
如何选择合适的损失函数,请看......
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达



▌回归损失
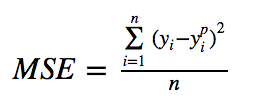
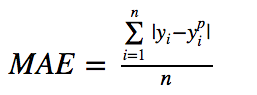
#true:真正的目标变量数组
#pred:预测数组
**
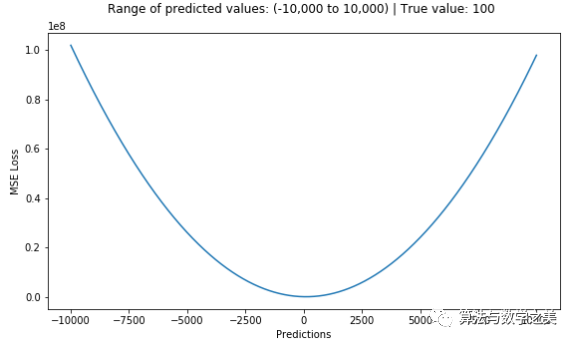
def mse(true, pred):
return np.sum(((true – pred)**2))
**
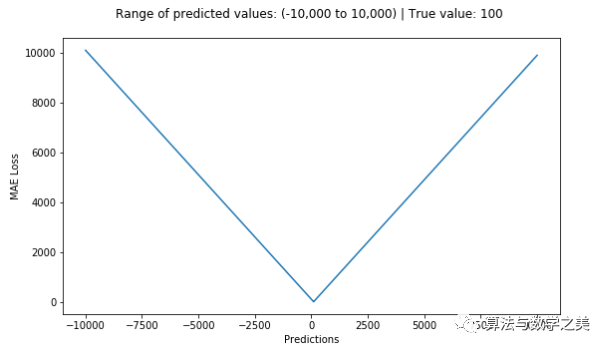
def mae(true, pred):
return np.sum(np.abs(true – pred))
**
#也可以在sklearn中使用
**
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
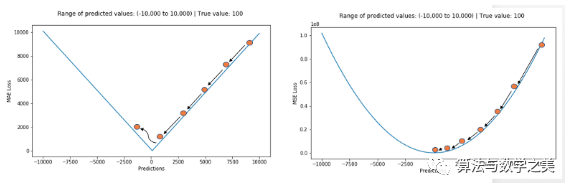
地址: http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/
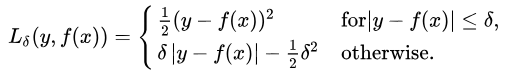


def sm_mae(true, pred, delta):
"""
true: array of true values
pred: array of predicted values
returns: smoothed mean absolute error loss
"""
loss = np.where(np.abs(true-pred) < delta , 0.5*((true-pred)**2), delta*np.abs(true - pred) - 0.5*(delta**2))
return np.sum(loss)
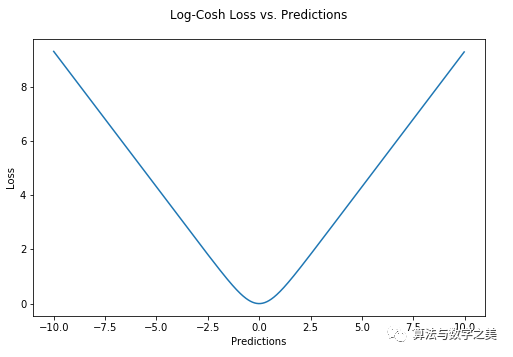
def logcosh(true, pred):
loss = np.log(np.cosh(pred - true))
return np.sum(loss)
地址: https://github.com/groverpr/Machine-Learning/blob/master/notebooks/09_Quantile_Regression.ipynb
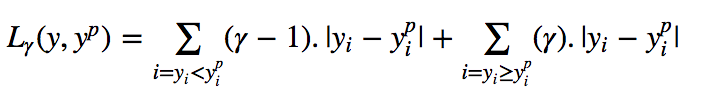
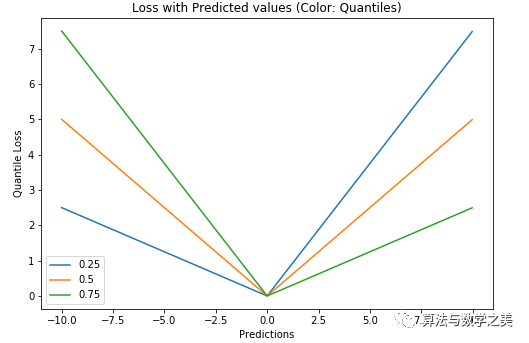
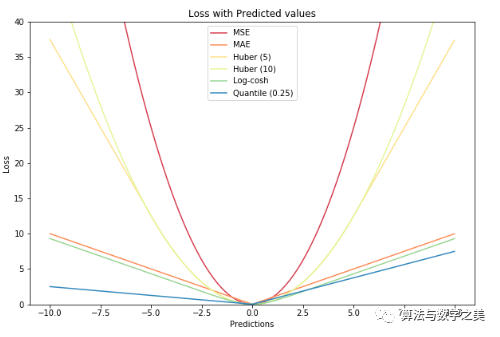
▌比较研究
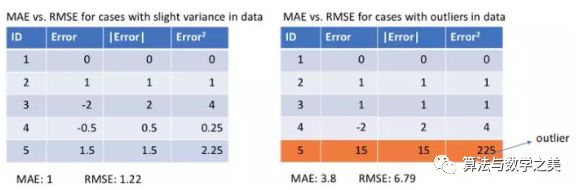
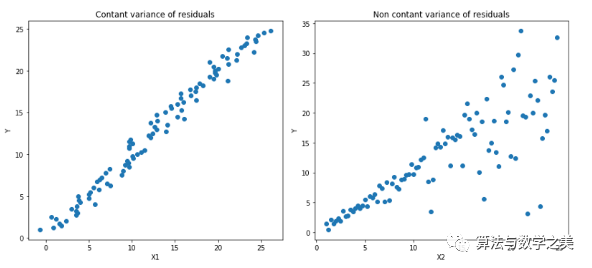
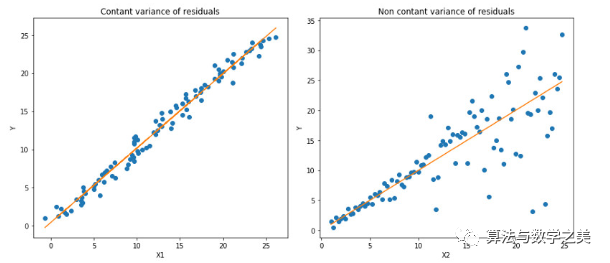
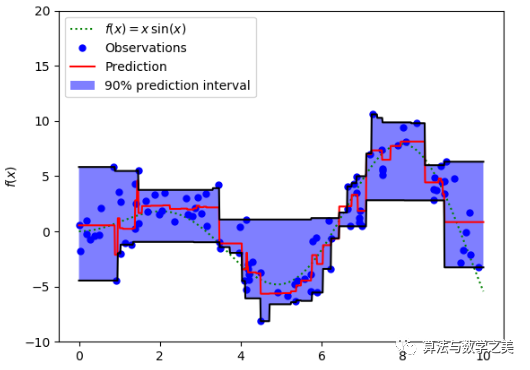
以MAE为损失的模型预测较少受到脉冲噪声的影响,而以MSE为损失的模型的预测由于脉冲噪声造成的数据偏离而略有偏差。
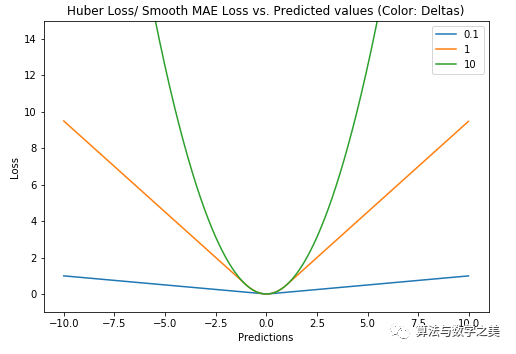
以Huber Loss为损失函数的模型,其预测对所选的超参数不太敏感。
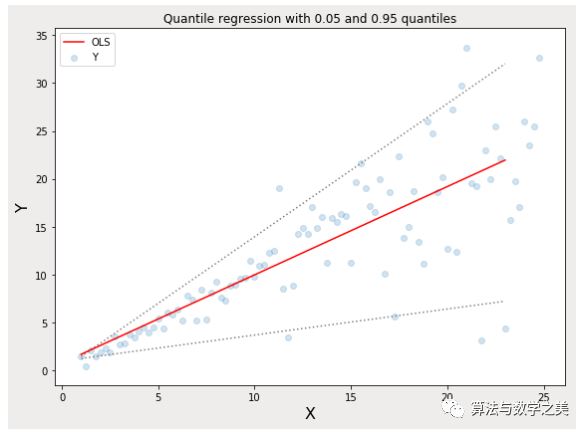
Quantile Loss对相应的置信水平给出了很好的估计。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论