
300来行代码带你实现一个能跑的最小Linux文件系统


点击「阅读原文」查看良许原创精品视频。
点击「阅读原文」查看良许原创精品视频。
Linux作为一个类UNIX系统,其文件系统保留了原始UNIX文件系统的表象形式,它看起来是这个样子:
root@name-VirtualBox:/# ls
bin boot cdrom dev etc home lib lib64 lost+found media mnt opt proc root run sbin snap srv sys tmp usr var
root@name-VirtualBox:/#
root@name-VirtualBox:/# ls /home/
zy
root@name-VirtualBox:/#
root@name-VirtualBox:/# ls /usr/
bin games include lib lib64 local sbin share src
root@name-VirtualBox:/# ls /mnt/
project src
它其实是一棵目录树(没有画全):
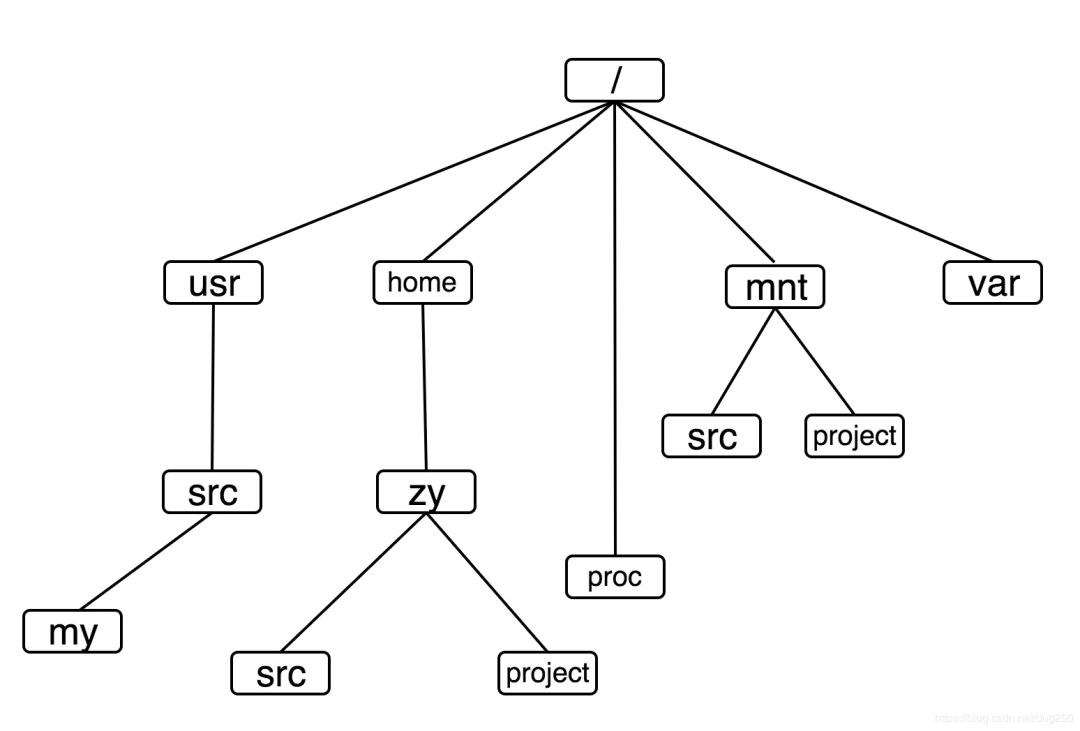
然而,虽然所有的UNIX系统以及类UNIX系统的文件系统看起来一样,但是它们的实现却是不尽相同。
作为普通用户,了解文件系统的基本操作就够了;作为应用开发人员,了解文件系统的POSIX接口足矣,但是作为一个对操作系统有着浓厚兴趣的爱好者而言,自己可能就是一个新的文件系统的潜在实现者,所以必须一窥究竟,看看如此外观的文件系统到底是如何实现的。
网上已经有了很多关于UNIX/Linux文件系统实现的资源,但是无一例外,都太复杂了,除了整体的源码分析外,几乎就是针对某个特定文件系统的详解了,如此复杂的这些对于初涉该领域的满腔热情者无疑是一盆冷水,很多人因此望而却步。
...
mount机制是如何实现的?
inode是如何分配的?磁盘inode和内存inode有什么区别?
dentry缓存是怎么回事?是如何管理的?
pagecache是什么?radix树如何管理文件数据缓存?
cache和buffer的区别又是什么?
...
几乎所有的关于Linux文件系统实现的资源都在用不同的语言解释上面的这些问题,这很容易陷入细节的泥潭。
本文以Linux内核为例,用一种稍微不同的方式去描述文件系统的实现。嗯,我会分3个部分来介绍Linux内核的文件系统:
Linux文件系统在不同视角下的样子
实现一个很小但能跑的文件系统
接下来要做什么
本文中,我会通过一个实实在在的文件系统实现的例子,试图阐述 实现一个文件系统,哪些是必须的,哪些不是必须的。 这是一个任务驱动的过程,从简单的例子开始。
读过本文之后,相信会对Linux文件系统的实现有一个总体上的宏观把握,然后再去反复推敲上述的细节问题,重读网上的那些经典资源,相信会事半功倍。
Linux文件系统在不同视角下的样子
当然,在给出最简单的tinyfs实现之前,还是会有一个总体的介绍。
如果我们把本文最初描述的那个在几乎所有UNIX/类UNIX系统中长的一模一样的文件系统表面刨开,在Linux内核中,文初的那棵树其实它长下面的样子(其实在大多数类UNIX系统中,它们长得都差不多):
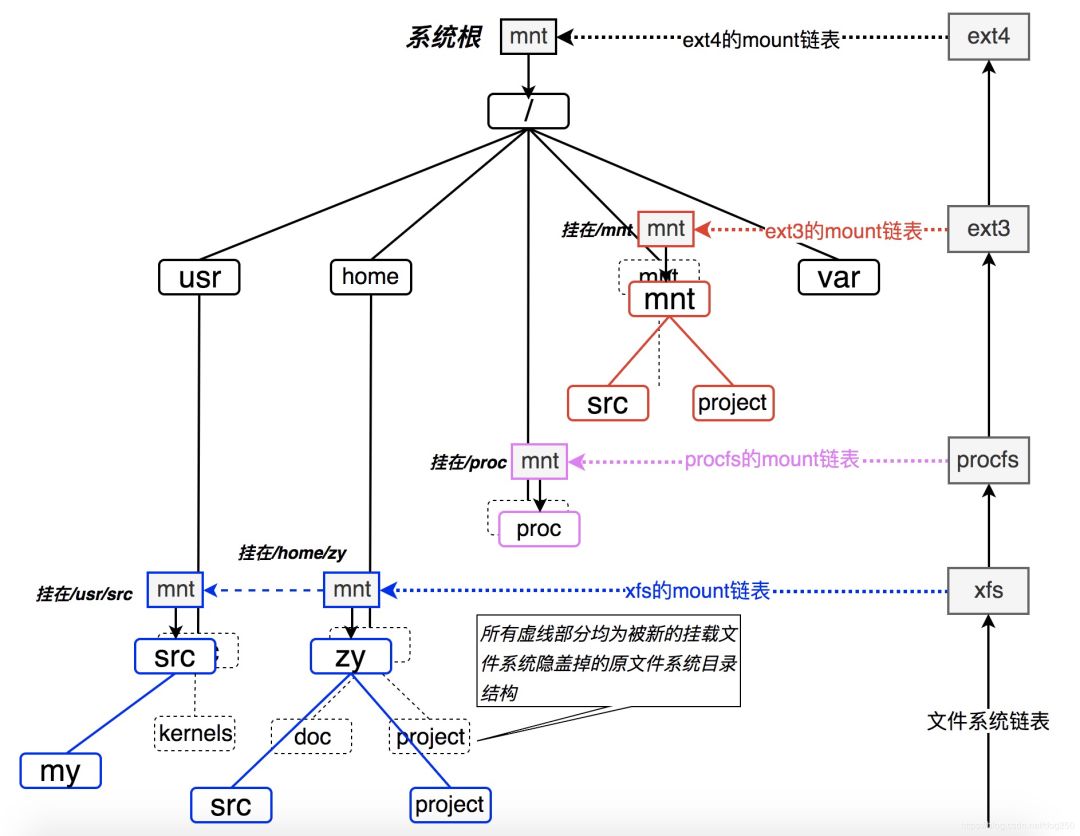
【这张图基于我2010年的一张手绘图修改而成,怀旧的可以参见以下链接:https://blog.csdn.net/dog250/article/details/5822440】
我们看到,Linux系统的文件目录树就是靠上图中的这一系列的链表穿针引线给串在一起的,就像缝制一件衣服一样,最终的成衣就是我们看到的Linux系统目录树,而缝制这件成衣的线以及指导走线的规则便是VFS本身了。
现在只要记住两个重要链表:
文件系统链表。
每一个文件系统的mount挂载点链表。
然后读完本文之后再去结合代码深入分析它们是如何串起整个文件系统的。
VFS之所有可以将机制大相径庭的完全不同的文件系统对外统一成一个样子,完全就是依靠了它的统一的对POSIX文件调用的接口,该接口的结构看上去是下面的样子:
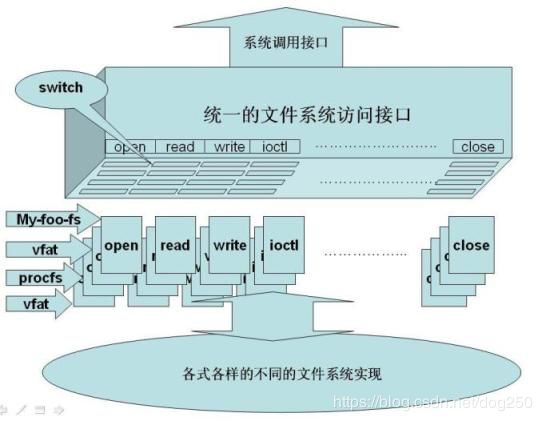
注意上图最下面的那个椭圆,如果要实现一个文件系统,这个椭圆里的东西是关键,它完成了穿针引线的大部分工作。
现在让我们纵向地看一下一个完整的文件系统实现都包括什么,我指的是从POSIX系统调用开始,一直到数据落盘。Linux内核关于文件系统IO,完整的视图如下所示:
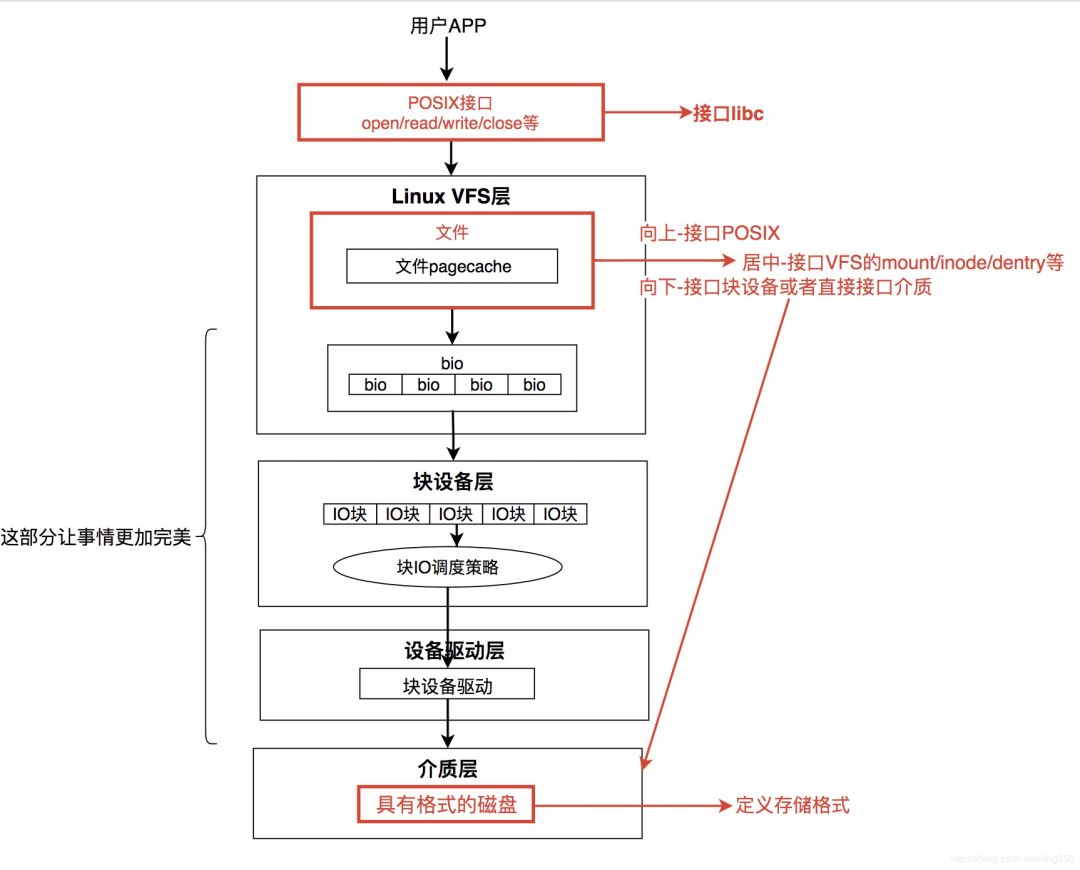
和POSIX系统调用的接口 即实现open/read/write的操作的接口。
和底层介质的接口 即下接块设备层的接口。
如何管理自身 即何时以及如何操作VFS数据结构inode,dentry,mount等对象。
一个文件系统如果能实现上面三类接口,那它就是个完整的文件系统了。
我们恰好可以从设计并实现一个最基本的这样的文件系统开始。一个基本的文件系统,其着重点在于上图中红色的部分,而其它部分则不是必不可少的,但是却是让该文件系统变得优秀(而不仅仅是可用)所必须的。
实现一个很小但能跑的文件系统
为什么要实现这么一个文件系统,难道没人已经做了这个工作吗?做这个工作的意义何在?
原因如下:
我没有找到现成的比较完整且炫酷的作品。 当然有人写这种文件系统练手,但是看下来要么就是使用了libfs.c里封装好的接口,要么就是没有自己设计文件系统的底层存储格式。
下班的班车在路上堵了一个多小时,无聊撸会儿代码。
然而确实,我没有找到简单的 最小文件系统 实现,也许你会说Linux内核自带的ramfs难道不就是一个现成的吗?的确算一个,但它有两个问题导致你无法领略实现一个文件系统的全过程,注意,我说的可是全过程:
ramfs无法让你自己设计底层模拟介质的格式,不完整。
ramfs调用了大量的fs/libfs.c中的内核库例程,不纯碎。
为了 追求完整, 如果你把如何组织一块内核作为ramfs的底层介质这部分代码全部看完,如果你把libfs.c里的库实现全部看完,我想ramfs也就不算一个 足够简单 的文件系统实例了。
看到了么?要想代码简单,你就不得不使用libfs.c里的现成的例程,这将损失你实现一个文件系统的完整性体验,反之,要想完整实现一个文件系统,你可能不得不自己写大量的代码,这却并不简单。
如何既完备,又足够简单呢?
对于我这种编程水平渣渣的内核爱好者而言,如何在堵车的一个多小时内完成一个可以编译通过的文件系统(我承认完全能跑是我回到家后又调试了一个多小时才完成的...),这对于我而言,是一个挑战,但我要试一试,没想到就成功了。所以才有了今天的分享。
我从最底层的介质结构的设计开始。
我并没有真实的硬件介质,也并不打算编写专门的 格式化程序 去格式化一块内存区域,所以我直接用大数组定义一块内存,它便是我的模拟介质了,我的tinyfs的文件格式如下:
// tinyfs.h
#define MAXLEN 8
#define MAX_FILES 32
#define MAX_BLOCKSIZE 512
// 定义每一个目录项的格式
struct dir_entry {
char filename[MAXLEN];
uint8_t idx;
};
// 定义每一个文件的格式。
struct file_blk {
uint8_t busy;
mode_t mode;
uint8_t idx;
union{
uint8_t file_size;
uint8_t dir_children;
};
char data[0];
};
// OK,下面的block数组所占据的连续内存就是我的tinyfs的介质,每一个元素代表一个文件。
// struct file_blk block[MAX_FILES+1];
这个文件系统的格式非常的Low:
最多容纳512个文件(包括目录在内)。
每个文件包括元数据在内最多32个字节。
文件名最多8个字节。
之所以这么Low是因为它只是一个开始, 当这个文件系统实现并且能跑之后,你会发现它因为Low而带来的不足和一些代价,而弥补这些不足正好是优化的动机,带着你逐步实现一个更加不Low的文件系统,在实现的过程中,你会窥见并掌握Linux内核文件系统的全貌和细节。 完美的学习过程,OK!
下面是代码:
// tinyfs.c
#include
#include
#include
#include
#include"tinyfs.h"
struct file_blk block[MAX_FILES+1];
int curr_count = 0; // 我勒个去,竟然使用了全局变量!
// 获得一个尚未使用的文件块,保存新创建的文件或者目录
staticint get_block(void)
{
int i;
// 就是一个遍历,但实现快速。
for(i = 2; i < MAX_FILES; i++) {
if(!block[i].busy) {
block[i].busy = 1;
return i;
}
}
return-1;
}
staticstruct inode_operations tinyfs_inode_ops;
// 读取目录的实现
staticint tinyfs_readdir(struct file *filp, void*dirent, filldir_t filldir)
{
loff_t pos;
struct file_blk *blk;
struct dir_entry *entry;
int i;
pos = filp->f_pos;
if(pos)
return0;
blk = (struct file_blk *)filp->f_dentry->d_inode->i_private;
if(!S_ISDIR(blk->mode)) {
return-ENOTDIR;
}
// 循环获取一个目录的所有文件的文件名
entry = (struct dir_entry *)&blk->data[0];
for(i = 0; i < blk->dir_children; i++) {
filldir(dirent, entry[i].filename, MAXLEN, pos, entry[i].idx, DT_UNKNOWN);
filp->f_pos += sizeof(struct dir_entry);
pos += sizeof(struct dir_entry);
}
return0;
}
// read实现
ssize_t tinyfs_read(struct file * filp, char __user * buf, size_t len, loff_t*ppos)
{
struct file_blk *blk;
char*buffer;
blk = (struct file_blk *)filp->f_path.dentry->d_inode->i_private;
if(*ppos >= blk->file_size)
return0;
buffer = (char*)&blk->data[0];
len = min((size_t) blk->file_size, len);
if(copy_to_user(buf, buffer, len)) {
return-EFAULT;
}
*ppos += len;
return len;
}
// write实现
ssize_t tinyfs_write(struct file * filp, constchar __user * buf, size_t len, loff_t* ppos)
{
struct file_blk *blk;
char*buffer;
blk = filp->f_path.dentry->d_inode->i_private;
buffer = (char*)&blk->data[0];
buffer += *ppos;
if(copy_from_user(buffer, buf, len)) {
return-EFAULT;
}
*ppos += len;
blk->file_size = *ppos;
return len;
}
conststruct file_operations tinyfs_file_operations = {
.read = tinyfs_read,
.write = tinyfs_write,
};
conststruct file_operations tinyfs_dir_operations = {
.owner = THIS_MODULE,
.readdir = tinyfs_readdir,
};
// 创建文件的实现
staticint tinyfs_do_create(struct inode *dir, struct dentry *dentry, umode_t mode)
{
struct inode *inode;
struct super_block *sb;
struct dir_entry *entry;
struct file_blk *blk, *pblk;
int idx;
sb = dir->i_sb;
if(curr_count >= MAX_FILES) {
return-ENOSPC;
}
if(!S_ISDIR(mode) && !S_ISREG(mode)) {
return-EINVAL;
}
inode = new_inode(sb);
if(!inode) {
return-ENOMEM;
}
inode->i_sb = sb;
inode->i_op = &tinyfs_inode_ops;
inode->i_atime = inode->i_mtime = inode->i_ctime = CURRENT_TIME;
idx = get_block(); // 获取一个空闲的文件块保存新文件
blk = &block[idx];
inode->i_ino = idx;
blk->mode = mode;
curr_count ++;
if(S_ISDIR(mode)) {
blk->dir_children = 0;
inode->i_fop = &tinyfs_dir_operations;
} elseif(S_ISREG(mode)) {
blk->file_size = 0;
inode->i_fop = &tinyfs_file_operations;
}
inode->i_private = blk;
pblk = (struct file_blk *)dir->i_private;
entry = (struct dir_entry *)&pblk->data[0];
entry += pblk->dir_children;
pblk->dir_children ++;
entry->idx = idx;
strcpy(entry->filename, dentry->d_name.name);
// VFS穿针引线的关键步骤,将VFS的inode链接到链表
inode_init_owner(inode, dir, mode);
d_add(dentry, inode);
return0;
}
staticint tinyfs_mkdir(struct inode *dir, struct dentry *dentry, umode_t mode)
{
return tinyfs_do_create(dir, dentry, S_IFDIR | mode);
}
staticint tinyfs_create(struct inode *dir, struct dentry *dentry, umode_t mode, bool excl)
{
return tinyfs_do_create(dir, dentry, mode);
}
staticstruct inode *tinyfs_iget(struct super_block *sb, int idx)
{
struct inode *inode;
struct file_blk *blk;
inode = new_inode(sb);
inode->i_ino = idx;
inode->i_sb = sb;
inode->i_op = &tinyfs_inode_ops;
blk = &block[idx];
if(S_ISDIR(blk->mode))
inode->i_fop = &tinyfs_dir_operations;
elseif(S_ISREG(blk->mode))
inode->i_fop = &tinyfs_file_operations;
inode->i_atime = inode->i_mtime = inode->i_ctime = CURRENT_TIME;
inode->i_private = blk;
return inode;
}
struct dentry *tinyfs_lookup(struct inode *parent_inode, struct dentry *child_dentry, unsignedint flags)
{
struct super_block *sb = parent_inode->i_sb;
struct file_blk *blk;
struct dir_entry *entry;
int i;
blk = (struct file_blk *)parent_inode->i_private;
entry = (struct dir_entry *)&blk->data[0];
for(i = 0; i < blk->dir_children; i++) {
if(!strcmp(entry[i].filename, child_dentry->d_name.name)) {
struct inode *inode = tinyfs_iget(sb, entry[i].idx);
struct file_blk *inner = (struct file_blk *)inode->i_private;
inode_init_owner(inode, parent_inode, inner->mode);
d_add(child_dentry, inode);
return NULL;
}
}
return NULL;
}
int tinyfs_rmdir(struct inode *dir, struct dentry *dentry)
{
struct inode *inode = dentry->d_inode;
struct file_blk *blk = (struct file_blk *)inode->i_private;
blk->busy = 0;
return simple_rmdir(dir, dentry);
}
int tinyfs_unlink(struct inode *dir, struct dentry *dentry)
{
int i;
struct inode *inode = dentry->d_inode;
struct file_blk *blk = (struct file_blk *)inode->i_private;
struct file_blk *pblk = (struct file_blk *)dir->i_private;
struct dir_entry *entry;
// 更新其上层目录
entry = (struct dir_entry *)&pblk->data[0];
for(i = 0; i < pblk->dir_children; i++) {
if(!strcmp(entry[i].filename, dentry->d_name.name)) {
int j;
for(j = i; j < pblk->dir_children - 1; j++) {
memcpy(&entry[j], &entry[j+1], sizeof(struct dir_entry));
}
pblk->dir_children --;
break;
}
}
blk->busy = 0;
return simple_unlink(dir, dentry);
}
staticstruct inode_operations tinyfs_inode_ops = {
.create = tinyfs_create,
.lookup = tinyfs_lookup,
.mkdir = tinyfs_mkdir,
.rmdir = tinyfs_rmdir,
.unlink = tinyfs_unlink,
};
int tinyfs_fill_super(struct super_block *sb, void*data, int silent)
{
struct inode *root_inode;
int mode = S_IFDIR;
root_inode = new_inode(sb);
root_inode->i_ino = 1;
inode_init_owner(root_inode, NULL, mode);
root_inode->i_sb = sb;
root_inode->i_op = &tinyfs_inode_ops;
root_inode->i_fop = &tinyfs_dir_operations;
root_inode->i_atime = root_inode->i_mtime = root_inode->i_ctime = CURRENT_TIME;
block[1].mode = mode;
block[1].dir_children = 0;
block[1].idx = 1;
block[1].busy = 1;
root_inode->i_private = &block[1];
sb->s_root = d_make_root(root_inode);
curr_count ++;
return0;
}
staticstruct dentry *tinyfs_mount(struct file_system_type *fs_type, int flags, constchar*dev_name, void*data)
{
return mount_nodev(fs_type, flags, data, tinyfs_fill_super);
}
staticvoid tinyfs_kill_superblock(struct super_block *sb)
{
kill_anon_super(sb);
}
struct file_system_type tinyfs_fs_type = {
.owner = THIS_MODULE,
.name = "tinyfs",
.mount = tinyfs_mount,
.kill_sb = tinyfs_kill_superblock,
};
staticint tinyfs_init(void)
{
int ret;
memset(block, 0, sizeof(block));
ret = register_filesystem(&tinyfs_fs_type);
if(ret)
printk("register tinyfs failed\n");
return ret;
}
staticvoid tinyfs_exit(void)
{
unregister_filesystem(&tinyfs_fs_type);
}
module_init(tinyfs_init);
module_exit(tinyfs_exit);
MODULE_LICENSE("GPL");
review代码后,你可能已经发现了几个问题:
这个tinyfs文件系统存储格式中怎么没有超级块?(竟然使用了全局变量)
这个tinyfs文件系统存储格式中怎么没有inode表或者空闲位图?
这个tinyfs文件系统怎么将元数据和文件数据放在了一起?
这个文件系统怎么不支持并发?没见到一把锁啊!
...
嗯,其实这些问题目前而言还都不是问题,它们并不阻碍这个文件系统的真实性,它用起来是那么的真实。
没有任何规范规定一个文件系统存储格式必须有什么或者必须没有什么,文件系统格式只是一个 看上去还可以的信息持久化记录格式 ,只要下次能根据某些信息将文件读取出来,任何格式都是OK的。
之所以很多人会认为一个文件系统的格式必须要符合某种规范,完全是因为人们看的最多的那些文件系统ext3,ext4,ntfs等恰好是那样做的罢了。不过事实证明,那样做确实是很好的。在可用的玩具完成之后,就要考虑 性能,健壮性,可扩展性 等这些工程因素了。而ext3/4,ntfs,xfs则充分考虑了这些。
逐渐的,权威变成了规范,至少成了一种范式或者模式,这是计算机领域常有的事,见怪不怪。
我们来使用下这个文件系统:
[root@localhost ~]# insmod ./tinyfs.ko
[root@localhost ~]# mount -t tinyfs none /mnt
OK,挂载成功。
这里又有疑问了,为什么是none挂载,而不是一个块设备,比如/dev/sda1之类的。
这是因为我根本没有将介质(其实是一块连续的内存)抽象成块设备,如果引入块设备抽象,势必要导出device层操作接口,这样做并不困难,但却太麻烦,且块设备抽象和文件系统的实现核心无关。本文不是讲块设备的,加之班车上的堵车时间有限,故不做抽象。
好了,现在让我们来折腾下/mnt目录,该目录就是我的tinyfs的挂载目录了,在其下读写文件,就是在tinyfs的内存介质上读写文件:
[root@localhost ~]# cd /mnt/
[root@localhost mnt]# ls
[root@localhost mnt]#
[root@localhost mnt]# echo 11111>./a
[root@localhost mnt]# cat ./a
11111
[root@localhost mnt]# mkdir dir1
[root@localhost mnt]# echo 22222>./dir1/b
[root@localhost mnt]#
[root@localhost mnt]# cat ./dir1/b
22222
[root@localhost mnt]#
[root@localhost mnt]# tree
.
├── a
└── dir1
└── b
1 directory, 2 files
[root@localhost mnt]# echo 333>./dir1/c
[root@localhost mnt]# cat ./dir1/c
333
[root@localhost mnt]# tree
.
├── a
└── dir1
├── b
└── c
1 directory, 3 files
[root@localhost mnt]# rm -f ./dir1/c
[root@localhost mnt]#
[root@localhost mnt]# tree
.
├── a
└── dir1
└── b
1 directory, 2 files
[root@localhost mnt]# rm -rf dir1
rm: 无法删除"dir1": 不允许的操作
[root@localhost mnt]#
除了最后一个删除目录的操作,其它的都OK,这也是预期之中,毕竟删除目录是TODO嘛。
接下来要做什么
一共300来行的代码(省去了很多异常判断和处理,真实情况下,这些要占据80%的代码量),非常容易读懂,你会发现这个文件系统实现是如此之low,然而却能看起来像真的一样。
这意味着完成和完美真的是两回事!
很多最终看起来很大型的东西,都是都这种刚刚完成可以用开始的。
很明显,这个代码没有使用块层来和底层介质通信,而是直接操作了底层介质,也就是那块连续的内存。因为我用内存模拟介质,尚且OK,如果底层真的有一个类似磁盘那样的慢速介质,每次操作直接读写block将是不可接受的。但如果你想获得性能上的提升,就必须使用块层的缓存机制,以及pagecache机制。
所以,方向很明确,我们有了一个todolist:
fix掉可能的bug,主要是引用计数的管理方面。
设计更好的文件系统底层存储格式,至少让它看起来更像回事。 比如引入超级块保存全局元数据,引入空闲索引位图,引入优雅的空闲块管理算法,类似内存管理那样,减少内外的存储碎片,引入一些启发式策略,比如预读,合并写,当然,这些属于调度的范畴,但无论如何, 良好的存储结构可以极大影响启发式策略的实施。
使用块层标准接口进行IO,比如 *sb_bread,mark_buffer_dirty 这样的接口。*
使用pagecache进行数据cache。
这些todo完成,意味着对Linux内核文件系统实现原理的彻底掌握,从一个简单的刚刚可用的tinyfs开始(这花不了多少时间),到整理出一份todolist,到完成这些todo,这便是一个任务驱动的学习过程。
回过头来看Linux文件系统IO的纵向视图: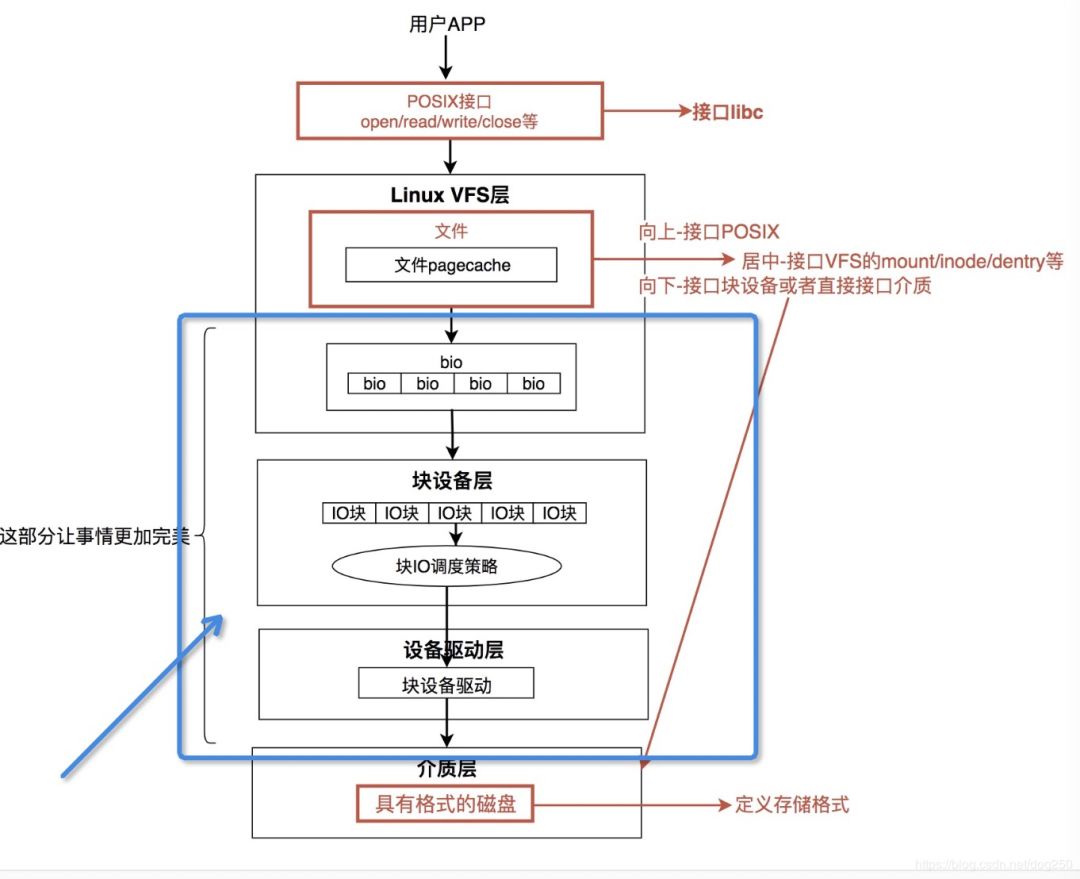 这次注意蓝色部分,我们的TODO就是要补充这部分的实现。
这次注意蓝色部分,我们的TODO就是要补充这部分的实现。
好了,换一个视角看VFS。
我们把Linux内核内存中的VFS看作是磁盘等慢速介质中特定文件系统的缓存,这是一个典型的 分级存储结构, 就好像CPU cache和内存的关系一样。
在这个视角下,如何完成上图蓝色框框中的部分,可参考的现成范式就太多了。但无论如何都要解决的是:
哪些磁盘数据有资格进入到内存VFS的cache结构?
这些被cache的磁盘文件系统数据cache在什么地方?
cache的淘汰算法是怎样的?
Linux内核已经给了我们一个现成的答案:
磁盘IO依然遵循局部性原则,无论是时间局部性还是空间局部性,磁盘IO的局部性原则和磁盘结构(磁道,扇区等)以及启发式预读算法结合在一起,共同决定哪些数据要cache在内存。
磁盘数据以pagecache的形式保存在内存,当然你也可以DirectIO。
cache淘汰根据LRU以及系统内存的吃紧程度来进行实施。具体过程涉及脏页如何回写。
当然,如果你觉得这些不够好,你也可以设计你自己的。总之,这是一块非常独立的工作,正如我图中所示,这部分工作的目标是,在文件系统刚好可以工作后, 让事情变得更加完美有趣!
推荐阅读:
5T技术资源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,单片机,树莓派,等等。在公众号内回复「1024」,即可免费获取!!