
第一视角:深度学习框架这几年
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


和深度学习框架打交道已有多年时间。从Google的TensorFlow, 到百度的PaddlePaddle,再到现在腾讯的无量。很庆幸在AI技术爆发的这些年横跨中美几家公司,站在一个比较好的视角看着世界发生巨大的变化。在这些经历中,视角在不断切换,从最早的算法研究,到后来的框架开发,到机器学习平台和更多基础架构,每一段都有不同的感受和更深的领悟。
清明节这几天有些时间写了这篇文章,从我的视角,用几个深度学习框架串起来这些年历史上的一些有趣的插曲,和技术背后的一些故事,免得宝贵的记忆随着时间在脑中淡去。
 TensorFlow
TensorFlow

入门
故事开始在2015年底,我结束了在Google Core Storage和Knowledge Engine的工作,加入了Google Brain,在Samy Bengio下担任一名Research Software Engineer,简称RSWE。RSWE角色的产生主要是因为Google Brain和DeepMind发现Research Scientist很难在研究中解决复杂的工程问题,并最终技术落地。因此需要卷入一些工程能力比较强的Engineer和Scientist一起工作。而我比较“幸运”的成为Google Brain第一个RSWE。
加入新组的前一个周末,非常兴奋的提前探访了Google Brain的办公地点。想到能近距离在Jeff Dean旁边工作还是有些小激动,毕竟是读着MapReduce, BigTable, Spanner那些论文一路成长起来的。办公场所没有特别,Jeff和大家一样坐在一起,比较意外的是发现我工位旁几米的办公室门牌上写着谷歌创始人Larry Page&Sergey Brin,办公室被许多奖杯,证书,太空服之类的杂物包围着。看来公司对于AI技术的重视程度真实非常的高。
言归正传,早期的TensorFlow比较缺模型示例,相关API文档还不太规范,于是先开始给TensorFlow搭建模型库。我花了一年时间把Speech Recognition, Language Model, Text Summarization, Image Classification, Object Detection, Segmentation, Differential Privacy, Frame Prediction等模型写了一遍,后来成为TensorFlow github上model zoo的雏形。那年还是个到处都是低垂果实的时候,没有GPT3这种极其烧钱的大模型,只要对模型做一些小的调整,扩大模型的规模,就能刷新State-Of-The-Art。Bengio大佬经常在世界各地云游,偶尔回来后的1v1还是能给我不少的指引。印象深刻的第一次面聊,这位写过几百篇论文的一字眉大神给刚刚入门的我在白板上手推了gradient descent的一些公式。另外一次1v1,他发给我一本Ian Goodfellow写的书(当时还是草稿pdf),然后我每天晚上就躺在茶水间的沙发上一边做实验一边读书。
那年还发生了件有意思的插曲,AlphaGo大战人类棋手。DeepMind和Brain有非常紧密的合作关系,组里组织了一轮paper reading,仔细研读了相关的paper,然后大家带上啤酒和零食组织了观战活动,感觉就有点像是在看球赛。那次学会了两件事,强化学习算法,还有围棋的英文是Go。
16年是TensorFlow高速发展的一年。Jeff的演讲里经常有TensorFlow代码被引用次数指数级暴涨的图。但是16年也是TensorFlow被喷的比较惨的一年。TF的Operator粒度是非常细的,据说这是从内部上一代框架DistBelif上吸取的教训。细粒度的Operator可以通过组合形成各种高层的Layer,具有更好的灵活性和扩展性。然而,对于性能和易用性来说却是比较严重的问题,一个模型随便就有几千个甚至跟多的Operator。举几个例子:
当时我要实现第一个基于TensorFlow的ResNet,光为了写一个BatchNormalization(查了好几个内部版本竟然都有些问题),需要通过5~10个细粒度的算子通过加减乘除的方式组装起,1001层的ResNet有非常多的BatchNorm,整个ResNet有成千上万个Operator,可想而知,性能也不怎么样。不久后我朋友Yao搞了个Fused BatchNormalization,据说能让整个ResNet提速好几成。
BatchNormalization只是初级难度,做Speech Recognition时为了在Python层用TensorFlow完成BeamSearch也花了不少功夫。当时写了个End-to-End的模型,用的是Seq2Seq with Attention,能够一个模型直接把声音转成文字。为了把搜索生产线上语音识别的数据训到最后收敛,用128个GPU整整花了2个月的时间。每天早上上班第一件事就是打开TensorBoard,放大后才能看到Loss又下降了那么一点点。
16年时TensorFlow训练模式主要是基于Jeff等几位的Paper,基于参数服务器的异步训练是主流。训练速度线性扩展性不错,但是今天基于ring的同步训练在NLP,CV这些领域的声音更响一些。记得第一次和Jeff单独交流是关于Speech Recognition分布式训练的实验情况,加到128个GPU做异步训练基本能保证线性扩展,但是基于SyncOptimizer的同步训练速度会慢很多。当时Jeff问了下收敛效果有没有收到影响,我懵了一下,说没有仔细分析过,赶紧回去查一下。顺便八卦一下,Jeff真是非常瘦,握手的时候感觉几乎就剩皮包骨了。
开发过一些模型后发现算法研究员其实还有不少痛点。1. 不知道怎么Profile模型。2. 不知道怎么优化性能。为了解决这两个问题,我抽空写了个tf.profiler。tf.profiler的原理比较简单,就是把Graph, RunMeta和一些其他的产物做一些分析,然后用户可以通过CLI,UI或者python API快速的去分析模型的结构,Parameter, FLOPs, Device Placement, Runtime等属性。另外还做了个内部数据的抓取任务,去抓算法研究员的训练任务的metrics,如果发现GPU利用率异常,网络通行量过大,数据IO慢时会自动发邮件提醒,并给出一些修改的建议。
让一个专心搞算法研究的人写一个白板的数学公式不难,但是让他去搞明白复杂的任务配置,分布式系统里的性能、资源、带宽问题确是件很困难的事。无论多么牛的研究员都会问为什么任务没能跑起来,是资源不够还是配置不对。记得有天傍晚,人不多,Geoffrey Hinton大神突然走过来问到Can you do me a favor?My job cannot start...(正当我准备答应时,Quoc Lee已经抢先接单了,真是个精神的越南小哥。。。)

Moonshots
Google Brain每年会组织一次Moonshots提案,许多后来比较成功的项目都是这样孵化出来的,比如AutoML,Neural Machine Translation等等。团队成员会提出一些当时技术比较难达到的项目,大家组成类似兴趣小组的形式投入到这些项目中。

现在火的一塌糊涂的AutoML有点因为商业化或者其他原因,感觉已经对原始的定义做了极大的拓展。当时Brain孵化这个项目的时候有两队人在做LearningToLearn的项目,一个小队希望通过遗传算法来搜索更优的模型结构,另一个小队则决定使用强化学习算法搜索。遗传算法小队在使用资源时比较谨慎,通常只使用几百个GPU。而另一个小队则使用了几千个GPU。最后强化学习小队更早的做出了成果,也就是Neural Architecuture Search。而另一个小队虽然后来使用更多的GPU也达到了类似的效果,但是要晚了不少。
一个比较有趣的插曲是Brain虽然很早就有几万张GPU,但是每当论文截稿的前一段时间总是不够用,其中搞NAS的同学常常在邮件中被暗示。为了解决资源的分配问题,领导们被卷入了一个非常长的email,后来大概解决方案是每个人会被分配少量的高优先级GPU和适量的竞争级GPU资源。而NAS的同学因为已经完成了资本的原始积累成为了一个很火的项目,得到了特批的独立资源池。为了支持这个策略,我又开发了个小工具,现在回头想想还挺吃力不讨好的。
Pytorch

动态图
快速成长的时间总是过得很快,Megan加入Brain后,我被安排向她汇报,当时的RSWE团队已经有十几人,而Google Brain也从几十人变成了几百人。
2017年初,经Megan介绍,TensorFlow团队一位资深专家Yuan Yu找到我,问有没有关注Pytorch,约我调研后一块聊聊。于是我就去网上搜集了一下Pytorch的资料,又试用了一下。作为一个TensorFlow的深度用户,我的第一反应就是Pytorch解决了TensorFlow很大的痛点,用起来非常的“自然”。
和Yuan聊完后,我们快速的决定在TensorFlow上也尝试支持类似Pytorch的imperative programming用法。Demo的开发过程还算比较顺利,我大概花了一个多月的时间。记得当时我把项目命名为iTensorFlow, short for imperative TensorFlow。(后来被改名成eager,感觉好奇怪)。
Demo的设计思路其实也不复杂:1. TensorFlow graph可以被切分成任意粒度的Subgraph,可以通过函数调用的语法直接执行,2. TensorFlow对用户透明的记录执行过程以用于反向梯度计算。给用户的感觉就就类似Python native的运行。
进而产生几个推导:1. 当Subgraph的粒度是operator时,基本等价于Pytorch。2. 当Subgraph粒度由多个operator组成时,保留了graph-level optimization的能力,可以编译优化。
最后再埋个伏笔:1. tf.Estimator可以自动的去融合Subgraph,形成更大的Subgraph。用户在开发阶段基于imperative operator-level Subgraph可以简单的调试。用户在部署阶段,可以自动融合大的Subgraph,形成更大的optimization space。
做完之后,我非常兴奋的和Yuan演示成果。Yuan也说要帮我在TensorFlow里面推这个方案。当时Pytorch的成长速度非常的快,TensorFlow的Director也召集了多名专家级的工程师同时进行方案的探索。当时我还没能进入TensorFlow的决策层,最终得到的结论是1. 让我们成立一个虚拟组专门做这个项目。2. 之前的Demo全部推倒重新做,TensorFlow 2.0作为最重要Feature 发布,默认使用Imperative Mode (后改名叫Eager Mode,中文常常叫动态图)。我则作为团队的一员在项目中贡献来一些代码。

后来Brain来了位新的大神,Chris Lattner,在编程语言和编译领域研究的同学估计很多认识他。他提出来希望用Swift来实现Deep Learning Model的Progamming,也就是后来的Swift for TensorFlow。理由大概是Python是个动态的语言,很难静态编译优化。后来我和他深入讨论来几次,从技术上非常赞同他的观点,但是也明确的表示Swift for TensorFlow是一条很难走的路。用Python并不是因为Python语言多么好,而是因为很多人用Python。和Chris的一些交流中我对编译过程中的IR和Pass有了更深的了解,对后来在PaddlePaddle中的一些工作产生了不少的影响。
一个插曲是某位TensorFlow团队的资深专家有次悄悄和我说:Python is such a bad language。这句话我品味了好久,不过和他一样没有勇气大声说出来。。。
当时动态图的项目还延展出两个比较有趣的项目。有两个其他团队的哥们想对Python做语法分析,进而编译control flow。我很委婉的表示这个方案做成通用解决方案的可能性不太大,但是这个项目依然被很执着的做了很长一段时间,并且进行了开源,但是这个项目也就慢慢寿终正寝了。另一个很酷的项目是完全用numpy来构造一个deep learning model。通过隐式的tape来完成自动的求导,后来项目好像逐渐演化成来JAX项目。
API
后面我逐渐转到了TensorFlow做开发。记得2017年还发生了一件印象深刻的事情,当TensorFlow收获海量用户时,网上一篇“TensorFlow Sucks"火了。虽然那篇文章很多观点我不能苟同,许多想法比较肤浅。但是,有一点不能否认,TensorFlow API是比较让人蛋疼的。1. 同一个功能往往几套重复的API支持。2. API经常变动,而且经常发生不向后兼容的问题。3. API的易用性不高。
为什么会发生这个问题呢?可能要从Google这个公司的工程师文化说起。Google是非常鼓励自由创新和跨团队贡献的。经常会有人给另一个团队贡献代码,并以此作为有影响力的论据参与晋升。所以在早期TensorFlow还不是特别完善的时候,经常有外部的团队给TensorFlow贡献代码,其中就包含了API。另外,在Google内部的统一代码仓库下,放出去的API是可以很容易的升级修改的,很多时候只需要grep和replace一下就行。但是github上放出去的API完全不一样,Google的员工不能去修改百度,阿里,腾讯内部的TensorFlow使用代码。对此TensorFlow团队早期的确没有非常有效的方案,后来才出现了API Committee对public API做统一的把关和规划。
在我做视觉的时候,和Google内部一个视觉团队有过很多合作,其中一个是slim API。这个视觉团队非常的强,当年还拿了CoCo的冠军。随着他们模型的推广流行,他们的tf.slim API也被广为流传。slim API的arg_scope使用了python context manager的特性。熟悉早期TensorFlow的人知道还有tf.variable_scope, tf.name_scope, tf.op_name_scope等等。with xxx_scope一层套一层,复杂的时候代码几乎没有什么可读性。另外就是各种global collection,什么global variable, trainable variable, local variable。这在传统的编程语言课里,全局变量这种东西可能是拿来当反面教材的。然而,算法人员的视角是不一样的,with xxx_scope和global collection能减少他们的代码量。虽然我们知道合理的程序设计方法也可以做到,但是算法专家估计需要把时间用来读paper,不太愿意研究这些程序设计的问题。
记得在早期内部还有两个流派的争论:面向对象和面向过程的API设计。
基于我教育历史的洗脑,感觉这个是不需要争论的问题。Keras的Layer class和Pytorch的Module class这些面向对象的接口设计无疑是非常优雅的。然而,其实当时的确发生了非常激烈的争论。一些functional API的作者认为functional的调用非常节省代码量:一个函数就可以解决的问题,为什么需要先构造一个对象,然后再call一下?
在TensorFlow动态图能力开发的早期,我们也反复讨论了2.0里面接口的设计方案。作为炮灰的我又接下了写Demo的工作。
闭关两周后,我给出了一个方案:1. 复用Keras的Layer接口。2. 但是不复用Keras的Network,Topology等其他更高层的复杂接口。
原因主要又两点:1. Layer是非常简洁优雅的,Layer可以套Layer,整个网络就是一个大Layer。Layer抽象成construction和execution两阶段也非常自然。2. Keras有很多历史上为了极简设计的高层接口。我个人经验觉得很难满足用户灵活的需求,并不需要官方提供。而且这样可能会导致TensorFlow API层过度复杂。
后来方案被采纳了一半,大佬们希望能够更多的复用Keras接口。其实没有完美的API,只有最适合某类人群的API。有个小插曲,当时Keras的作者François也在Google Brain。为了在TensorFlow 2.0的动态图和静态图同时使用Keras的接口,不得不在Keras API内做很多改造。通常François在Review代码时都非常的不情愿,但是最后又往往妥协。很多时候,特别是技术方面,真相可能在少数不被大多数人理解的人手上,需要时间来发现。

TPU
感觉互联网公司那几年,真正把AI芯片做得成熟且广泛可用的,只有Google一家。TPU一直都是Google Brain和TensorFlow团队关注的重点。原因可能是Jeff老是提起这件事,甚至一度在TensorFlow搞GPU优化是件很没前途的事情。
TPU有个比较特别的地方,在于bfloat16的类型。如今bfloat16,还有英伟达最新GPU上的TF32都已经被广为了解了。在当时还是个不小的创新。
bfloat16的原理非常简单,就是把float32的后16bit全部截掉。和IEEE的float16相比,bfloat16的mantissa bits会少一些,但是exponential bits会多一些。保留更多的exponential bits有利于gradients很接近0时不会消失,保证bfloat16训练时能够更好的保留模型的效果。而传统基于float16训练时,往往需要做loss scaling等调试才能达到类似的效果。因此bfloat16能让AI芯片更快的运算,同时又确保收敛效果通常不会有损失。
为了在TensorFlow上全面的支持bfloat16,我当时花了不少的功夫。虽然之前有基于bfloat16通信的方案,但是要在所有地方都无缝打通bfloat16,还有非常多的工作要做。比如eigen和numpy都不支持bfloat16这种特殊的东西。幸好他们都可以扩展数据类型(就是文档太少了)。然后还要修复成百上千个fail掉的unit tests来证明bfloat16可以在python层完备的使用。
TPU是一个非常高难度,跨团队,跨技术栈的复杂工程。据说Google有位非常优秀的工程师,为了在TPU上支持depthwise convolution一个TPU kernel,花掉了半年的时间。
其实这一点也不夸张,除了底层的硬件设计,单是将tensorflow graph编译成硬件binary的XLA项目早期就至少卷入几十人。从HLO到底层的target-specific code generation,几乎又重写了一遍TensorFlow C++层,远比之前的解释型执行器复杂。
TPU的训练在底层跑通后,我基于底层接口的基础上完成Python层的支撑API,然后去实现几个模型。当时碰到了好几个难题,有些在几周时间内解决了,有些持续到我不再团队后好些年。这里举几个例子。
当时一个TPU Pod(好像是512个chips)算得太快了,即使是很复杂模型的计算也会卡在数据的IO和预处理上。后来搞了个分布式的data processing,通过多个CPU机器来同时去处理数据,才能喂饱TPU。 早器的TPU API易用性比较弱。通常一个model需要在TPU上train几百步然后再返回python层,否则TPU的性能会飞快的退化。这对于算法人员是很不友好的,这意味着debug能力的缺失,以及大量复杂模型无法实现。记得当年OKR被迫降低为支持常见的CV模型。 TPU如何支持动态图。记得我当时迫于TPU的约束,做了个所谓的JIT的能力。就是Estimator先在CPU或者GPU上迭代N步,完成模型的初步调试,然后再自动的deploy到TPU上。从算法人员角度,既满足单步调试的能力,又能在主要training过程用上TPU。
团队
Google Brain是个很神奇的团队,比较不客气的说,在2015年后的几年间包揽了全世界在深度学习领域一半以上的关键技术突破,比如TPU,TensorFlow, Transformer, BERT, Neural Machine Translation, Inception, Neural Architecture Search, GAN,Adverserial Training, Bidrectional RNN等等。这里不只有深度学习领域的图灵奖获得者,还有编程语言、编译器、计算机体系结构、分布式系统的顶级专家,甚至还有生物,物理学专家。Jeff将这些人放在一起后,发生了神奇的化学反应,加快了技术改变世界的步伐。
PaddlePaddle 飞桨

Paddle其实诞生时间比较早,据说是大约13~14年的时候徐伟老师的作品。后来据说Andrew Ng觉得Paddle叫一次不过瘾,就改名成了PaddlePaddle。Paddle和那个年代的框架Caffe有类似的问题,灵活性不够。很多地方用C++写成比较粗粒度的Layer,无法通过Python等简单的编程语言完成模型的快速构造。
后来17年下半年,团队开始完全从新写一个框架,但是继承了Paddle的名字。2017年底的时候,Paddle国内的团队找到了我,邀请我担任Paddle国内研发团队的负责人。抱着打造国产第一框架的理想,我接受了邀请,一个月后就在北京入职了。
早期设计
加入团队的时候,新的Paddle还是一个比较早期的原型系统,里面有一些设计已经被开发了出来。我发现其中有些设计理念和TensorFlow有明显的差异,但是实现的时候却又模仿了TensorFlow。
仿编程语言
设计者希望设计一种编程语言来完成深度学习模型的构建(有点类似Julia等把深度学习模型的特性嵌入到了编程语言中)。然而在实现上,我发现其实和TensorFlow比较类似。都是通过Python去声明一个静态模型结构,然后把模型结构交给执行器进行解释执行。并没有发明一种新的深度学习编程语言。
这块我基本没有对设计进行调整。本质上和TensorFlow早期静态图的没有区别。但是在细节上,TF基于Graph的模型可以通过feed/fetch选择性的执行任意一部分子图,更加灵活。Paddle中与Graph对应的是Program。Program就像正常程序一样,只能从头到尾完整的执行,无法选择性的执行。因此Paddle在这块相对简化了一些,但是可以通过在Python层构造多个Program的方式补全这部分灵活性的缺失,总体来说表达能力是足够的。
Transpiler
Transpiler是对Program进行直接改写,进而可以让模型能够被分布式运行,或者进行优化。初衷是比较好的,可以降低算法人员的使用难度。然而在实现上,最开始是在Python层直接对Program结构进行改写。后来我从新设计了IR+Pass的Compiler体系,通过一种更系统性的方式做了实现。
LoDTensor
可能是因为团队的NLP和搜索背景比较强,对于变长序列的重视程度很高。Paddle的底层数据是LoDTensor,而不是类似其他框架Tensor。LoDTensor相当于把变长序列信息耦合进了Tensor里面。这可能导致比较多的问题,比如很多Operator是完全序列无关的,根本无法处理序列信息在输入Tensor和输出Tensor的关系,进而比较随机的处理,给框架的健壮性埋下隐患。虽然我一直想推动序列信息和Tensor的解耦合,但是因为种种原因,没有彻底的完成这个重构的目标,希望后面能改掉。
性能
18年初的时候,Paddle还是个原型系统。由于OKR目标,团队已经开始初步接入一些业务场景。其实一个比较大的痛点就是性能太差。单机单卡速度非常慢,单机4卡加速比只有1.x。但是性能问题的定位却非常困难。我花了些时间写了些profile的工具,比如timeline。一些明显的性能问题可以被快速的定位出来并修复。
但是单机多卡的速度还是非常慢,timeline分析后发现其中有个ParallelOp,存在大量的Barrier。最后改写成了ParallelExecutor,把Program复制了N份部署在多张卡上,在其中插入AllReduce通信算子,然后这N倍的算子基于图依赖关系,不断把ready的算子扔进线程池执行。即使这样,我们也发现在多卡的性能上,不同模型需要使用不同的线程调度策略来达到最优。很难有一种完美的one-fits-all的方案。后面我们再聊如何通过IR+Pass的方法插件化的支持不同的算子调度策略。
分布式的训练也碰到不少的问题。一开始使用grpc,花了挺大的功夫做并行请求,然后又切成了brpc,在RDMA等方面做了不少的优化。分布式训练的性能逐步得到了提升。另外为了做到自动化分布式部署,前面提到的Transpiler随着场景的增加,Python代码也变得越来越复杂。

模型推理在公司内碰到来非常强劲的对手。Anakin的GPU推理速度的确很快,让我吃惊的是他们竟然是用SASS汇编完成大量基础算子的开发,针对Pascal架构做了异常极致的优化,甚至在某些场景远超TensorRT。我一直主张训练和推理要尽量用一样的框架,并不需要一个单独的推理框架来解决性能问题。使用不同的框架做推理会造成很多意外的精度问题和人工开销。
因为推理性能的问题,我们和兄弟团队发生来旷日持久竞赛,作为狗头军事,我充分发挥来团队在CPU这块的技术积累、以及和Intel外援的良好关系,在CPU推理场景常常略胜一筹。在GPU方面苦于对手无底线使用汇编,和我方战线太多、人员不够,只能战略性放弃了部分头部模型,通过支持子图扩展TensorRT引擎的方式,利用Nvidia的技术优势在许多个通用场景下展开进攻。现在回想起来真实一段有趣的经历。
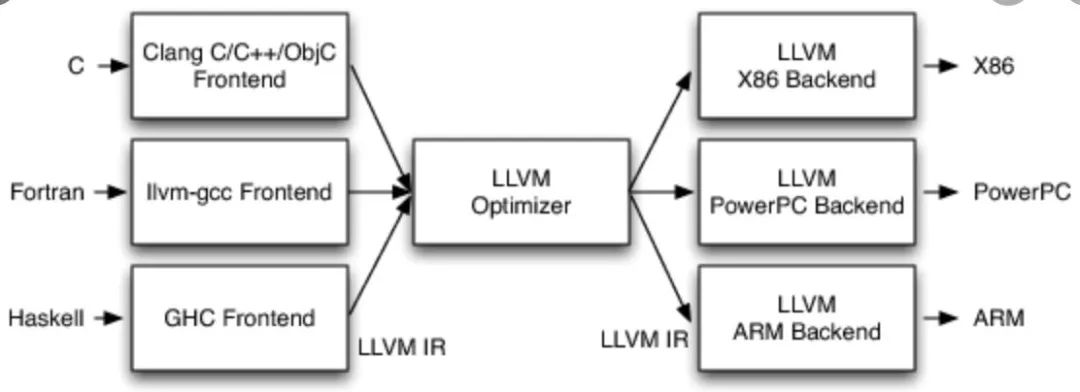
Imtermediate Representation&Pass
Imtermediate Representation+Pass的模式主要是从LLVM的架构上借鉴来的。在编译器上主要是用来解决把M个编程语言中任意一个编译到N个硬件设备中任意一个执行的问题。简单的解决方案是为每个编程语言和硬件单独写一个编译器。这需要M*N个编译器。显然这对于复杂的编译器开发来说,是非常高成本的。
Intermediate Representation是架构设计中抽象能力的典型体现。不同编程语言的层次不一样,或者仅仅是单纯的支持的功能有些差异。但是,这些编程语言终归需要在某种硬件指令集上执行。所以在编译的过程中,他们会在某个抽象层次上形成共性的表达。而IR+Pass的方法很好的利用了这一点。其基本思想是通过多层Pass (编译改写过程),逐渐的把不同语言的表达方式在某个层次上改写成统一的IR的表达方式。在这个过程中,表达方式逐渐接近底层的硬件。而IR和Pass可以很好的被复用,极大的降低了研发的成本。
深度学习框架也有着非常类似的需求。
用户希望通过高层语言描述模型的执行逻辑,甚至是仅仅声明模型的结构,而不去关心模型如何在硬件上完成训练或者推理。 深度学习框架需要解决模型在多种硬件上高效执行的问题,其中包括协同多个CPU、GPU、甚至大规模分布式集群进行工作的问题。也包括优化内存、显存开销、提高执行速度的问题。
更具体的。前文说到需要能够自动的将用户声明的模型Program自动的在多张显卡上并行计算、需要将Program拆分到多个机器上进行分布式计算、还需要修改执行图来进行算子融合和显存优化。
Paddle在一开始零散的开展了上面描述的工作,在分布式、多卡并行、推理加速、甚至是模型的压缩量化上各自进行模型的改写。这个过程非常容易产生重复性的工作,也很难统一设计模式,让团队不同的研发快速理解这些代码。
意思到这些问题后,我写了一个Single Static Assignment(SSA)的Graph,然后把Program通过第一个基础Pass改写成了SSA Graph。然后又写了第二个Pass把SSA Graph改写成了可以多卡并行的SSA Graph。
后面的事情就应该可以以此类推了。比如推理加速可以在这个基础上实现OpFusionPass, InferenceMemoryOptimizationPass, PruningPass等等,进而达到执行时推理加速的目的。分布式训练时则可以有DistributedTransPass。量化压缩则可以有ConvertToInt8Pass等等。这一套东西基本解决了上层Program声明到底层执行器的Compiler问题。
这个过程中的确碰到了不少的阻力。比如分布式早期通过Python完成了这个逻辑,需要迁移到C++层。压缩量化的研发更喜欢写Python,而IR&Pass是基于C++的。不同Pass间顺序依赖和Debug等。
全套深度学习框架工具
TensorFlow Everywhere原本是TensorFlow团队时的一个口号,意思是TensorFlow需要支持深度学习模型在任意的场景下运行,进而达到AI Everywhere的目标。可以说深度学习框架希望成为AI的“操作系统”,就像鱼离不开水、App离不开iOS/Android一样。
Paddle作为全面对标TensorFlow的国产深度学习框架,自然也希望提供全套的解决方案。在早期的时候,Paddle和公司其他团队合作了PaddleMobile,提供了移动端的推理能力。后来又开展了Paddle.js,支持在H5、Web等场景的推理能力。为了在toB,在Linux的基础上又新增了Windows的支持。为了支持无人车等设备、又支持了在更多不同设备上运行。
举个PaddleMobile的例子。深度学习框架想再移动设备上部署面临这比较多的挑战。手机的空间和算力都比服务器小很多,而模型最开始在服务器训练好后体积相对较大,需要从很多角度下手。1. 使用较小的模型结构。2. 通过量化,压缩等手段削减模型体积。
另外移动段深度学习框架是通常基于ARM CPU,GPU则有Mali GPU, adreno GPU等等。为了最求比较极致性能,常常需要使用汇编语言。有个同学写到后面几乎怀疑人生,感觉自己大学学的东西不太对。为了不显著增加APP的体积,框架编译后的体积需要在KB~几MB的级别,因此需要基于部署的模型结构本身用到的算子进行选择性编译。极端的时候甚至需要是通过C++ Code Gen的方法直接生成前向计算必须的代码,而不是通过一个通用的解释器。
回顾
随着项目的复杂化,很多棘手的问题逐渐从深度学习的领域技术问题转变成了软件工程开发和团队管理分工的问题。随着团队的不断变化,自己有时候是作为一个leader的角色在处理问题,有的时候又是以一个independent contributor的角色在参与讨论。很庆幸自己经历过这么一段,有些问题在亲身经历后才能想得明白,想得开。时代有时候会把你推向风口浪尖,让你带船队扬帆起航,在更多的时候是在不断的妥协与摸索中寻找前进的方向。
无量

无量是腾讯PCG建设的一个深度学习框架,主要希望解决大规模推荐场景下的训练和推理问题。深度学习在推荐场景的应用和CV、NLP、语音有些不一样。
业务会持续的产生用户的行为数据。当用户规模达到数千万或者上亿时就会产生海量的训练数据,比如用户的画像,用户的点击,点赞,转发行为,还有Context等等。 这些数据是高度稀疏的,通常会编码成ID类的特征进而通过Embedding的方式进入模型训练。随着业务规模的提升和特征工程日渐复杂,比如累计用户数,商品,内容增加,以及特征交叉的使用,Embedding参数的体积可以达到GB,甚至TB级。 推荐场景是实时动态变化的,新用户,内容,热点不断产生。用户的兴趣,意图逐渐变化,因此模型需要持续不断的适应这些变化,时刻保持最好的状态。

调整
19年中这个项目时大概有2~3人。团队希望开发一个新的版本,基于TensorFlow进行扩展加强,使得无量可以复用TensorFlow已有的能力,并且能够支持推荐场景下的特殊需求。无量一开始采用的是基于参数服务器的架构。TensorFlow被复用来提供Python API以及完成基础算子的执行。而参数服务器,分布式通信等方面则是自己开发,没有复用TensorFlow。
这个选择在团队当时的情况下是比较合理的。如果选择另一种方向,基于TensorFlow底层进行改造,研发难度会比较大,而且很可能与社区版TensorFlow走向不同的方向,进而导致TensorFlow版本难以升级。而把TensorFlow作为一个本地执行的lib则可以在外围开发,不需要了解TensorFlow内部的复杂逻辑,也可以复用一些其他开源组件,比如pslib。
早期在软件开发的流程上相对比较欠缺。为了保障工程的推进,我先帮忙做了些基础工作,比如加上了第一个自动化测试和持续集成,对一些过度封装和奇怪的代码做了重构和简化。
另外,在接口层也做了一些调整。原来框架开始执行后就进入C++执行器,无法从python层提供或者返回任何执行结果,也无法在python层执行逻辑进行插件化的扩展。为了满足预期用户将来需要进行调试的需求,我模拟tf.Session和tf.Estimator对执行层的接口做了重构。这样用户可以通过feed/fetch的方式单步调试执行的过程。也可以通过Hook的方式在执行前后扩展任意的逻辑,提高框架的适用场景。
另外一个问题是python层基本完全是全局变量,很难进行多模型的封装。像TensorFlow有Graph实例或者Paddle有Program实例。因为python层需要重构的量比较大,我暂时先加入了Context的封装,勉强将各种状态和配置封装在了Context下。考虑到短期可能不会有更复杂的需求,暂时没有把这件事做完。
reader那块也做了一些重构。最开始那块的线程模型异常复杂,一部分是因为分布式文件系统等基础设施无法提供比较好的SDK,导致许多逻辑不得不在深度学习框架里面,比如文件的本地缓存。考虑到特征加工的逻辑比较复杂,以及一些老的TensorFlow用户可能习惯于tf.Example和tf.feature_column等基础算子库,我在reader层引入了基于TensorFlow的tf.dataset。不过后来发现用户似乎更关心性能问题,喜欢自定义C++ lib的方式来解决特征处理的问题。
API设计是个老大难的问题。TensorFlow,Paddle,无量都没能幸免。在一个多人协同的团队里,每个研发更多还是关注每个独立功能是否完成开发,而功能的接口往往需要考虑到整体的API设计风格,易用性,兼容性等许多因素,常常在高速迭代的过程中被忽略掉。不幸的是API常常不能像内部实现一样后期优化。当API被放给用户使用后,后续的修改往往会破坏用户代码的正确性。很多时候只能自己评审一下。
升级
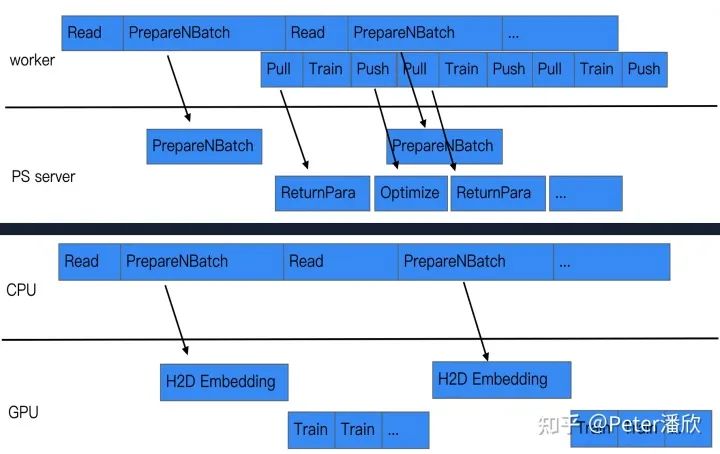
无量经过一年基础能力的打磨,逐渐的成为来整个事业群统一的大规模推荐模型训练和推理框架,支撑数十个业务场景,每天都能生产数千个增量和全量的模型。简单的完成功能已经不能满足业务和团队发展的需求,需要在技术上更加前沿。
数据处理
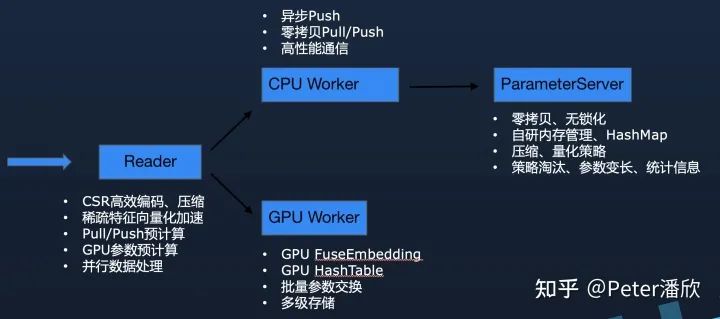
数据格式上要从原来的明文转到更高效的二进制。另外基于CSR编码的稀疏数据可以进一步的减少数据处理时的拷贝等额外开销。
流水线
尽量挖掘训练中可以并行的地方,通过流水线的方式提高并发度,进而提高训练的速度。比如在数据读取的过程中,就可以提前按照参数服务器的规模对数据进行预切分,并告知参数服务器需要提前准备哪些参数。这样当pull/push的时候能够更快的完成计算,进而提高每个minibatch的速度。
同样,当使用GPU训练时,也可以在数据IO的并行过程中,预计算未来需要用的的Embedding参数。这样GPU训练下一轮的数据时,需要用到的Embedding已经提前被计算好,可以直接开始训练,减少来等待的时间。
定制化参数服务器
由于无量解决的一个关键问题是推荐模型的海量参数问题,因此参数服务器必须是高度优化过的。并且应该合理的将推荐模型的领域知识引入到设计中,通过特殊的策略进一步产生差异化的优势。
定制化的线程模型,内存管理和HashMap。由于参数是被切分归属到不同线程上,所以可以通过无锁化的把每次pull/push的参数处理好。另外由于海量参数消耗较大硬件成本,内存空间都需要通过定制化的内存池来管理。否则很可能有大量的空间碎片在默认内存库中无法及时归还给操作系统。另外也有无法精细化控制内存清理机制,导致内存OOM或者浪费。定制化的内存管理可以解决这些问题,甚至通过特殊的内存淘汰策略,在不损害模型效果的基础上进一步降低内存的开销。高性能HashMap则是需要解决Embedding快速的增删改查的问题。
Embedding向量的管理也是有非常多可以改进的地方。1. 动态的改变Embeding向量的长度来支持模型的压缩,提高模型效果。2. 扩展Embedding的元数据来记录热度,点击展现等统计值,有助于提高训练推理时高级分布式架构的Cache命中率,已经模型的训练效果。3. 模型的恢复和导出机制在大规模Embedding场景对于Serving时能够实时加载模型更新重要。另外还需要考虑到任务失败重启后资源伸缩等问题。
GPU训练
传统PS架构的训练模式下,由于单台机器的计算能力有限,需要几十甚至上百个实例进行分布式训练。但是这样会导致大量的计算被用在来无效的开销上。比如稀疏特征在网络通信两边的处理。这种额外开销甚至经常超过有效计算。
GPU和相应的高速网络链接可以解决这一问题。单台8卡机器通过NVLink连接起来,速度甚至可以超过几十台物理机,有更高的性价比。但是由于几百GB,甚至TB级的参数问题,还有Embedding的GPU计算问题,导致GPU一直都没有被广泛的用起来。
然而实验发现其实稀疏特征存在显著的Power-law分布,少部分Hot特征使用远多于其他大量不Hot的特征。因此,通过在数据处理时统计特征,然后批量将将来新需要的Embedding换入GPU,就可以让GPU长时间的进行连续训练,而不需要频繁的和CPU内存交换参数。
GPU预测
随着推荐模型复杂度提高,引入传统CV,NLP的一些结构需要消耗更多的计算。CPU往往很难在有效的时间延迟下(几十毫秒)完成大量候(几百上千)选集在复杂推荐模型的推理。而GPU则成为了一个潜在的解决方案。
同样,GPU推理也需要解决显存远小于Embedding参数的问题。通过在训练时预先计算Hot Embedding,然后加载如推理GPU,可以一定程度的缓解这个问题。在推理时仅有少部分的Embedding没有在GPU显存中缓存,需要通过CPU内存拷贝进入GPU。
而通过模型的量化和压缩能进一步减少Embedding参数的规模。实验表明当大部分Embedding参数的值控制为0时,模型依然能够表现出原来的效果,甚至略优。
总结

深度学习算法的发展和深度学习框架的发展是相辅相成,互相促进的。从2002年时Torch论文发表后,框架的技术发展相对缓慢,性能无法显著提升导致无法探索更加复杂的算法模型,或者利用更加大规模的数据集。
在2010年后逐渐出现了Caffe, Theano等框架,通过将更高性能的GPU引入,可以训练更加复杂的CNN和RNN模型,深度学习算法的发展出现来显著的加速。
到了2014~2017年几年间,TensorFlow的出现让用户可以通过简单的Python语言将细粒度的算子组装各种模型结构。并且模型可以简单的被分布式训练,然后自动化部署在服务器,手机,摄像头等各种设备上。而Pytorch的动态图用法满足了研究人员对易用性和灵活性更高的要求,进一步推进算法研究。
国内的深度学习框架技术在这股浪潮中也紧跟这世界的步伐。Paddle在14年左右产生,在国内积累了一定的用户,在当时基本能比肩其他的框架。虽然在TensorFlow和Pytorch等更先进的框架出现后,国内错过了宝贵的几年技术升级的窗口以及社区生态培育时机,但是我们看到从18年到20年间,新版的PaddlePaddle,OneFlow, MindSpore等深度学习框架陆续开源,技术上逐渐赶了上来。
推荐场景在电商,视频,资讯等众多头部互联网公司的火爆导致推荐系统对AI硬件的消耗在互联网公司超过了传统NLP,CV,语音等应用的总和。许多公司开始针对推荐场景(以及广告,搜索)的特殊需求对深度学习框架进行定制优化。百度的abacus是比较早期的框架,和其他早期框架一样,在易用性和灵活性上较弱。无量,XDL等框架则进行了改进,兼顾了社区兼容性,算法易用性和系统的性能等纬度。
深度学习的框架的触角其实远不止我们常见到的。随着AI技术的推广,Web、H5、嵌入式设备、手机等场景下都有许多优秀的深度学习框架产生,如PaddleMobile, TFLite,tensorflow.js等等。
深度学习框架的技术也逐渐从更多纬度开始拓展。ONNX被提出来作为统一的模型格式,虽然离目标有很长的距离和问题需要解决。但是从它的流行我们能看到社区对于框架间互通的渴望。随着摩尔定律难以维持,框架开始更多的从新的硬件和异构计算领域寻求突破。为了支持海量的算子在CPU、FPGA、GPU、TPU、NPU、Cerebras等众多AI芯片上运行,TVM、XLA等借鉴编译技术几十年来的积累,在更加艰巨的道路上进行来持续的探索,经常能传来新进展的好消息。深度学习框架也不再仅应用于深度学习,还在科学计算,物理化学等领域发光发热。
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的,文章版权归原作者所有。如有不妥,请联系删除。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!