
Pandas中的这3个函数,没想到竟成了我数据处理的主力
导读
学Pandas有一年多了,用Pandas做数据分析也快一年了,常常在总结梳理一些Pandas中好用的方法。例如三个最爱函数、计数、数据透视表、索引变换、聚合统计以及时间序列等等,每一个都称得上是认知的升华、实践的结晶。今天,延承这一系列,再分享三个函数,堪称是个人日常在数据处理环节中应用频率较高的3个函数:apply、map和applymap,其中apply是主角,map和applymap为赠送。

数据处理环节无非就是各种数据清洗,除了常规的缺失值和重复值处理逻辑相对较为简单,更为复杂的其实当属异常值处理以及各种数据变换:例如类型转换、简单数值计算等等。在这一过程中,如何既能保证数据处理效率而又不失优雅,Pandas中的这几个函数堪称理想的解决方案。
为展示应用这3个函数完成数据处理过程中的一些demo,这里以经典的泰坦尼克号数据集为例。需要下载该数据集和文中示例源码的可后台回复关键字apply获取下载方式。
在学习apply具体应用之前,有必要首先阐释apply函数的方法论。apply英文原义是"应用"的意思,作为编程语言中的函数名,似乎在很多种语言都有体现,比如近日个人在学习Scala语言中apply被用作是伴生对象中自动创建对象的缺省实现,如此重要的角色也可见apply这个函数的重要性。那么apply应用在Pandas中,其核心功能其实可以概括为一句话:
apply:我本身不处理数据,我们只是数据的搬运工。
- 调度什么?调度的是apply函数接收的参数,即apply接收一个数据处理函数为主要参数,并将其应用到相应的数据上。所以调度什么取决于接收了什么样的数据处理函数;
- 为谁调度?也就是apply接收的数据处理函数,其作用对象是谁?或者说数据处理的粒度是什么?答案是数据处理的粒度包括了点线面三个层面:即可以是单个元素(标量,scalar),也可以是一行或一列(series),还可以是一个dataframe。
当然,这些文字描述肯定还比较抽象,那么不妨直接进入正题:talk is cheap,show me the code!
前面提到,理解apply核心在于明确两个环节:调度函数和作用对象。调度函数就是apply接收的参数,既可以是Python内置的函数,也支持自定义函数,只要符合指定的作用对象(即是标量还是series亦或一个dataframe)即可。而作用对象则取决于调用apply的对象类型,具体来说:
一个Series对象调用apply时,数据处理函数作用于该Series的每个元素上,即作用对象是一个标量,实现从一个Series转换到另一个Series;
一个DataFrame对象调用apply时,数据处理函数作用于该DataFrame的每一行或者每一列上,即作用对象是一个Series,实现从一个DataFrame转换到一个Series上;
一个DataFrame对象经过groupby分组后调用apply时,数据处理函数作用于groupby后的每个子dataframe上,即作用对象还是一个DataFrame(行是每个分组对应的行;列字段少了groupby的相应列),实现从一个DataFrame转换到一个Series上。
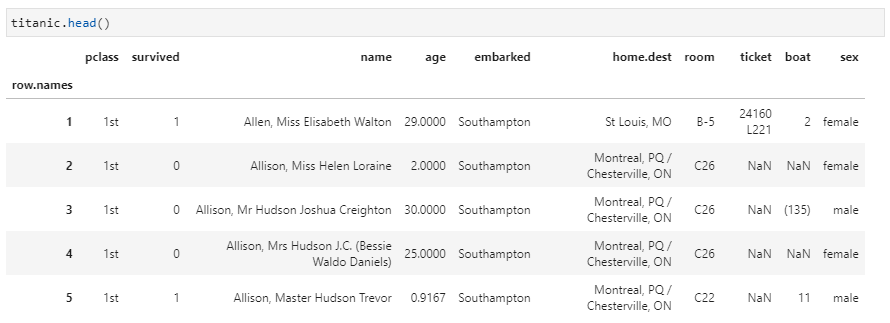
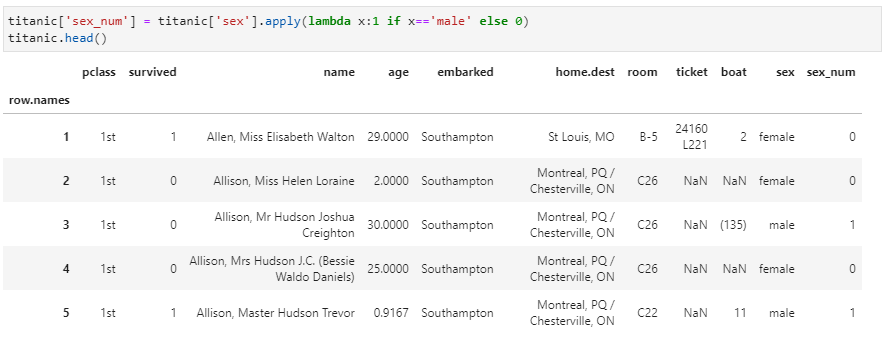
其中,这里apply接收了一个lambda匿名函数,通过一个简单的if-else逻辑实现数据映射。该功能十分简单,接收的函数也不带任何其他参数。
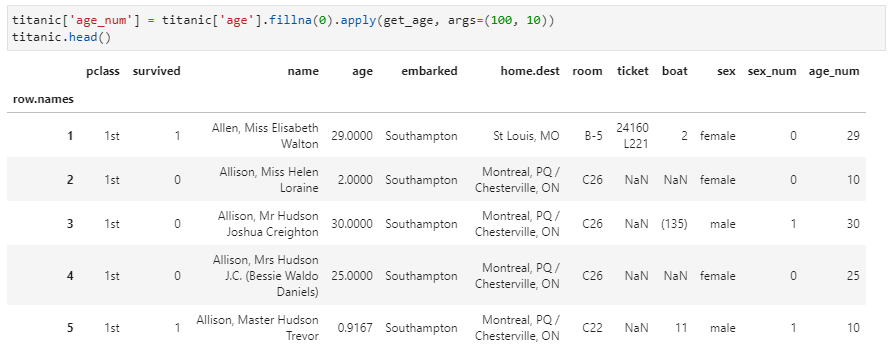
②下面再来一个稍微复杂一点的案例,注意到年龄age列当前数据类型是小数,需要将其转换为整数,同时还有0.9167这种过小的年龄,所以要求接受一个函数,支持接受指定的最大和最小年龄限制,当数据中超出此年龄范围的统一用截断填充,同时由于原数据集中age列存在缺失值,还需首先进行缺失值填充。这里首先实现一个自定义函数用于实现指定的年龄处理功能:
def get_age(age, max_age, min_age):age = int(age) # 转换为整数if age > max_age:age = max_ageif age < min_age:age = min_agereturn age
然后,直接对age列调用该函数即可,其中除了第一个参数age由调用该函数的series进行向量化填充外,另两个参数需要指定,在apply中即通过args传入。具体而言,实现如下:
2. 应用到DataFrame的每个Series
DataFrame是pandas中的核心数据结构,其每一行和每一列都是一个Series数据类型。那么应用apply到一个DataFrame的每个Series,自然存在一个问题是应用到行还是列的问题,所以一个DataFrame调用apply函数时需要指定一个axis参数,其中axis=0对应行方向的处理,即对每列应用apply接收函数;axis=1对应列方向处理,即对每行应用接收函数。默认为axis=0。这里仍然举两个小例子:
①取所有数值列的数据最大值。当然,这个处理其实可以直接调用max函数,但这里为了演示apply应用,所以不妨照此尝试:
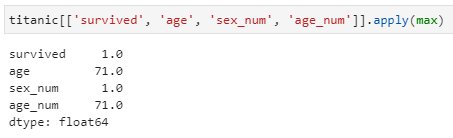
上述apply函数完成了对四个数值列求取最大值,其中缺省axis参数为0,对应行方向处理,即对每一列数据求最大值。
②然后来一个按行方向处理的例子,例如根据性别和年龄,区分4类人群:即女孩、成年女子、男孩、成年男子,其中年龄以18岁为界值进行区分。首先给出人群划分的函数实现:
def cat_person(sr):if sr['sex_num'] == 0:if sr['age_num'] < 18:return '女孩'else:return '成年女子'else:if sr['age_num'] < 18:return '男孩'else:return '成年男子'
基于此,用apply简单调用即可,其中axis=1设置apply的作用方向为按列方向,即对每行进行处理。其中每行都相当于一个带有age和sex等信息的Series,通过cat_person函数进行提取判断,即实现了人群的划分:

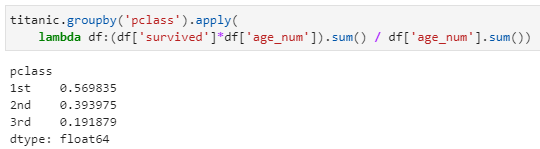
其中apply接收一个lambda匿名函数,该匿名函数接收一个dataframe为参数(该dataframe中不含pclass列),并提取survived列和age_num列参与计算。最后得到每个舱位等级的一个统计指标结果,返回类型是一个Series对象。
这里,再补充一个前期分享过的一片推文:Pandas用的6不6,来试试这道题就能看出来,实际上也是实现了相同的分组聚合统计功能。
以上,可以梳理apply函数的执行流程:首先明确调用apply的数据结构类型,是Series还是DataFrame,如果是DataFrame还需进一步确定是直接调用apply还是经过groupby分组之后调用,其中前者对应apply的接收函数处理一行或一列,后者对应接收函数处理每个分组对应的子DataFrame,最后根据作用对象类型设计相应的接收函数,从而完成个性化的数据处理。
前面介绍了apply的三种应用场景,作用对象分别对应元素、Series以及DataFrame,可以说功能已经非常强大了。除了apply之外,pandas其实还提供了两个功能极为相近的函数:map和applymap,不过相较于功能强大的apply来说,二者功能则相对局限。具体而言,二者分别实现功能如下:
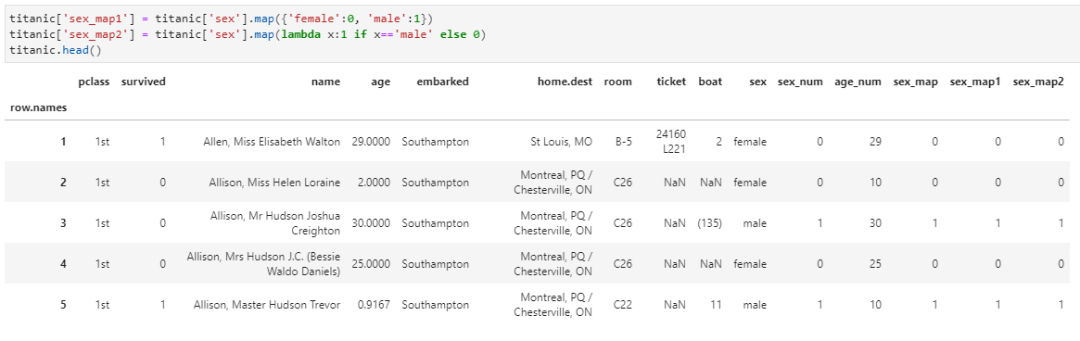
从某种角度来讲,这种变换得以实施的前提是该DataFrame的各列元素具有相同的数据类型和相近的业务含义,否则运用相同的数据变换很难保证实际效果。
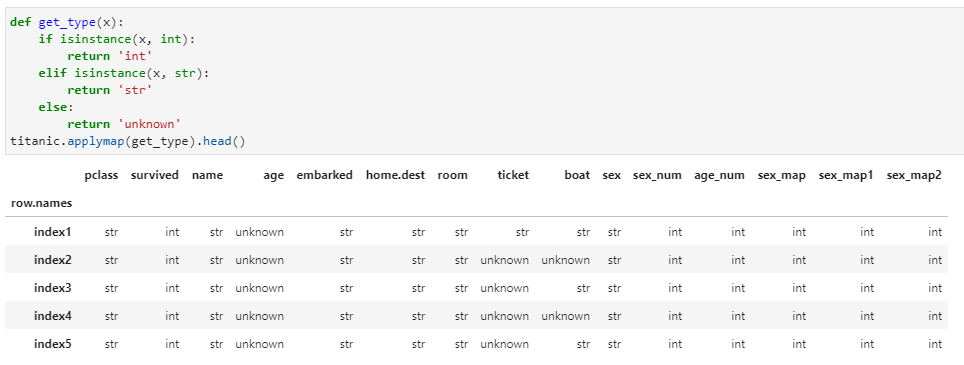
假设需要获取DataFrame中各个元素的数据类型,则应用applymap实现如下:
apply、map和applymap常用于实现Pandas中的数据变换,通过接收一个函数实现特定的变换规则;
apply功能最为强大,可应用于Series、DataFrame以及DataFrame分组后的group DataFrame,分别实现元素级、Series级以及DataFrame级别的数据变换;
map仅可作用于Series实现元素级的变换,既可以接收一个字典完成变化也可接收特定的函数,而且不仅可作用于普通的Series类型,也可用于索引列的变换,而索引列的变换是apply所不能应用的;
applymap仅可用于DataFrame,接收一个函数实现对所有数据实现元素级的变换


