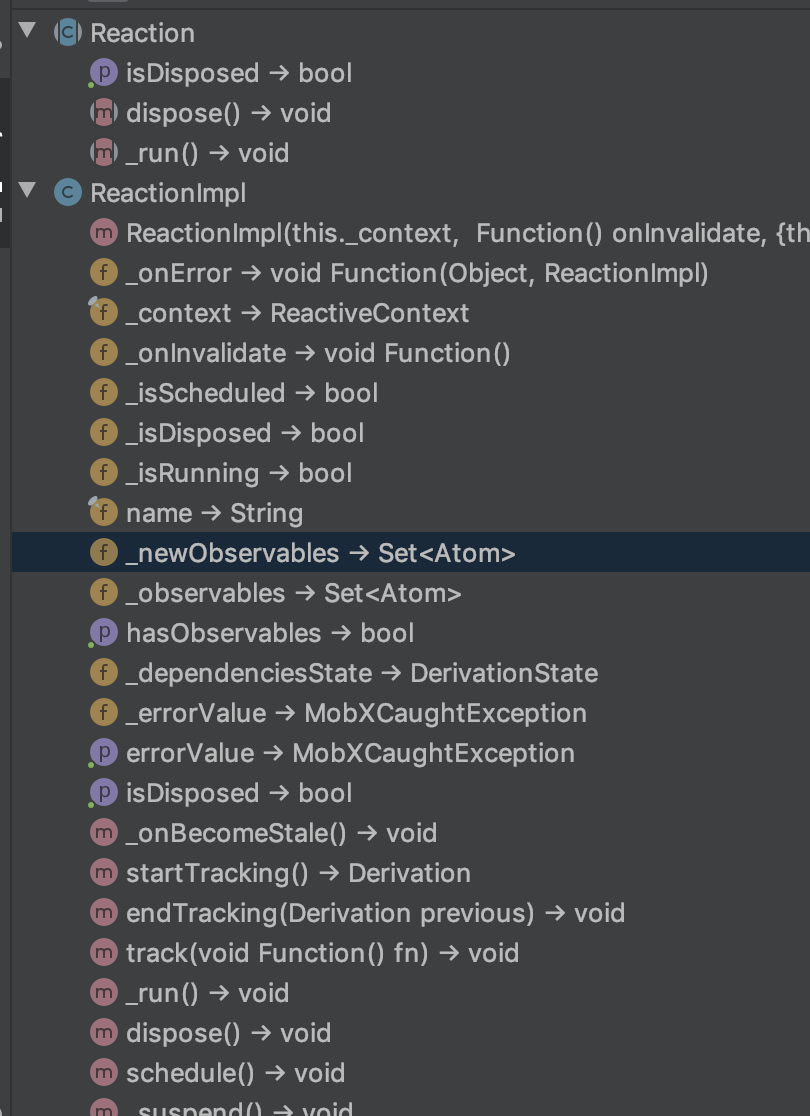
此时可以有一个初步的猜想:由 Observer 这个 Widget 持有了 ReactionImpl,ReactionImpl 中持有了_newobservables 这个 Set,在 @observable 变量被读取的时候通过对应 Atom 对象的 reportRead 方法将该 Atom 对象添加入了这个 Set,这样就 Observer 这个 Widget 通过其中的 ReactionImpl 间接的持有了 @observable 对象。
继续往下看我们来验证一下。
ObserverElementMixin.build()
按着堆栈信息走下去。来到 ObserverElementMixin 的 build() 方法,调用了 mount 中创建的 ReactionImpl 的 track() 方法:
Widget build() {
...
reaction.track(() {
built = super.build();
});
...
}
复制代码
ReactionImpl.track() -> ReactiveContext.trackDerivation()
此处剔除掉了大部分和主流程无关的代码,如下:
void track(void Function() fn) {
...
_context.trackDerivation(this, fn);
...
}
//主流程关注这两句
T trackDerivation<T>(Derivation d, T Function() fn) {
final prevDerivation = _startTracking(d);
...
result = fn();
...
_endTracking(d, prevDerivation);
...
}
复制代码
ReactiveContext 的 trackDerivation() 方法接收 Derivation 参数,这里传入自身,来到下面,在_startTracking 和_endTracking 之间调了 fn,这里的 fn 就是 ObserverElementMixin 的 build 方法中传入的 super.build():
ReactiveContext._startTracking()
_startTracking() 中做的是对状态的更新。其中的_state 是个_ReactiveState,就是一个对 ReactiveContext 单例当前状态的封装的类,这里我们关注 trackingDerivation,是当前正在被记录的一个 Derivation。
_startTracking() 中最重要的一步是把_state 中记录的 trackingDerivation 赋值为当前的 Derivation(即上方传入的 ReactionImpl),这一步很关键,直到_endTracking 执行之前,这个 state.trackingDerivation 都是当前设置的值,并返回一个 prevDerivation(上一个记录的 trackingDerivation):
Derivation _startTracking(Derivation derivation) {
final prevDerivation = _state.trackingDerivation;
_state.trackingDerivation = derivation;
_resetDerivationState(derivation);
derivation._newObservables = {};
return prevDerivation;
}
复制代码
Observer.builder 调用的位置
在_startTracking 和_endTracking 之间调用了 fn,即 ObserverElementMixin 中传入的 super.build(),熟悉 dart mixin 语法规则的,也很快清楚这里调用链最终会走到 Observer 这个 Widget 的 build 方法,也即我们使用时传入的 builder 方法里面去:
class Observer extends StatelessObserverWidget implements Builder {
...
@override
Widget build(BuildContext context) => builder(context);
...
}
复制代码
这时候就回到了一开头的部分,builder 中读取了 counter.value,也即调用它的 get 方法,通过 reportRead,最终再通过 state.trackingDerivation 得到当前正在记录的 derivation 对象,并给他的_newObservables 的这个 Set 里面添加了 counter.value 对应的封装的 Atom 对象。
解决一开始我们提出的问题——持有_newObservables 的 derivation 是什么?
derivation 就是_startTracking() 方法中赋值给_state.trackingDerivation 的当前 ObserverElementMixin 中持有的 ReactionImpl 对象。Observer 通过该对象间接持有了我们的 @observable 对象,也验证了我们上文的猜想。
回顾下,经过上面_startTracking 中将当前的 derivation 赋值给 context.state.trackingDerivation ,以及 Observer 的 builder 方法(fn)的调用,builder 方法中任何对 @observable 对象的 get 方法,都将经过 reportRead,也就是 reportObserved,所以该 @observable 对象就会被添加到当前的 derivation 的 _newObservables 集合上,表示该 derivation 和 @observable 对象的依赖关系,注意此时这样的绑定关系是单向的,目的是为了收集依赖。真正的数据绑定过程在_endTracking() 中。
ReactiveContext._endTracking()
最后再看_endTracking,核心的建立绑定关系的方法是_bindDependencies:
void _endTracking(Derivation currentDerivation, Derivation prevDerivation) {
_state.trackingDerivation = prevDerivation;//这里又会把trackingDerivation恢复回去
_bindDependencies(currentDerivation);
}
void _bindDependencies(Derivation derivation) {
//derivation里面实际上有两个set _observables和_newObservables,分别装的是之前旧的atom和reportRead里面新加的atom
//搞了两次difference, 把新的和旧的@observable变量分开。旧的清空数据,新的绑定观察者
final staleObservables =
derivation._observables.difference(derivation._newObservables);
final newObservables =
derivation._newObservables.difference(derivation._observables);
var lowestNewDerivationState = DerivationState.upToDate;
// Add newly found observables
for (final observable in newObservables) {
observable._addObserver(derivation);//绑定观察者
// Computed = Observable + Derivation
if (observable is Computed) {
if (observable._dependenciesState.index >
lowestNewDerivationState.index) {
lowestNewDerivationState = observable._dependenciesState;
}
}
}
// Remove previous observables
for (final ob in staleObservables) {
ob._removeObserver(derivation);//解除绑定
}
if (lowestNewDerivationState != DerivationState.upToDate) {
derivation
.._dependenciesState = lowestNewDerivationState
.._onBecomeStale();
}
derivation
.._observables = derivation._newObservables
.._newObservables = {}; // No need for newObservables beyond this point
}
//下面是atom的_addObserver和_removeObserver方法
//atom中有个observers变量 Set<Derivation>对象,记录了观察自己的Derivation。
void _addObserver(Derivation d) {
_observers.add(d);
if (_lowestObserverState.index > d._dependenciesState.index) {
_lowestObserverState = d._dependenciesState;
}
}
void _removeObserver(Derivation d) {
_observers.remove(d);
if (_observers.isEmpty) {
_context._enqueueForUnobservation(this);
}
}
复制代码
这个方法的逻辑,根据前后两次 build 时 Set 中收集 Atom 对象的依赖,分别执行 _addObserver 和 _removeObserver,这样,每个 @observable 对象上的 observers 集合都会是最新的了。
结论
Observer 对应的 Element——StatelessObserverElement,持有一个 Derivation——即 ReactionImpl 对象 reacton**,** 而该对象持有一个 Set 类型的_observables,@observable 对象在被读取调用 get 方法的时候,对应的 Atom 被添加到了这个 Set 中去,该 Set 中的 @observable 对象对应的 Atom 在 endTracking 中调用了_addObserver 方法,把观察自己的 ReactionImpl 添加进 observers 这个 Set 中去。从而 @obsevable 对象对应的 Atom 持有了 Observer 这个 Widget 中的 ReactionImpl,Observer 就这样和 @observable 对象建立了绑定关系。
数据更新流程
知道了 Observer 和 @observable 对象是怎样建立联系之后,再来看一下当我们修改 @observable 对象时候,更新界面逻辑是怎么触发的。
reportWrite()
在. g.dart 文件中,覆写了 @observable 变量的 get 方法,会在 get 时候调用对应 Atom 对象的 reportRead(),并且这里还覆写了 @observable 变量的 set 方法,都会调用 Atom 对象的 reportWrite() 方法,这个方法做了两件事情
更新数据
把与之绑定 的 derivation (即 reaction) 加到更新队列。
@override set value(int value) { _$valueAtom.reportWrite(value, super.value, () { super.value = value; }); }
最终可以追溯到这里:
void propagateChanged(Atom atom) {
if (atom._lowestObserverState == DerivationState.stale) {
return;
}
atom._lowestObserverState = DerivationState.stale;
_observers就是上面数据绑定过程中涉及到的atom对象记录观察者的Set<Derivation>
for (final observer in atom._observers) {
if (observer._dependenciesState == DerivationState.upToDate) {
observer._onBecomeStale();
}
observer._dependenciesState = DerivationState.stale;
}
}
复制代码
ReactionImpl._onBecomStale()
@override
void _onBecomeStale() {
schedule();
}
void schedule() {
...
_context
..addPendingReaction(this)
..runReactions();
}
复制代码
ReactiveContext.addPendingReaction()
reaction 添加到队列,reaction也就是上面传入的ReactionImpl
void addPendingReaction(Reaction reaction) {
_state.pendingReactions.add(reaction);
}
复制代码
ReactiveContext.runReactions
void runReactions() {
...
for (final reaction in remainingReactions) {
reaction._run();
}
_state
..pendingReactions = []
..isRunningReactions = false;
}
复制代码
ReactionImpl.run()
@override
void _run() {
...
_onInvalidate();//这里实际上就是触发更新的地方
...
}
复制代码
这边的_onInvalidate() 就是在 ObserverElementMixin.mount() 里面 createReaction 时候传进去的
@override
void mount(Element parent, dynamic newSlot) {
_reaction = _widget.createReaction(invalidate, onError: (e, _) {
... ));
}) as ReactionImpl;
...
}
复制代码
看看 invalidate 是什么:
void invalidate() => markNeedsBuild();
复制代码
也就是 markNeedsBuild 标脏操作,这样 Flutter Framework 的 buildOwner 会在下一帧重新调用 build 方法,就完成了数据更新操作。
结论
至此数据更新的流程也搞明白了,在更改 @observable 变量的时候,调用到 Atom 对象的 reportWrite 方法,首先更新了数据,然后把与之绑定的 ReactionImpl 对象 derivation 加到队列 pendingReactions,最终队列里面的 ReactionImpl 调用 run 方法,触发 markNeedsBuild,完成了界面更新。
在使用 MobX 进行状态管理的过程中,我们也踩了一些坑,总结了最佳实践,对开发过程中时常遇到的更改数据页面未被更新的情况做了总结。
因为 MobX 的数据绑定是运行时的,所以需要注意绑定不要写在控制流语句中,同时也要注意绑定的层级。在此看三个 bad case,同时引出最佳实践。相信在了解了框架数据绑定和更新的原理之后,也很容易理解这些 bad case 出现的原因。
Bad Case 1:
Widget build(BuildContext context) {
return Observer(builder:(context){
Widget child;
if (store.showImage) {
child = Image.network(
store.imageURL
);
} else {
// ...
});
}
复制代码
这个例子里面 store.imageURL 是一个被 @observable 标注的字段。如果在第一次 build 的过程中,即数据绑定的过程中,store.showImage 为 false,代码走 else 分支,这样 store.imageURL 就没能和 Observer 建立绑定关系,后续 store.imageURL 发生改变,就无法驱动界面更新。
Bad Case 2:
Widget build(BuildContext context) {
return Observer(builder:(context){
Widget child;
if (store.a && store.b && store.c) {
child = Image.network(
store.imageURL
);
} else {
// ...
});
}
复制代码
这个例子里面 store.a、store.b 还有 store.c 都是 @observable 标注的 bool 变量,遵循大部分语言的逻辑表达式判断规则,if 语句中多个并列的与的条件,如果排列靠前的条件为 false,那么后续的条件不会再被判断,直接走入 else 分支。
那么问题也显而易见了,如果本意是希望 store.a、store.b 还有 store.c 都和 Observer 绑定关系,如果在第一次 build 时,store.a 为 false,那么 b 和 c 均没有和 Observer 建立联系,这样 b 和 c 的变化就无法驱动该 Widget 更新。
Bad Case 3:
针对我们开发过程中一个常见的错误举出这个 Case:
class WidgetA extends StatelessWidget{
Widget build(BuildContext context) {
...
Observer(builder:(context){
return TestWidget();
});
...
}
}
class WidgetB extends StatelessWidget {
@override
Widget build(BuildContext context) {
return GestureDetector(
child: Text(
'${counter.value}',
style: Theme.of(context).textTheme.headline4,
),
onTap: () {
counter.increment();
},
);
}
}
复制代码
这个例子改编自 MobX 官网经典的 counter Demo,counter.value 是 @observable 标注的字段。编写者的本意是用 Observer 包裹了 WidgetB,希望 GestureDetector 的点击事件使得 counter.value 自增,驱动 Observer 的 Widget 的更新,不过我们点击按钮发现页面并没有更新。
根据上述原理分析,数据绑定的过程是在_startTracking 和_endTracking 之间的 Observer.build 方法的调用过程中完成的。而这里 Observer.builder 中只是 return 了 TestWidget,也即调用了 WidgetB 的构造方法,WidgetB 的 build 方法,也即读取 counter.value 的方法是在下一层 widget 构建的过程中,才会被调用,因此 counter.value 未能和它上一层的 Observer 建立绑定关系,自然也不能够驱动页面更新了。
Good
我们针对 Bad Case 2 提出最佳实践:
Widget build(BuildContext context) {
return Observer(builder:(context){
Widget child;
bool a = store.a;
bool b= store.b;
bool c = store.c;
if (a && b && c) {
child = Image.network(
store.imageURL
);
} else {
// ...
});
}
复制代码
对于 @observable 对象的依赖依次罗列在最开始,而不是写在 if 判断括号中,就可以保证所有变量均和 Observer 建立了绑定关系。
MobX 还有许多其他的细节,比如,context 上的 startBatch 相关,这是因为 action 中可以调用其他的 action,为了减少不必要的更新通知调用,通过 batch 机制合并 pendingReaction 的调用。同理,在 reaction 内部也可以对 @observable 对象进行更新,因此也需要 batch 机制合并更改。
MobX 也有一些优化点,比如,上述数据更新的 reportWrite 方法,我们可以 diff 一下 oldValue 和 value,看二者是否相等,不相等的时候再进行后续流程。
有兴趣的读者可以自行阅读源码探索更多的内容,在此不作详细分析了。

关注公众号「前端Sharing」,持续为你推送精选好文。