
10张图详解MMU那些事儿
来源:嵌入式客栈 | 逸珺
最近在重新看这部分知识点,内存管理和进程调度应该是Linux下最核心的两个东西,不管你做得多牛逼了,这两点拿出来讨论,总是会让人眼前一亮,或者是可以讨论很久很久,这篇文章,读完后可能也可以让大家耳目一新。欢迎有问题的同学留言一起学习。祝大家周末快乐~
[导读]
本文从内存管理的发展历程角度层层递进,介绍 MMU 的诞生背景,工作机制。而忽略了具体处理器的具体实现细节,将 MMU 的工作原理从概念上比较清晰的梳理了一遍。
#MMU 诞生之前:
在传统的批处理系统如 DOS 系统,应用程序与操作系统在内存中的布局大致如下图:
应用程序直接访问物理内存,操作系统占用一部分内存区。 操作系统的职责是“加载”应用程序,“运行”或“卸载”应用程序。
如果我们一直是单任务处理,则不会有任何问题,也或者应用程序所需的内存总是非常小,则这种架构是不会有任何问题的。然而随着计算机科学技术的发展,所需解决的问题越来越复杂,单任务批处理已不能满足需求了。而且应用程序需要的内存量也越来越大。而且伴随着多任务同时处理的需求,这种技术架构已然不能满足需求了,早先的多任务处理系统是怎么运作的呢?
程序员将应用程序分段加载执行,但是分段是一个苦力活。而且死板枯燥。此时聪明的计算机科学家想到了好办法,提出来虚拟内存的思想。程序所需的内存可以远超物理内存的大小,将当前需要执行的留在内存中,而不需要执行的部分留在磁盘中,这样同时就可以满足多应用程序同时驻留内存能并发执行了。
从总体上而言,需要实现哪些大的策略呢?
所有的应用程序能同时驻留内存,并由操作系统调度并发执行。需要提供机制管理 I/O 重叠,CPU 资源竞争访问。 虚实内存映射及交换管理,可以将真实的物理内存,有可变或固定的分区,分页或者分段与虚拟内存建立交换映射关系,并且有效的管理这种映射,实现交换管理。
这样,衍生而来的一些实现上的更具体的需求:
竞争访问保护管理需求:需要严格的访问保护,动态管理哪些内存页/段或区,为哪些应用程序所用。这属于资源的竞争访问管理需求。 高效的翻译转换管理需求:需要实现快速高效的映射翻译转换,否则系统的运行效率将会低下。 高效的虚实内存交换需求:需要在实际的虚拟内存与物理内存进行内存页/段交换过程中快速高效。
总之,在这样的背景下,MMU 应运而生,也由此可见,任何一项技术的发展壮大,都必然是需求驱动的。这是技术本身发展的客观规律。
#内存管理的好处
为编程提供方便统一的内存空间抽象,在应用开发而言,好似都完全拥有各自独立的用户内存空间的访问权限,这样隐藏了底层实现细节,提供了统一可移植用户抽象。 以最小的开销换取性能最大化,利用 MMU 管理内存肯定不如直接对内存进行访问效率高,为什么需要用这样的机制进行内存管理,是因为并发进程每个进程都拥有完整且相互独立的内存空间。那么实际上内存是昂贵的,即使内存成本远比从前便宜,但是应用进程对内存的寻求仍然无法在实际硬件中,设计足够大的内存实现直接访问,即使能满足,CPU 利用地址总线直接寻址空间也是有限的。
#内存管理实现总体策略
从操作系统角度来看,虚拟内存的基本抽象由操作系统实现完成:
处理器内存空间不必与真实的所连接的物理内存空间一致。 当应用程序请求访问内存时,操作系统将虚拟内存地址翻译成物理内存地址,然后完成访问。
从应用程序角度来看,应用程序(往往是进程)所使用的地址是虚拟内存地址,从概念上就如下示意图所示,MMU 在操作系统的控制下负责将虚拟内存实际翻译成物理内存。

从而这样的机制,虚拟内存使得应用程序不用将其全部内容都一次性驻留在内存中执行:
节省内存:很多应用程序都不必让其全部内容一次性加载驻留在内存中,那么这样的好处是显而易见,即使硬件系统配置多大的内存,内存在系统中仍然是最为珍贵的资源。所以这种技术节省内存的好处是显而易见的。 使得应用程序以及操作系统更具灵活性。 操作系统根据应用程序的动态运行时行为灵活的分配内存给应用程序。 使得应用程序可以使用比实际物理内存多或少的内存空间。
#MMU 以及 TLB
MMU(Memory Management Unit)内存管理单元:
一种硬件电路单元负责将虚拟内存地址转换为物理内存地址 所有的内存访问都将通过 MMU 进行转换,除非没有使能 MMU。
TLB(Translation Lookaside Buffer)转译后备缓冲器: 本质上是 MMU 用于虚拟地址到物理地址转换表的缓存
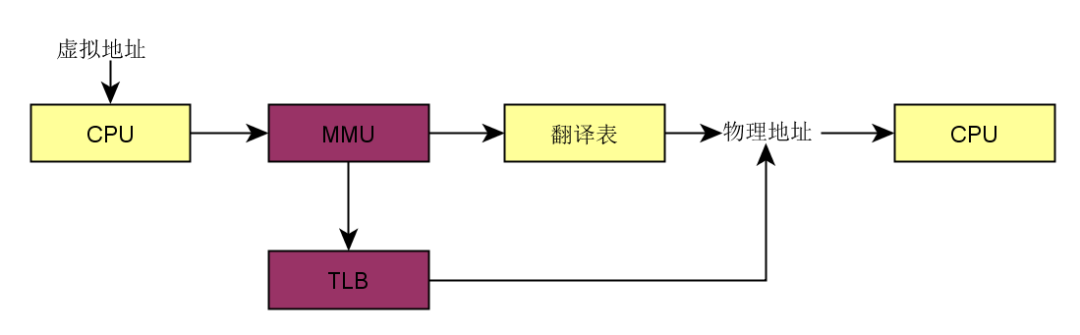
这样一种架构,其最终运行时目的,是为主要满足下面这样运行需求:
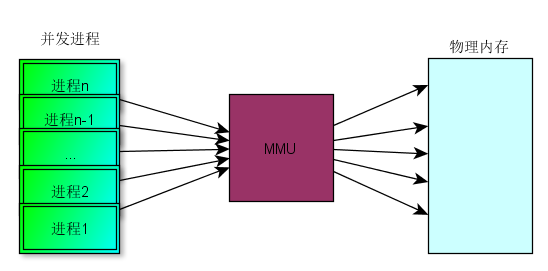
多进程并发同时并发运行在实际物理内存空间中,而 MMU 充当了一个至关重要的虚拟内存到物理内存的桥梁作用。
那么,这种框架具体从高层级的概念上是怎么做到的呢?事实上,是将物理内存采用分片管理的策略来实现的,那么,从实现的角度将有两种可选的策略:
固定大小分区机制
可变大小分区机制
#固定大小区片机制
通过这样一种概念上的策略,将物理内存分成固定等大小的片:
每一个片提供一个基地址 实际寻址,物理地址=某片基址+虚拟地址 片基址由操作系统在进程动态运行时动态加载

这种策略实现,其优势在于简易,切换快速。但是该策略也带来明显的劣势:
内部碎片:一个进程不使用的分区中的内存对其他进程而言无法使用 一种分区大小并不能满足所有应用进程所需。
#可变大小分区机制
内存被划分为可变大小的区块进行映射交换管理:
需要提供基址以及可变大小边界,可变大小边界用于越界保护。 实际寻址,物理地址=某片基址+虚拟地址

那么这种策略其优势在于没有内部内存碎片,分配刚好够进程所需的大小。但是劣势在于,在加载和卸载的动态过程中会产生碎片。
#分页机制
分页机制采用在虚拟内存空间以及物理内存空间都使用固定大小的分区进行映射管理。

从应用程序(进程)角度看内存是连续的 0-N 的分页的虚拟地址空间。 物理内存角度看,内存页是分散在整个物理存储中 这种映射关系对应用程序不可见,隐藏了实现细节。
分页机制是如何寻址的呢?这里介绍的设计理念,具体的处理器实现各有细微差异:
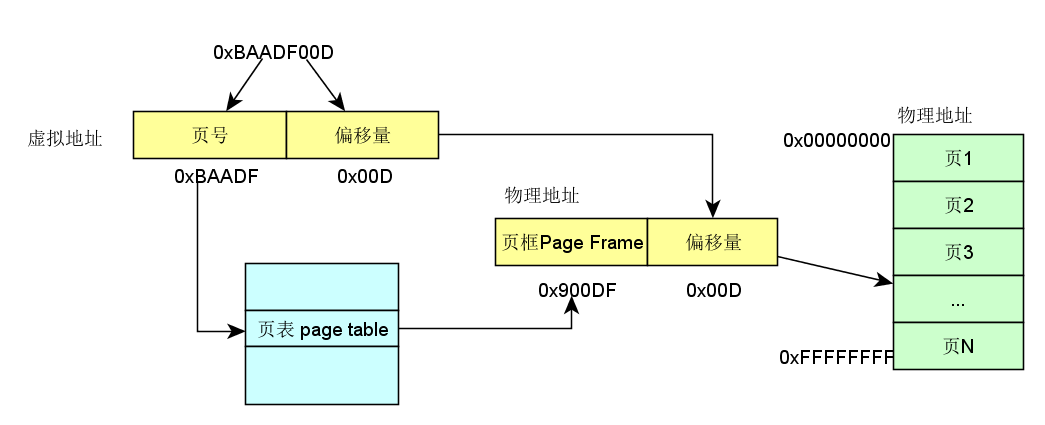
虚拟地址包含了两个部分:虚拟页序号 VPN(virtual paging number)以及偏移量 虚拟页序号 VPN是页表(Page Table)的索引 页表(Page Table)维护了页框号(Page frame number PFN) 物理地址由PFN::Offset进行解析。
举个栗子,如下图所示:

还没有查到具体的物理地址,憋急,再看一下完整解析示例:
#如何管理页表
对于 32 位地址空间而言,假定 4K 为分页大小,则页表的大小为 100MB,这对于页表的查询而言是一个很大的开销。那么如何减小这种开销呢?实际运行过程中发现,事实上只需要映射实际使用的很小一部分地址空间。那么在一级页机制基础上,延伸出多级页表机制。
以二级分页机制为例:

单级页表已然有不小的开销,查询页表以及取数,而二级分页机制,因为需要查询两次页表,则将这种开销再加一倍。那么如何提高效率呢?其实前面提到一个概念一直还没有深入描述 TLB,将翻译工作由硬件缓存 cache,这就是 TLB 存在的意义。
TLB 将虚拟页翻译成 PTE,这个工作可在单周期指令完成。 TLB 由硬件实现 完全关联缓存(并行查找所有条目) 缓存索引是虚拟页码 缓存内容是 PTE 则由 PTE+offset,可直接计算出物理地址
#TLB 加载
谁负责加载 TLB 呢?这里可供选择的有两种策略:
由操作系统加载,操作系统找到对应的 PTE,而后加载到 TLB。格式比较灵活。 MMU 硬件负责,由操作系统维护页表,MMU 直接访问页表,页表格式严格依赖硬件设计格式。
#总结一下
从计算机大致发展历程来了解内存管理的大致发展策略,如何衍生出 MMU,以及固定分片管理、可变分片管理等不同机制的差异,最后衍生出单级分页管理机制、多级分页管理机制、TLB 的作用。从概念上相对比较易懂的角度描述了 MMU 的诞生、机制,而忽略了处理器的具体实现细节。作为从概念上更深入的理解 MMU 的工作机理的角度,还是不失为一篇浅显易懂的文章
版权声明:本文来源网络,免费传达知识,版权归原作者所有。如涉及作品版权问题,请联系我进行删除。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
关注我的微信公众号,回复“加群”按规则加入技术交流群。
点击“阅读原文”查看更多分享,欢迎点分享、收藏、点赞、在看。