
基于 MLIR 完成对 GEMM 的编译优化 中英视频上,中部分
欢迎给B站账号 GiantPandaCV 点个关注:
这个视频讲解了如何基于 MLIR 完成对 GEMM 的编译优化。也即对 HIGH PERFORMANCE CODE GENERATION IN MLIR: AN EARLY CASE STUDY WITH GEMM (https://arxiv.org/pdf/2003.00532.pdf) 这篇论文的走读。
作者在高层次的Dialect上定义了一个矩阵乘算子,这个算子的参数包含了输入矩阵(A,B)以及输出矩阵(C),同时为这个算子添加了tile/unroll 的尺寸等属性。
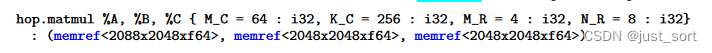
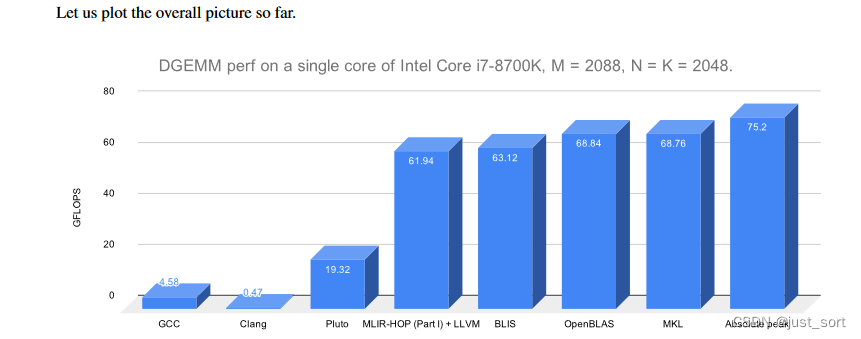
其中,(M_C, K_C)的选择使得 M_CxK_C 大小的 A 矩阵块能够在L2 cache中复用,(K_C, N_R)的选择使得 K_CxN_R 大小的B矩阵块能够在 L1 cache 中复用,(M_R, N_R)的选择是使得 M_RxN_R 大小的输出矩阵块能够在 CPU Register 中复用。在这篇论文中凭借经验尝试了很多组这种值,最终获得的结果如下:
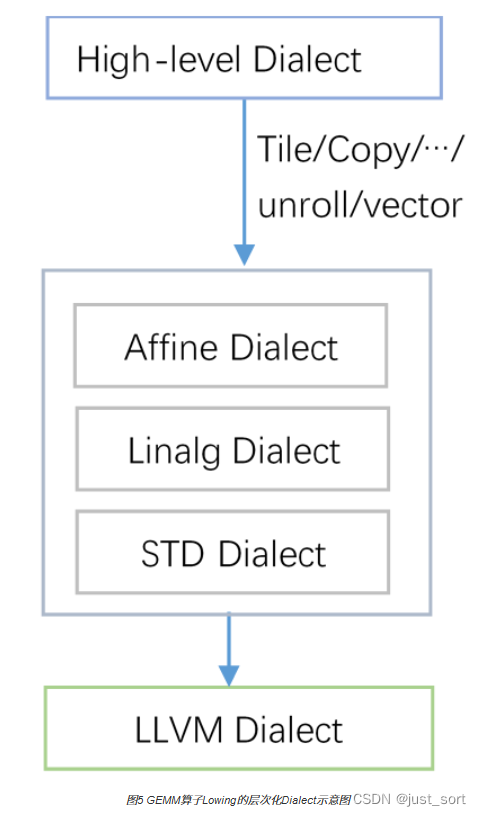
基于 MLIR 的矩阵乘算子 Dialect 递降过程为:
如果你对基于 MLIR 的深度学习模型高性能代码生成比较感兴趣的话建议研究一下 IREE ,这篇论文感觉还是有一点 Toy 。
相关资料:
https://www.birentech.com/news/115.html(写得挺好的,可以配合这个视频以及论文原文观看) https://arxiv.org/pdf/2003.00532.pdf
前30分钟视频如下(还剩下13分钟视频下周争取补上),视频转载自 https://www.youtube.com/watch?v=boXl7rmaasU&t=2372s ,添加了中英文字幕 :
评论