
Python生成器那些事儿
大家好,欢迎来到 Crossin的编程教室 !
生成器是Python语法中一个很常见的概念。今天我们给大家分享一篇有关生成器的文章。
读完本文你会有以下收获:
了解Python生成器的工作原理。 学会查询PEP(Python Enhancement Proposals)。让你知道python的一些设计理念。 最后会通过码农工作中一个实际的例子,来了解不同实现的好坏。
什么是生成器?
生成器(Generator)是一个非常强大的迭代器。其按照一定的算法生成一个序列。
包含yield的函数会返回一个生成器。生成器函数和普通函数看上去很像,不同的是生成器的返回值是用yield实现的。
也有一种写法是(expression for i in s if condition),注意两边是括号而不是方括号。这种写法等效于
def a_generator():
for i in s:
if condition:
yield expression
我们先实现一个简单的生成器来演示一下:
def gen():
yield 3
yield 1
yield 4
a = gen()
next(a) # output 3
next(a) # output 1
next(a) # output 4
next(a)
# Traceback (most recent call last):
# File "", line 1, in
# StopIteration
通过help(a),你会看到a是一个generator object,而且实现了__iter__和__next__,符合迭代器协议。说明函数gen返回了一个迭代器。
可以用next来进行迭代,迭代到最后会返回一个StopIteration的异常。
与普通迭代器不同的是,生成器只能迭代一次。如果我们接着上面的代码重新迭代,会发现没有任何输出。
for item in a:
print(item, end=' ')
# output: 没有任何输出。
生成器与yield关键字息息相关,我们先来了解一下yield。
yield的发展史
yield in python2.3
yield在python2.3引入。最早的功能只有一个,就是将值返回给调用方,然后停止执行函数,保存现场并且再下次调用时回复。对比普通的函数,函数在return后就退出了。中断然后恢复是yield的特异功能。
yield in python2.5
到了python2.5,yield又有了表达式的功能(详细见:https://www.python.org/dev/peps/pep-0342/)。也就是
a = yield b
需要注意的是,这个表达式其实有两部分,一部分是右侧的yield b,一部分是赋值操作=。按照运算优先级来说,要先执行yield b。因为yield的特性,返回b之后函数暂停,所以下一次yield前会执行赋值操作,那么a到底被赋予了一个什么样的值呢?
这就要解释PEP-0342为迭代器引入的一个新函数,send,在yield之后,程序暂停,然后a就等待下一次send的输入。注意,send(None)和next是等价的。如下示例:
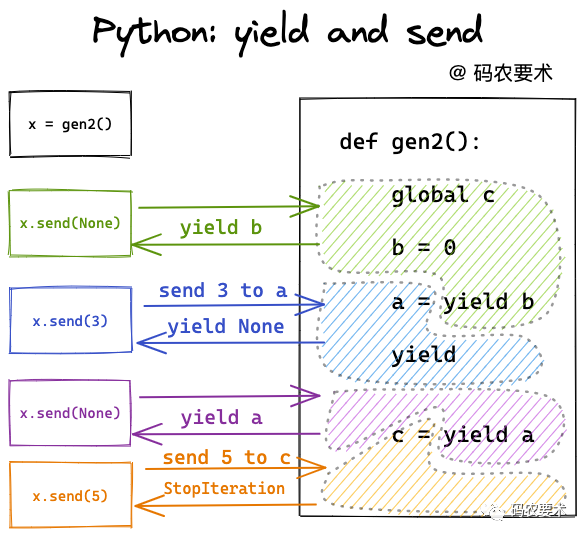
c = None
def gen2():
global c
b = 0
a = yield b
yield
c = yield a
x = gen2()
x.send(None) # output 0, a等待接受send来的值。
x.send(3) # output None, 输出前执行a=3
x.send(None) # output 3, c等待接受send来的值。
x.send(5) # output StopIteration, 同时输出前c=5
print(c) # output 5
这段代码可以用如下流程来解释,右侧带颜色的程序块之间会暂停,并等待新的send信号:
yield in python3.3
python3.3中,新加了yield from这个操作。yield from g 基本等价于 for v in g: yield v,但是内部帮忙实现了很多边界处理,比如异常等。
明白了yield的基本操作,那么生成器有什么用呢?
Python中生成器的作用
这里告诉大家一个小技巧,当你不知道python某个功能有什么用的时候,可以查一下PEP(Python Enhancement Proposals),中文叫《Python增强提
案》。这里面除了重要的通知外,还有一些新功能的描述,以及为什么要设计这个功能。
目录为:
https://www.python.org/dev/peps/
可以按关键字检索。
拿生成器来说,首次出行在PEP255《Simple Generators》(https://www.python.org/dev/peps/pep-0255/),在Motivation一栏详细描述了其设计的动机。可以看出,生成器的设计初衷是要优化生产者函数迭代+回调函数的场景。某些处理可能会使用生成器之前生产的值,会让调用者的设计变复杂。而yield的中断恢复机制让迭代和调用者都变得更加自然。基于这一功能,可以很方便的实现
协程操作。
所以说使用生成器有如下的好处:
实现协程(Coroutine),通过yield的中断恢复功能,可以实现一个线程实现多任务的调度。没有了线程切换和锁,没有了用户态和内核态的切换
,性能上会提升不少,尤其是IO场景较多的情况下。关于协程内容较多,而且有更好的方法(async/await),有时间另开一篇讲。一般情况下生成器比迭代速度要快一些。 代码可读性更高。 由于本身也是个迭代器,所以也拥有迭代器的优点:惰性计算。不需要把所有的数据加载到内存,而是即取即用。
不适合生成器的场景:
多次读取。此时生成器无法满足,可以用list(a_generator)来转换成list 随机读取。生成器没有类似 x[i]这样的下标操作。拼接字符串。 ''.join(alist)比''.join(a_generator)更快。
生成器现实中的例子
比如要读取一些网络日志,然后统计发送的字节数。格式如下:
127.0.0.1 - - [24/Feb/2008:00:08:59 -0600] "GET /ply/ply.html HTTP/1.1" 200 97238
192.168.0.1 - - [24/Feb/2008:00:08:59 -0600] "GET /favicon.ico HTTP/1.1" 404 133
最后一列是发送字节数。我们要把文件中每一行最后一列的数字累计求和。
第一种方法,硬编码直接实现。
def read_file_count_inside(filename):
total = 0
with open(filename) as wwwlog:
for line in wwwlog:
bytes_sent = line.rsplit(None, 1)[1]
if bytes_sent != '-':
total += int(bytes_sent)
return total
# User time (seconds): 13.09
# System time (seconds): 0.35
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:13.45
# Maximum resident set size (kbytes): 6880
直接实现很好,但是复用性较差。假如我换个任务,统计ip的频次。那就要修改现有的逻辑,或者重写一个类似的函数。
第二种实现,读取和处理分开。
def read_file(filename):
with open(filename) as wwwlog:
return wwwlog.readlines()
def count_bytes(line_list):
total = 0
for line in line_list:
bytes_sent = line.rsplit(None, 1)[1]
if bytes_sent != '-':
total += int(bytes_sent)
return total
# User time (seconds): 13.90
# System time (seconds): 2.87
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:16.78
# Maximum resident set size (kbytes): 2315280
第二种逻辑清晰,可扩展性也好。但是占用内存太恐怖。
第三种实现:callback函数
G_TOTAL = 0
def count_callback(line):
global G_TOTAL
bytes_sent = line.rsplit(None, 1)[1]
if bytes_sent != '-':
G_TOTAL += int(bytes_sent)
def read_file_with_callback(filename, callback_fn):
with open(filename) as wwwlog:
for line in wwwlog:
callback_fn(line)
return G_TOTAL
# User time (seconds): 15.18
# System time (seconds): 0.38
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:15.57
# Maximum resident set size (kbytes): 6880
callback代码也算清晰,但是不免保存一些现场的变量。
第四种实现:生成器
def read_file_gen(filename):
with open(filename) as wwwlog:
for line in wwwlog:
yield line
def count_gen(generator):
bytecolumn = (line.rsplit(None, 1)[1] for line in generator)
bytes_sent = (int(x) for x in bytecolumn if x != '-')
return sum(bytes_sent)
# User time (seconds): 14.92
# System time (seconds): 0.34
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:15.26
# Maximum resident set size (kbytes): 6884
生成器实现就很舒服,可以说是综合了第二第三种的优点。
第五种:走火入魔生成器
sum(int(x) for x in (line.rsplit(None, 1)[1] for line in open(filename)) if x != '-')
# User time (seconds): 14.03
# System time (seconds): 0.32
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:14.35
# Maximum resident set size (kbytes): 6916
这种方法虽然免去了很多函数调用,但是可读性并不太好,只适合简单场景。不建议使用。
第六种:实际工作中采用的方法
awk { total += $NF } END { print total } big-access-log
# User time (seconds): 10.72
# System time (seconds): 0.32
# Elapsed (wall clock) time (h:mm:ss or m:ss): 0:11.04
# Maximum resident set size (kbytes): 1348
程序员总是想用最少的代码来实现一个功能。对于文本处理来说,awk和sed可以满足绝大多数的需求,而且速度比python更快。但是python胜在跨平台,毕竟windows可没有awk。
你喜欢哪一种呢?
以上就是对Python生成器的一些介绍。如果文章对你有帮助,欢迎转发/点赞/收藏~
作者:码农要术
_往期文章推荐_