
阿里面试题:Pandas中合并数据的5个函数,各有千秋!
join主要用于基于索引的横向合并拼接; merge主要用于基于指定列的横向合并拼接; concat可用于横向和纵向合并拼接; append主要用于纵向追加; combine可以通过使用函数,把两个DataFrame按列进行组合。
join
索引一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[0, 1, 2])
x.join(y)

索引不一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[1, 2, 3])
x.join(y)

merge
可以指定不同的how参数,表示连接方式,有inner内连、left左连、right右连、outer全连,默认为inner;
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
pd.merge(x,y,how="left")

concat
纵向拼接
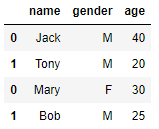
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
z = pd.concat([x,y],axis=0)
z
横向拼接
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
z = pd.concat([x,y],axis=1)
z

append
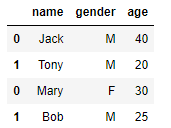
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
x.append(y)
combine
x = pd.DataFrame({"A":[3,4],"B":[1,4]})
y = pd.DataFrame({"A":[1,2],"B":[5,6]})
x.combine(y,lambda a,b:np.where(a>b,a,b))

我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
评论