
一文看懂 Pandas 中的透视表

一文看懂 Pandas 中的透视表
透视表在一种功能很强大的图表,用户可以从中读取到很多的信息。利用excel可以生成简单的透视表。本文中讲解的是如何在pandas中的制作透视表。
读取数据
注:本文的原始数据文件,可以在早起Python后台回复 “透视表”获取。
import pandas as pd
import numpy as np
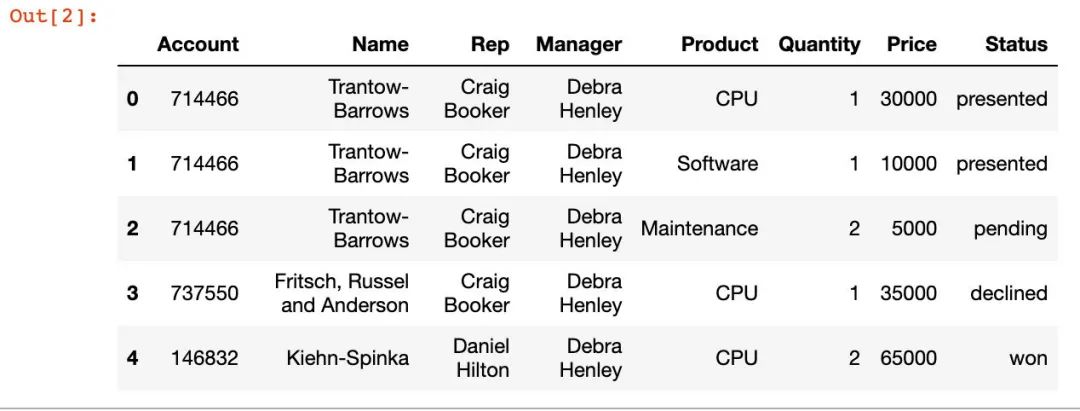
df = pd.read_excel("./sales-funnel.xlsx") # 当前目录下的文件
df.head()
设置数据
使用 category数据类型,按照想要查看的方式设置顺序
不严格要求,但是设置了顺序有助于分析,一直保持所想要的顺序
df["Status"] = df["Status"].astype("category")
df["Status"].cat.set_categories(["won","pending","presented","declined"],inplace=True) # 设置顺序
建立透视表
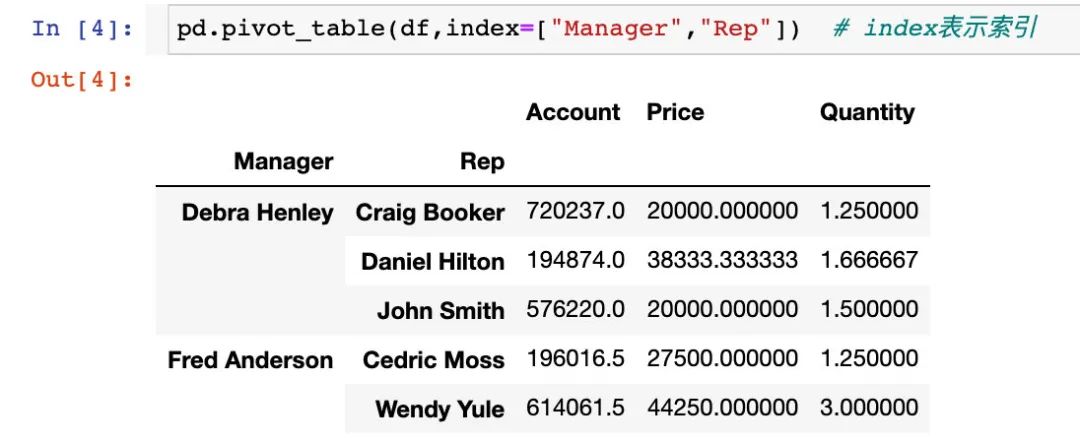
只使用index参数
pd.pivot_table(df,index=["Manager","Rep"]) # index表示索引
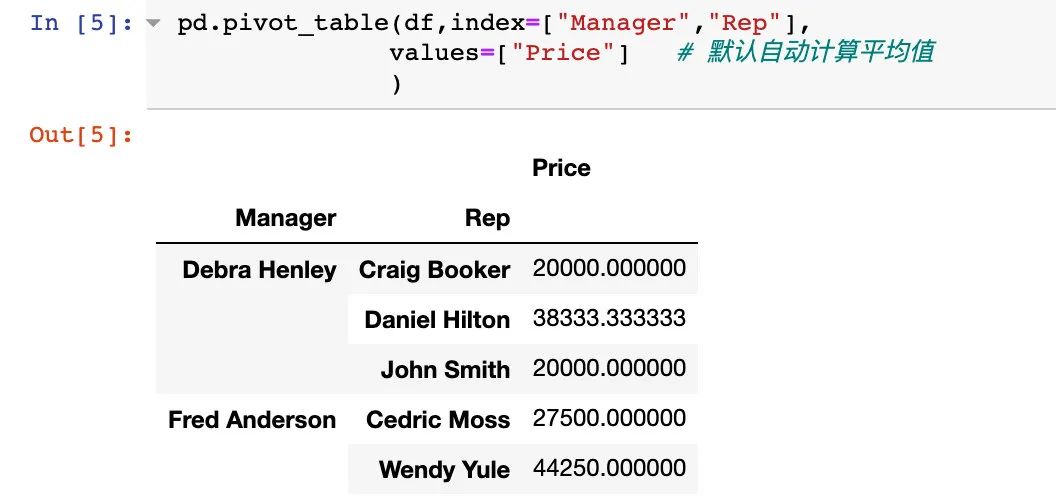
2. 使用index和values两个参数
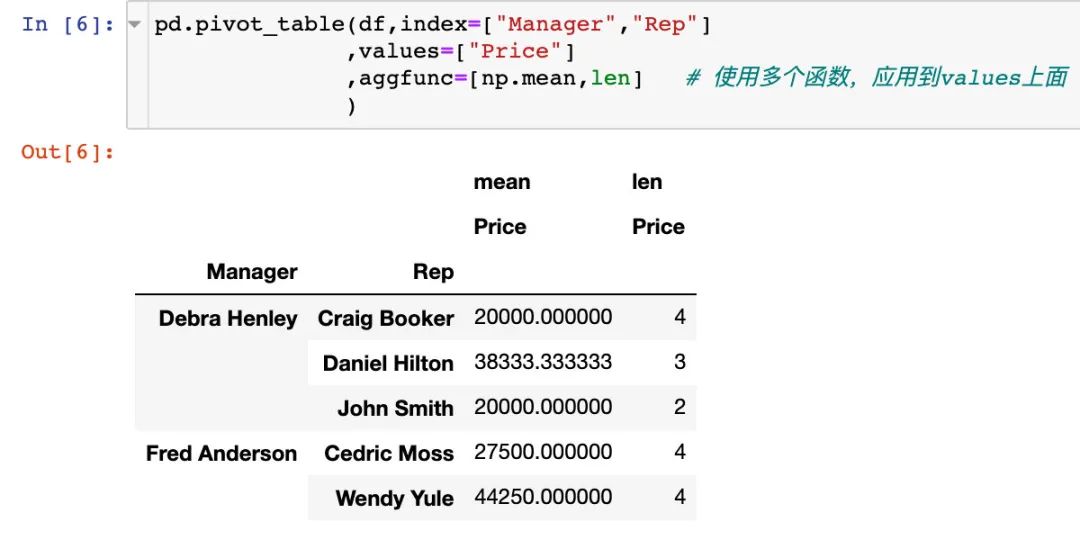
3. 使用aggfunc参数,指定多个函数
4.使用columns参数,指定生成的列属性
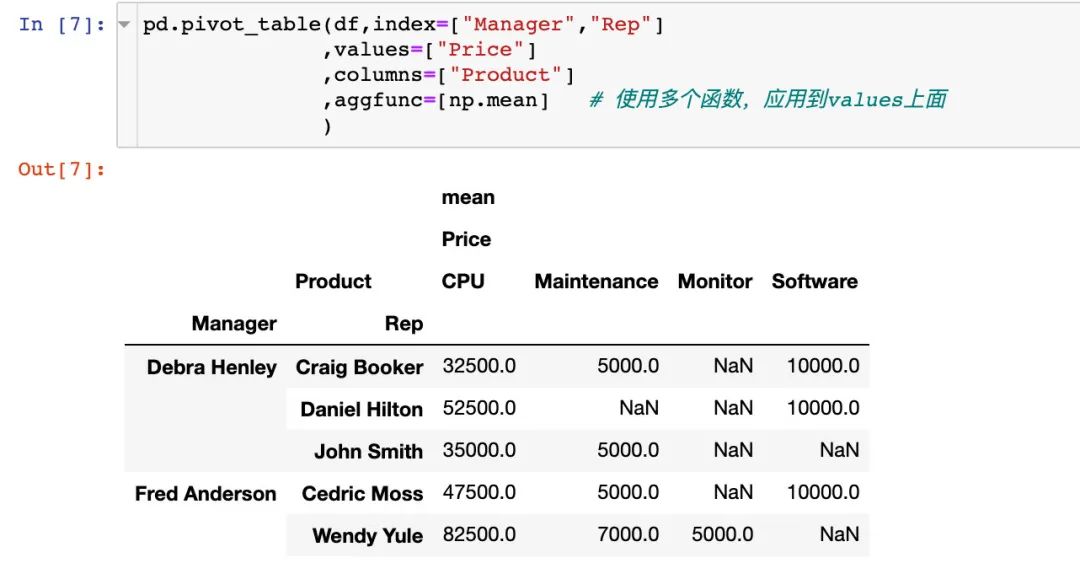
5. 解决数据的NaN值,使用fill_value参数
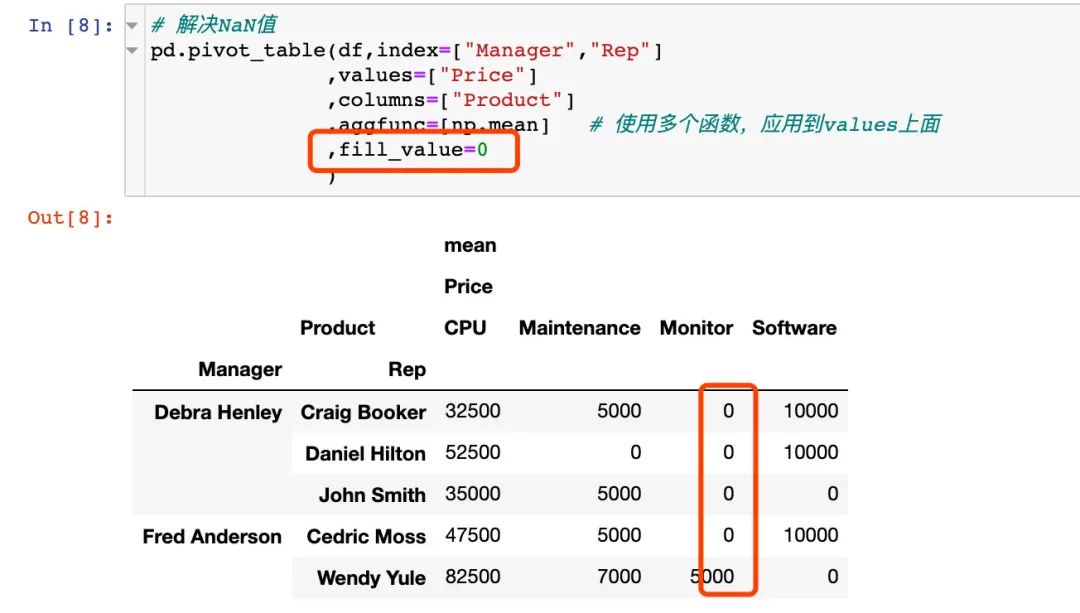
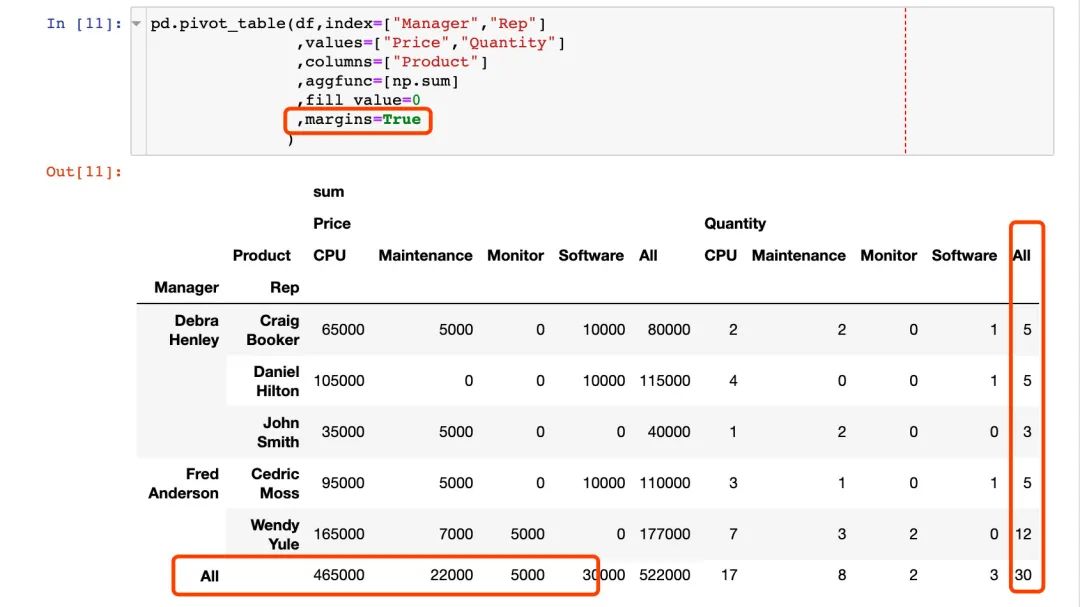
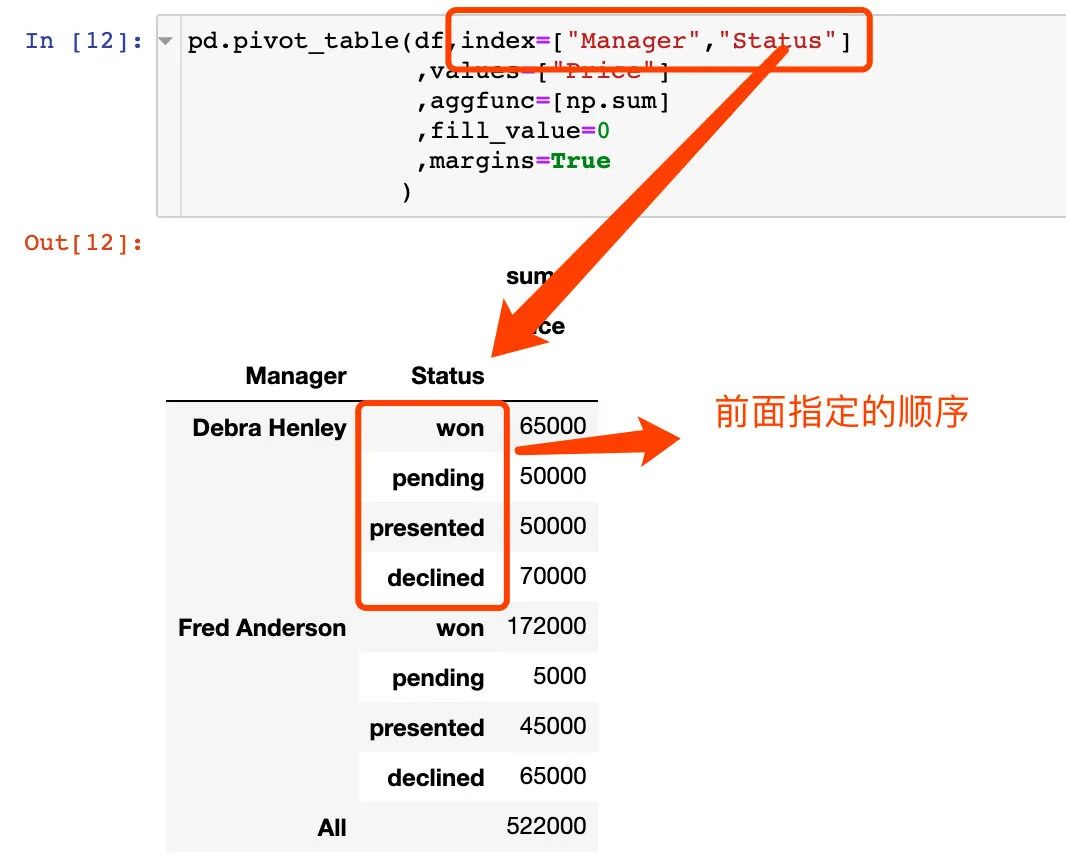
6. 查看总数据,使用margins=True
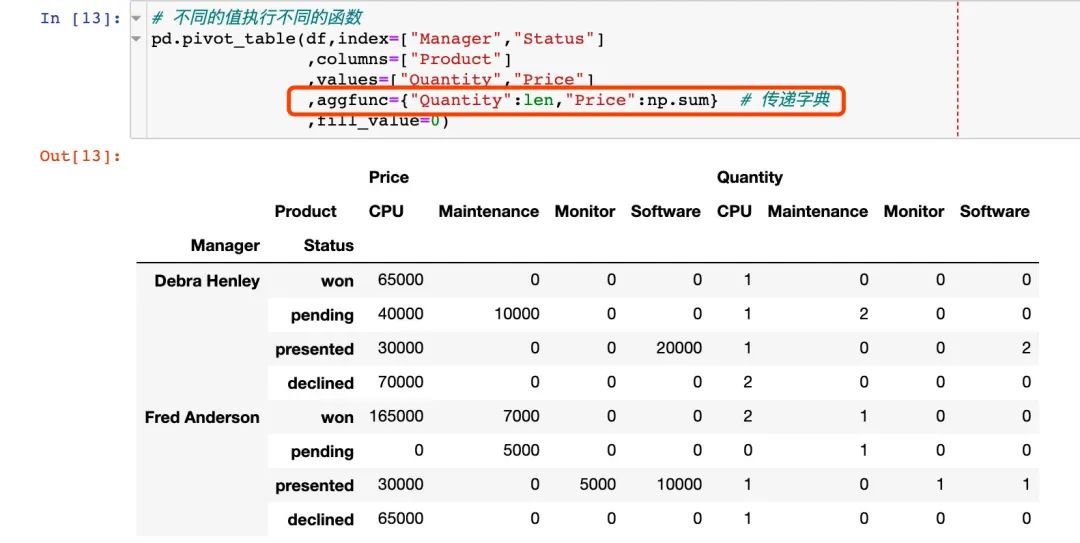
7. 不同的属性字段执行不同的函数
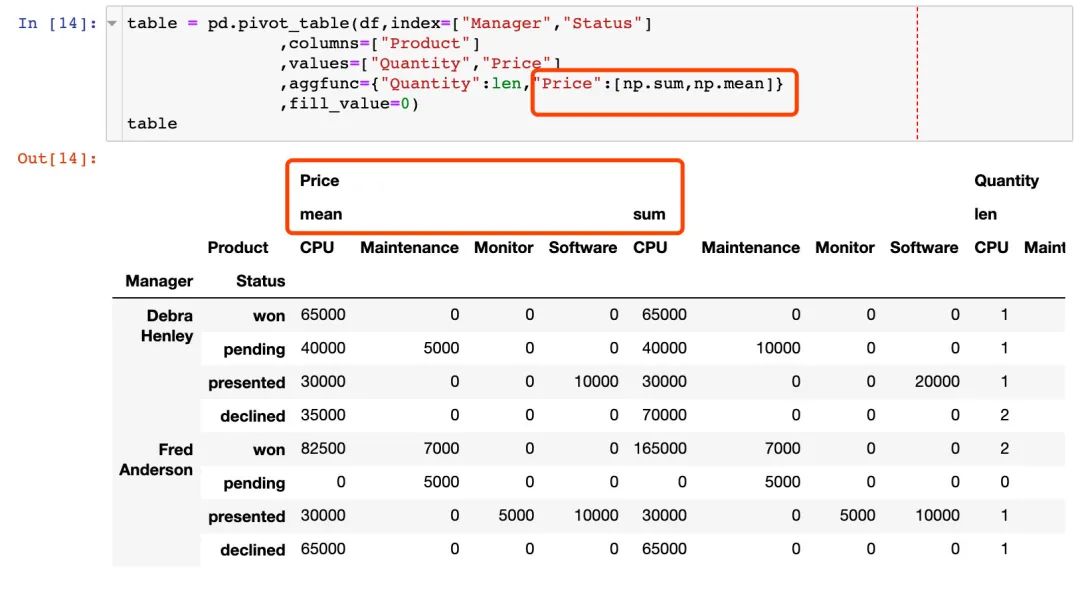
8. Status排序作用的体现
高级功能
当通过透视表生成了数据之后,便被保存在了数据帧中
查询指定的字段值的信息
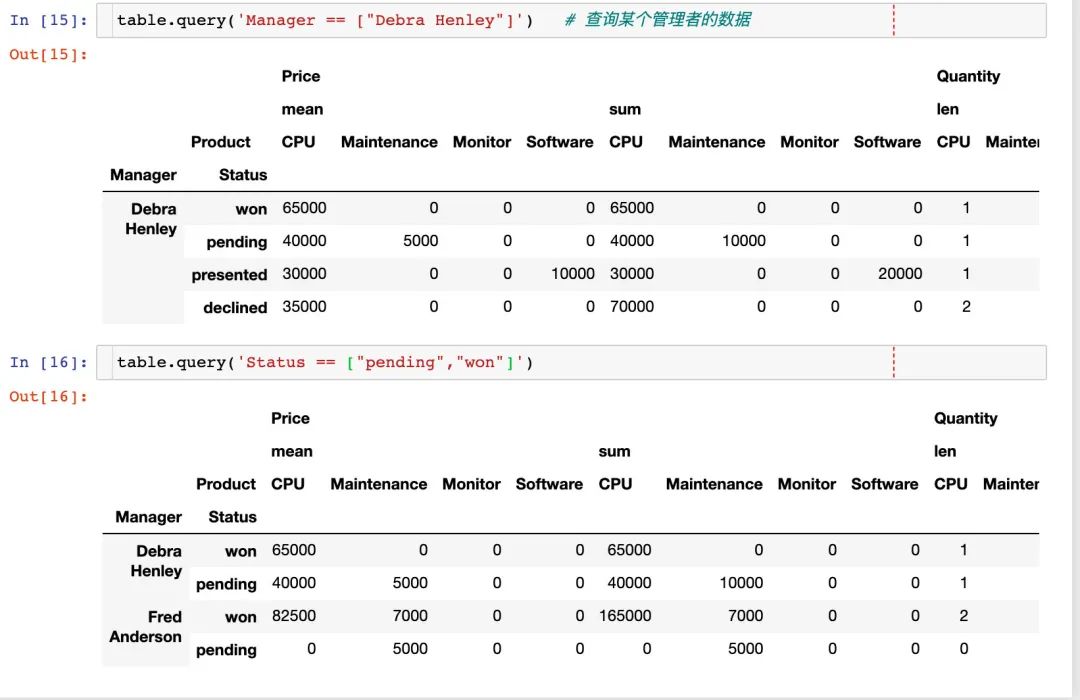
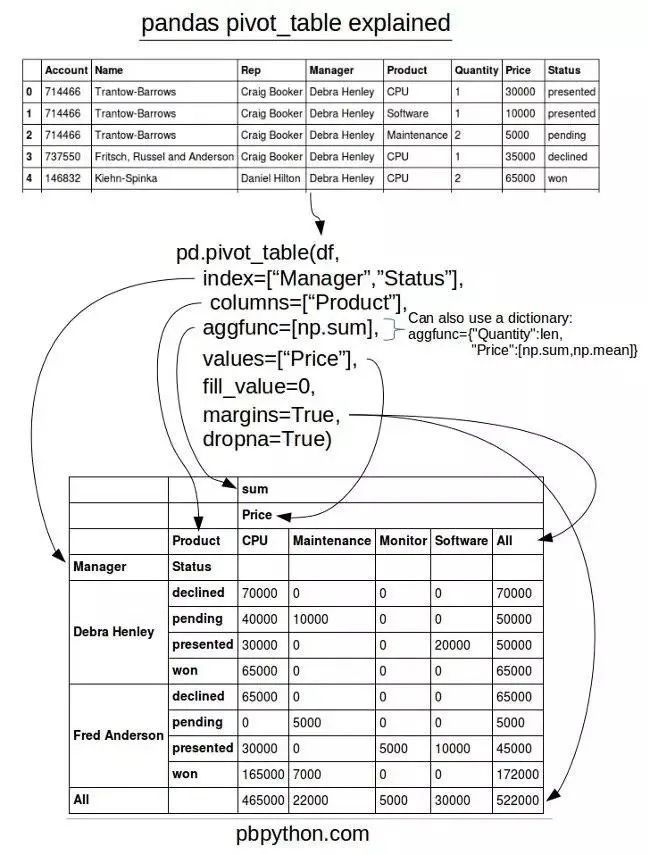
图形备忘录
网上有一张关于利用pivot_table函数的分解图,大家可以参考下
-END-
本文来自公众号读者投稿,欢迎各位童鞋向公号投稿赚钱,点击阅读原文了解详情!
评论