
1W字带你用 200 行 JS 代码实现一个编译器


❝最近看到掘金、前端公众号好多 ES2020 的文章,想说一句:放开我,我还学得动!
❞
先问大家一句,日常项目开发中你能离开 ES6 吗?
一、前言
对于前端同学来说,编译器可能适合神奇的魔盒?,表面普通,但常常给我们惊喜。
编译器,顾名思义,用来编译,编译什么呢?当然是编译代码咯?。
其实我们也经常接触到编译器的使用场景:
React 中 JSX 转换成 JS 代码; 通过 Babel 将 ES6 及以上规范的代码转换成 ES5 代码; 通过各种 Loader 将 Less / Scss 代码转换成浏览器支持的 CSS 代码; 将 TypeScript 转换为 JavaScript 代码。 and so on...
使用场景非常之多,我的双手都数不过来了。?
虽然现在社区已经有非常多工具能为我们完成上述工作,但了解一些编译原理是很有必要的。接下来进入本文主题:「200行JS代码,带你实现代码编译器」。
二、编译器介绍
2.1 程序运行方式
现代程序主要有两种编译模式:静态编译和动态解释。推荐一篇文章《Angular 2 JIT vs AOT》介绍得非常详细。
静态编译
简称 「AOT」(Ahead-Of-Time)即 「提前编译」 ,静态编译的程序会在执行前,会使用指定编译器,将全部代码编译成机器码。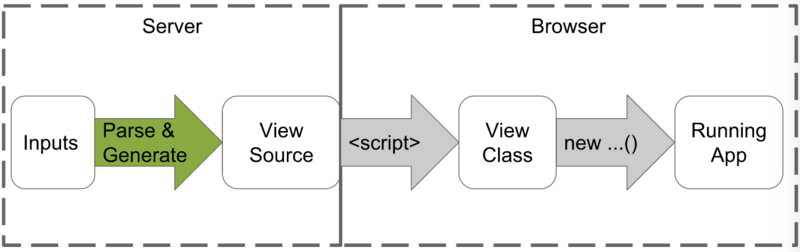
(图片来自:https://segmentfault.com/a/1190000008739157)
在 Angular 的 AOT 编译模式开发流程如下:
使用 TypeScript 开发 Angular 应用 运行 ngc 编译应用程序 使用 Angular Compiler 编译模板,一般输出 TypeScript 代码 运行 tsc 编译 TypeScript 代码 使用 Webpack 或 Gulp 等其他工具构建项目,如代码压缩、合并等 部署应用
动态解释
简称 「JIT」(Just-In-Time)即 「即时编译」 ,动态解释的程序会使用指定解释器,一边编译一边执行程序。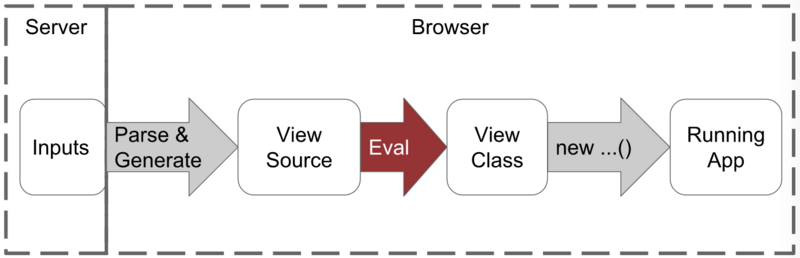 (图片来自:https://segmentfault.com/a/1190000008739157[1])
(图片来自:https://segmentfault.com/a/1190000008739157[1])
在 Angular 的 JIT 编译模式开发流程如下:
使用 TypeScript 开发 Angular 应用 运行 tsc 编译 TypeScript 代码 使用 Webpack 或 Gulp 等其他工具构建项目,如代码压缩、合并等 部署应用
AOT vs JIT
AOT 编译流程: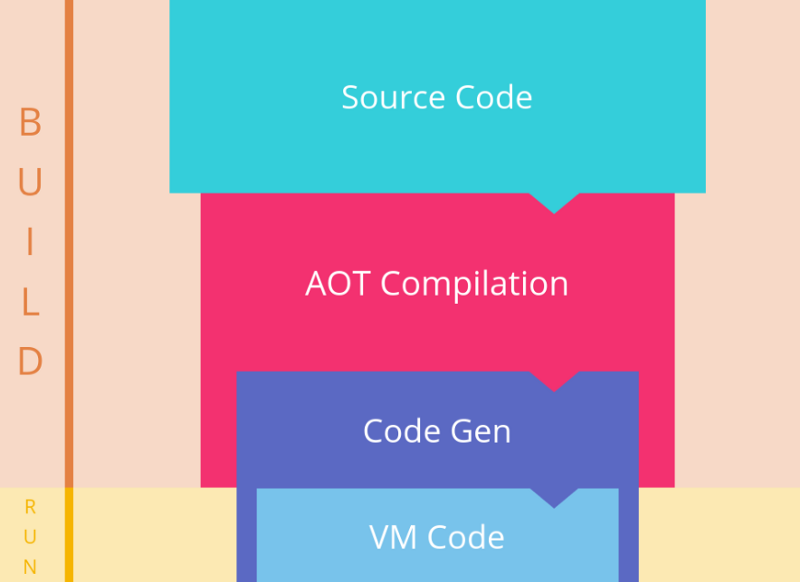 (图片来自:https://segmentfault.com/a/1190000008739157)
(图片来自:https://segmentfault.com/a/1190000008739157)
JIT 编译流程: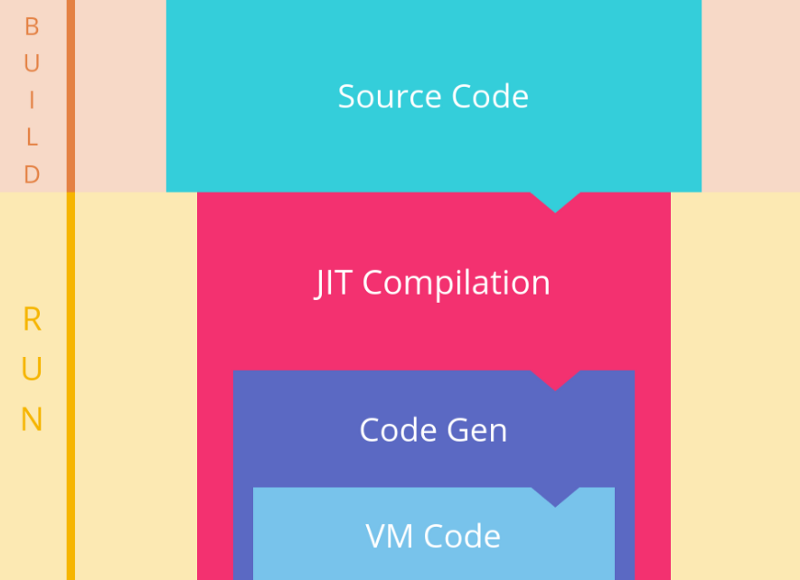 (图片来自:https://segmentfault.com/a/1190000008739157)
(图片来自:https://segmentfault.com/a/1190000008739157)
| 特性 | AOT | JIT |
|---|---|---|
| 编译平台 | (Server) 服务器 | (Browser) 浏览器 |
| 编译时机 | Build (构建阶段) | Runtime (运行时) |
| 包大小 | 较小 | 较大 |
| 执行性能 | 更好 | - |
| 启动时间 | 更短 | - |
除此之外 AOT 还有以下优点:
在客户端我们不需要导入体积庞大的 angular 编译器,这样可以减少我们 JS 脚本库的大小。 使用 AOT 编译后的应用,不再包含任何 HTML 片段,取而代之的是编译生成的 TypeScript 代码,这样的话 TypeScript 编译器就能提前发现错误。总而言之,采用 AOT 编译模式,我们的模板是类型安全的。
2.2 现代编译器工作流程
摘抄维基百科中对 编译器[2]工作流程介绍:
❝一个现代编译器的主要工作流程如下:源代码(source code)→ 预处理器(preprocessor)→ 编译器(compiler)→ 汇编程序(assembler)→ 目标代码(object code)→ 链接器(linker)→ 可执行文件(executables),最后打包好的文件就可以给电脑去判读运行了。
❞

这里更强调了编译器的作用:「将原始程序作为输入,翻译产生目标语言的等价程序」。
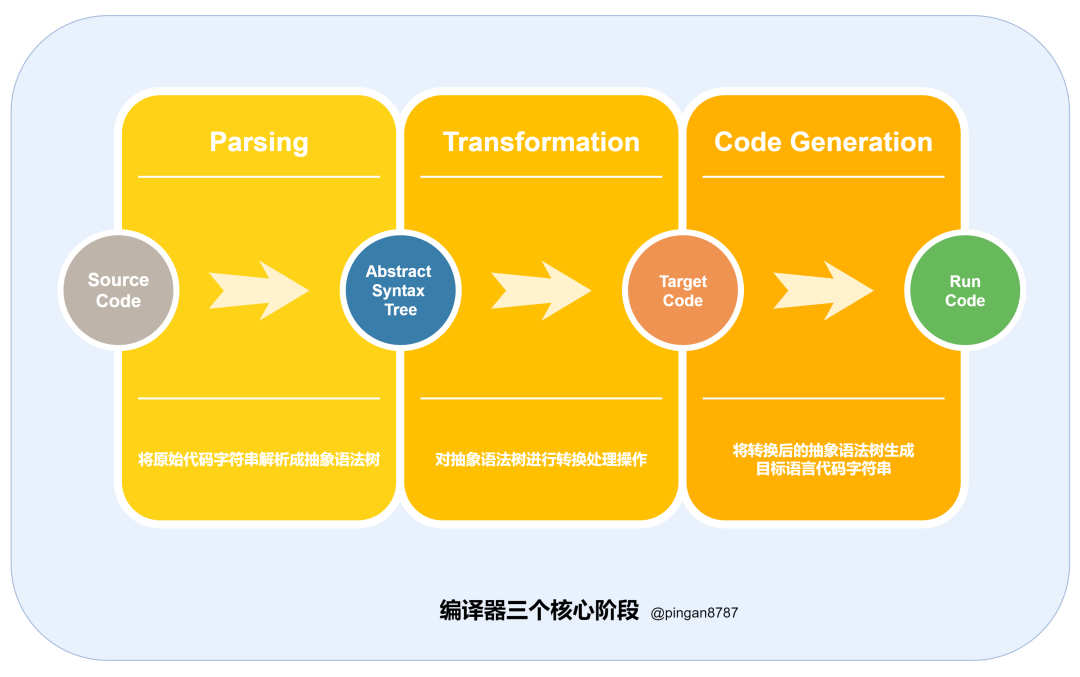
目前绝大多数现代编译器工作流程基本类似,包括三个核心阶段:
「解析(Parsing)」 :通过词法分析和语法分析,将原始代码字符串解析成「抽象语法树(Abstract Syntax Tree)」; 「转换(Transformation)」:对抽象语法树进行转换处理操作; 「生成代码(Code Generation)」:将转换之后的 AST 对象生成目标语言代码字符串。
三、编译器实现
本文将通过 「The Super Tiny Compiler[3]」 源码解读,学习如何实现一个轻量编译器,最终「实现将下面原始代码字符串(Lisp 风格的函数调用)编译成 JavaScript 可执行的代码」。
| Lisp 风格(编译前) | JavaScript 风格(编译后) | |
|---|---|---|
| 2 + 2 | (add 2 2) | add(2, 2) |
| 4 - 2 | (subtract 4 2) | subtract(4, 2) |
| 2 + (4 - 2) | (add 2 (subtract 4 2)) | add(2, subtract(4, 2)) |
话说 The Super Tiny Compiler 号称「可能是有史以来最小的编译器」,并且其作者 James Kyle 也是 Babel 活跃维护者之一。
让我们开始吧~
3.1 The Super Tiny Compiler 工作流程
现在对照前面编译器的三个核心阶段,了解下 The Super Tiny Compiler 编译器核心工作流程: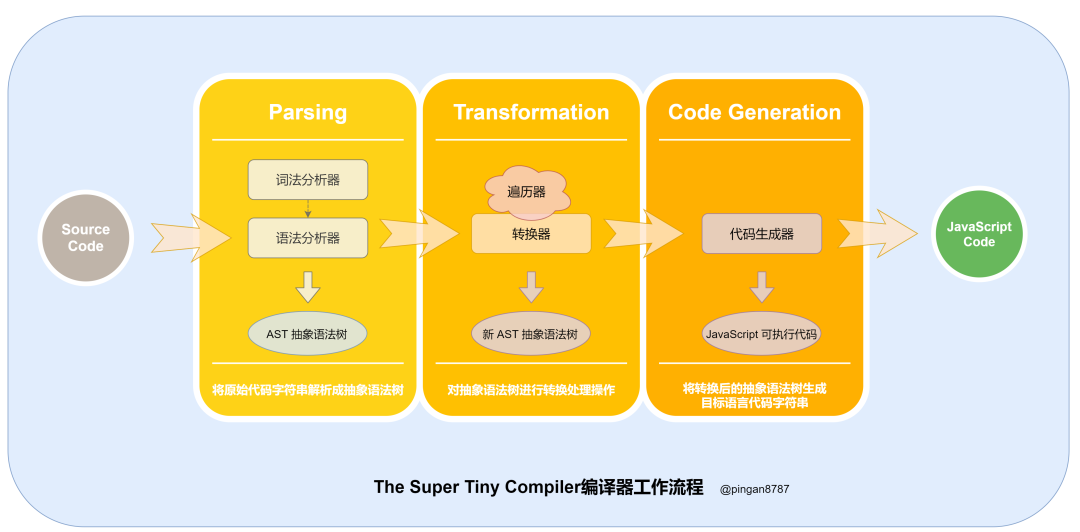
图中详细流程如下:
执行「入口函数」,输入「原始代码字符串」作为参数;
// 原始代码字符串
(add 2 (subtract 4 2))
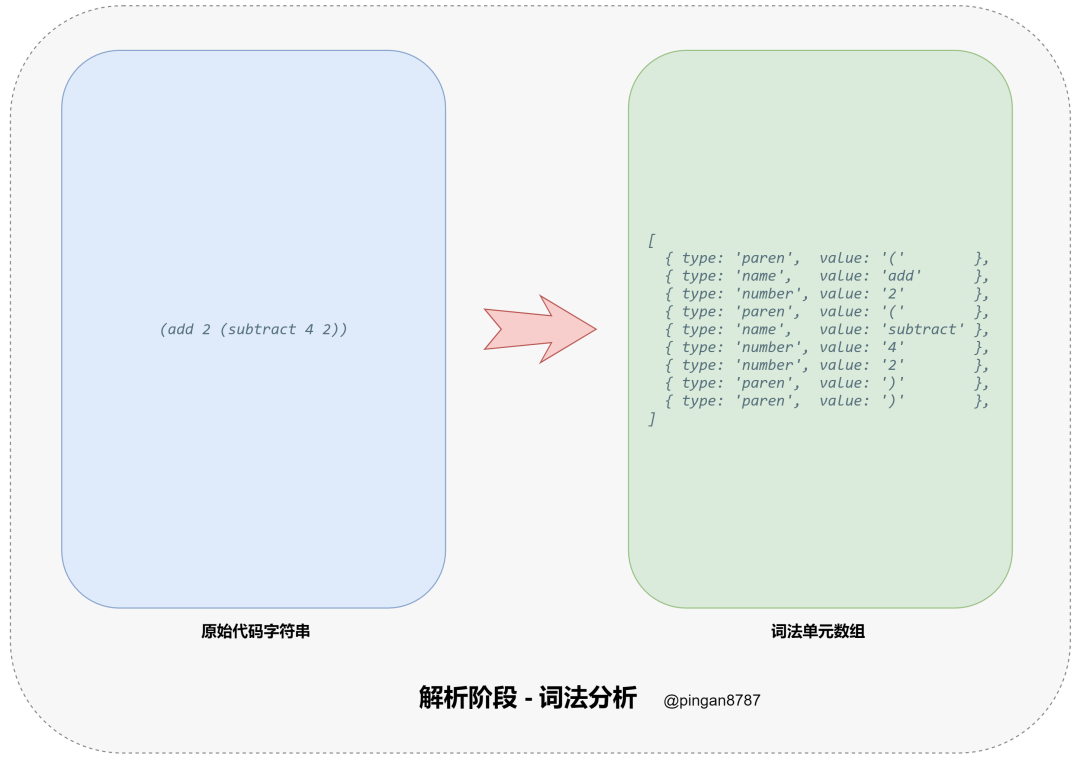
进入「解析阶段(Parsing)」,原始代码字符串通过「词法分析器(Tokenizer)」转换为「词法单元数组」,然后再通过 「词法分析器(Parser)」将「词法单元数组」转换为「抽象语法树(Abstract Syntax Tree 简称 AST)」,并返回;

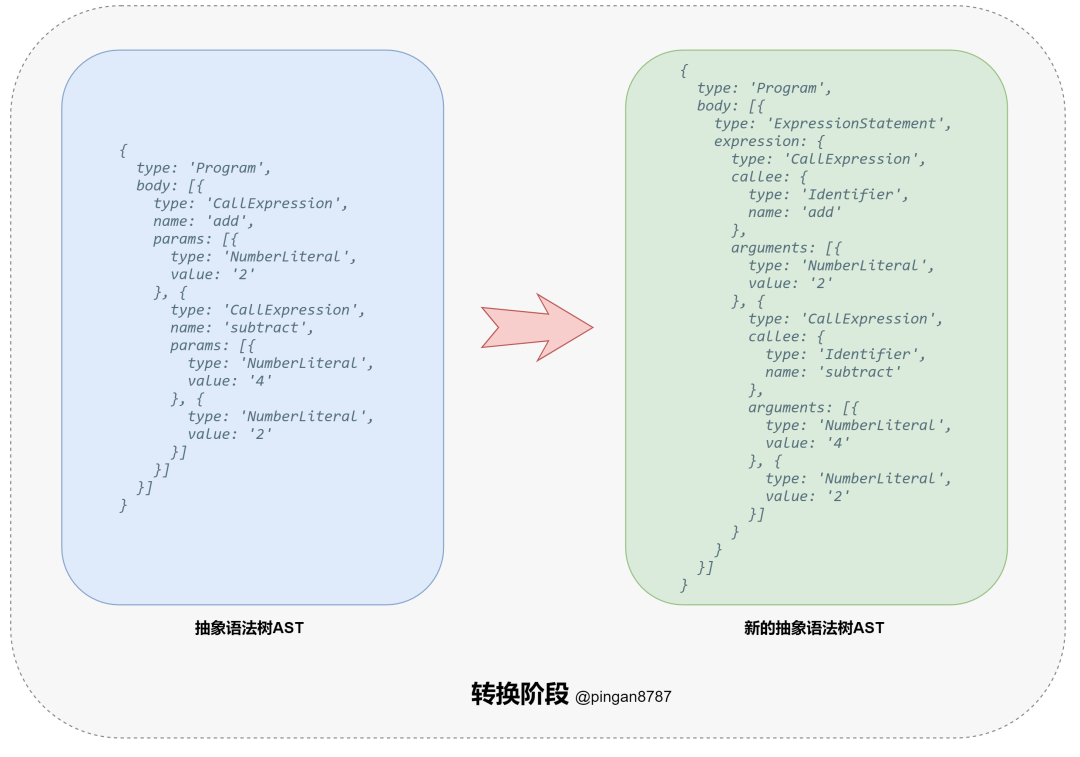
进入「转换阶段(Transformation)」,将上一步生成的 「AST 对象」 导入「转换器(Transformer)」,通过「转换器」中的「遍历器(Traverser)」,将代码转换为我们所需的「新的 AST 对象」;
进入「代码生成阶段(Code Generation)」,将上一步返回的「新 AST 对象」通过「代码生成器(CodeGenerator)」,转换成 「JavaScript Code」;
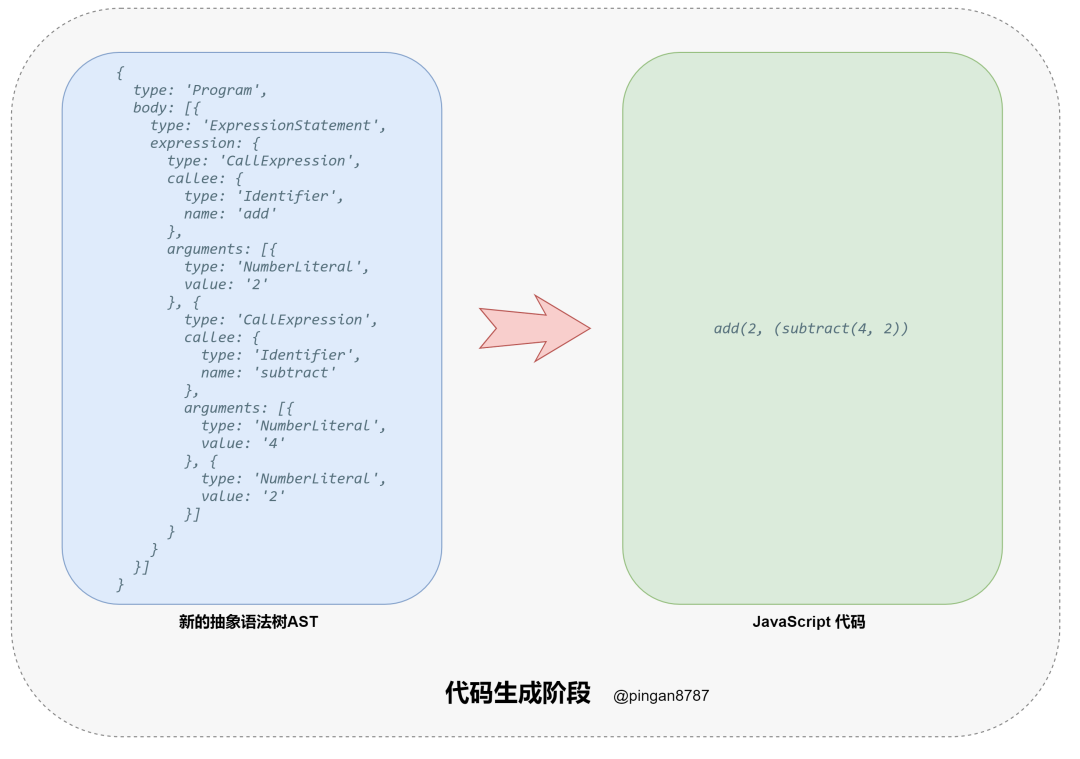
「代码编译结束」,返回 「JavaScript Code」。

上述流程看完后可能一脸懵逼,不过没事,请保持头脑清醒,先有个整个流程的印象,接下来我们开始阅读代码:
3.2 入口方法
首先定义一个入口方法 compiler ,接收原始代码字符串作为参数,返回最终 JavaScript Code:
// 编译器入口方法 参数:原始代码字符串 input
function compiler(input) {
let tokens = tokenizer(input);
let ast = parser(tokens);
let newAst = transformer(ast);
let output = codeGenerator(newAst);
return output;
}3.3 解析阶段
在解析阶段中,我们定义「词法分析器方法」 tokenizer 和「语法分析器方法」 parser 然后分别实现:
// 词法分析器 参数:原始代码字符串 input
function tokenizer(input) {};
// 语法分析器 参数:词法单元数组tokens
function parser(tokens) {};词法分析器
「词法分析器方法」 tokenizer 的主要任务:遍历整个原始代码字符串,将原始代码字符串转换为「词法单元数组(tokens)」,并返回。
在遍历过程中,匹配每种字符并处理成「词法单元」压入「词法单元数组」,如当匹配到左括号( ( )时,将往「词法单元数组(tokens)「压入一个」词法单元对象」({type: 'paren', value:'('})。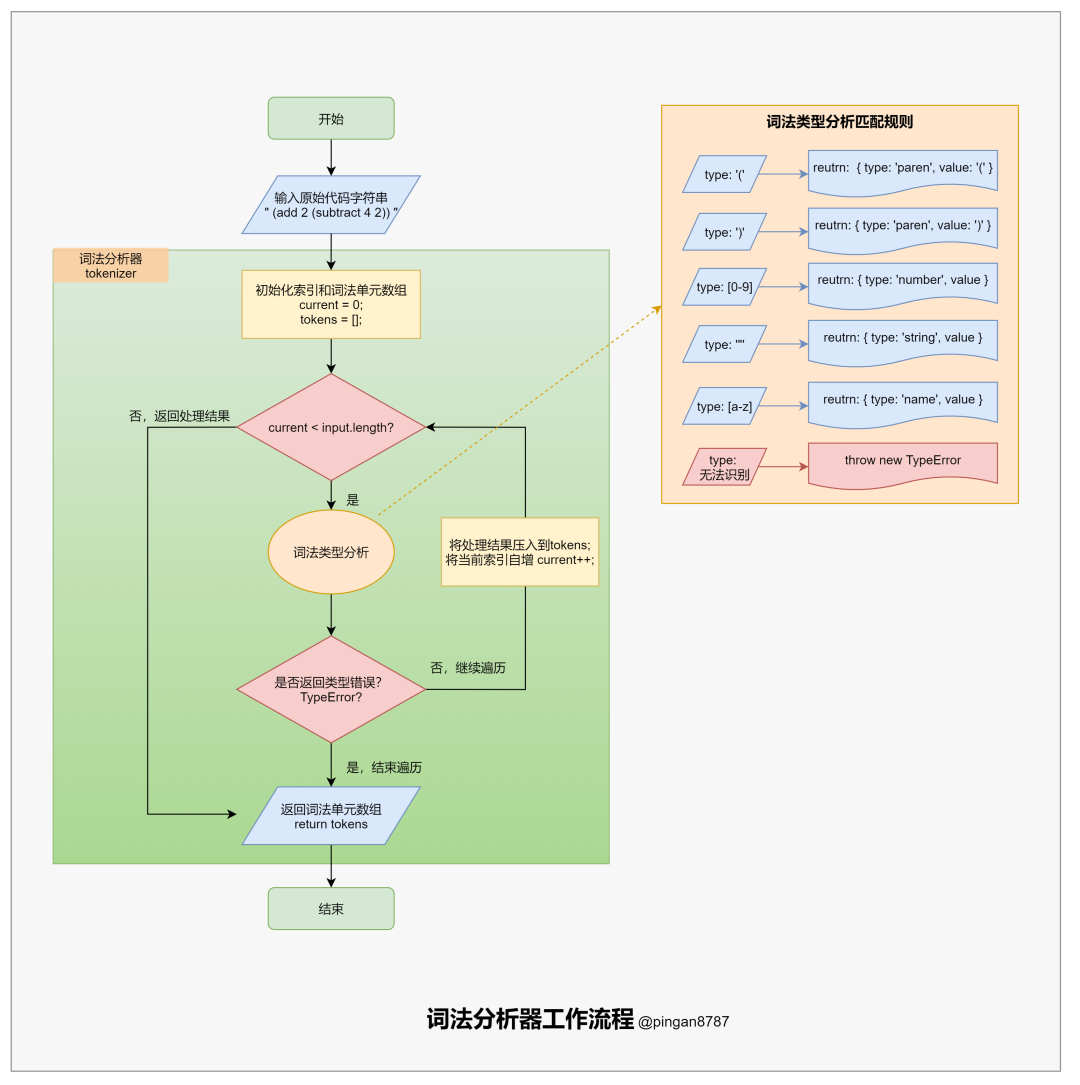
// 词法分析器 参数:原始代码字符串 input
function tokenizer(input) {
let current = 0; // 当前解析的字符索引,作为游标
let tokens = []; // 初始化词法单元数组
// 循环遍历原始代码字符串,读取词法单元数组
while (current < input.length) {
let char = input[current];
// 匹配左括号,匹配成功则压入对象 {type: 'paren', value:'('}
if (char === '(') {
tokens.push({
type: 'paren',
value: '('
});
current++;
continue; // 自增current,完成本次循环,进入下一个循环
}
// 匹配右括号,匹配成功则压入对象 {type: 'paren', value:')'}
if (char === ')') {
tokens.push({
type: 'paren',
value: ')'
});
current++;
continue;
}
// 匹配空白字符,匹配成功则跳过
// 使用 \s 匹配,包括空格、制表符、换页符、换行符、垂直制表符等
let WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 匹配数字字符,使用 [0-9]:匹配
// 匹配成功则压入{type: 'number', value: value}
// 如 (add 123 456) 中 123 和 456 为两个数值词法单元
let NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
// 匹配连续数字,作为数值
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'number', value });
continue;
}
// 匹配形双引号包围的字符串
// 匹配成功则压入 { type: 'string', value: value }
// 如 (concat "foo" "bar") 中 "foo" 和 "bar" 为两个字符串词法单元
if (char === '"') {
let value = '';
char = input[++current]; // 跳过左双引号
// 获取两个双引号之间所有字符
while (char !== '"') {
value += char;
char = input[++current];
}
char = input[++current];// 跳过右双引号
tokens.push({ type: 'string', value });
continue;
}
// 匹配函数名,要求只含大小写字母,使用 [a-z] 匹配 i 模式
// 匹配成功则压入 { type: 'name', value: value }
// 如 (add 2 4) 中 add 为一个名称词法单元
let LETTERS = /[a-z]/i;
if (LETTERS.test(char)) {
let value = '';
// 获取连续字符
while (LETTERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'name', value });
continue;
}
// 当遇到无法识别的字符,抛出错误提示,并退出
throw new TypeError('I dont know what this character is: ' + char);
}
// 词法分析器的最后返回词法单元数组
return tokens;
}语法分析器
「语法分析器方法」 parser 的主要任务:将「词法分析器」返回的「词法单元数组」,转换为能够描述语法成分及其关系的中间形式(「抽象语法树 AST」)。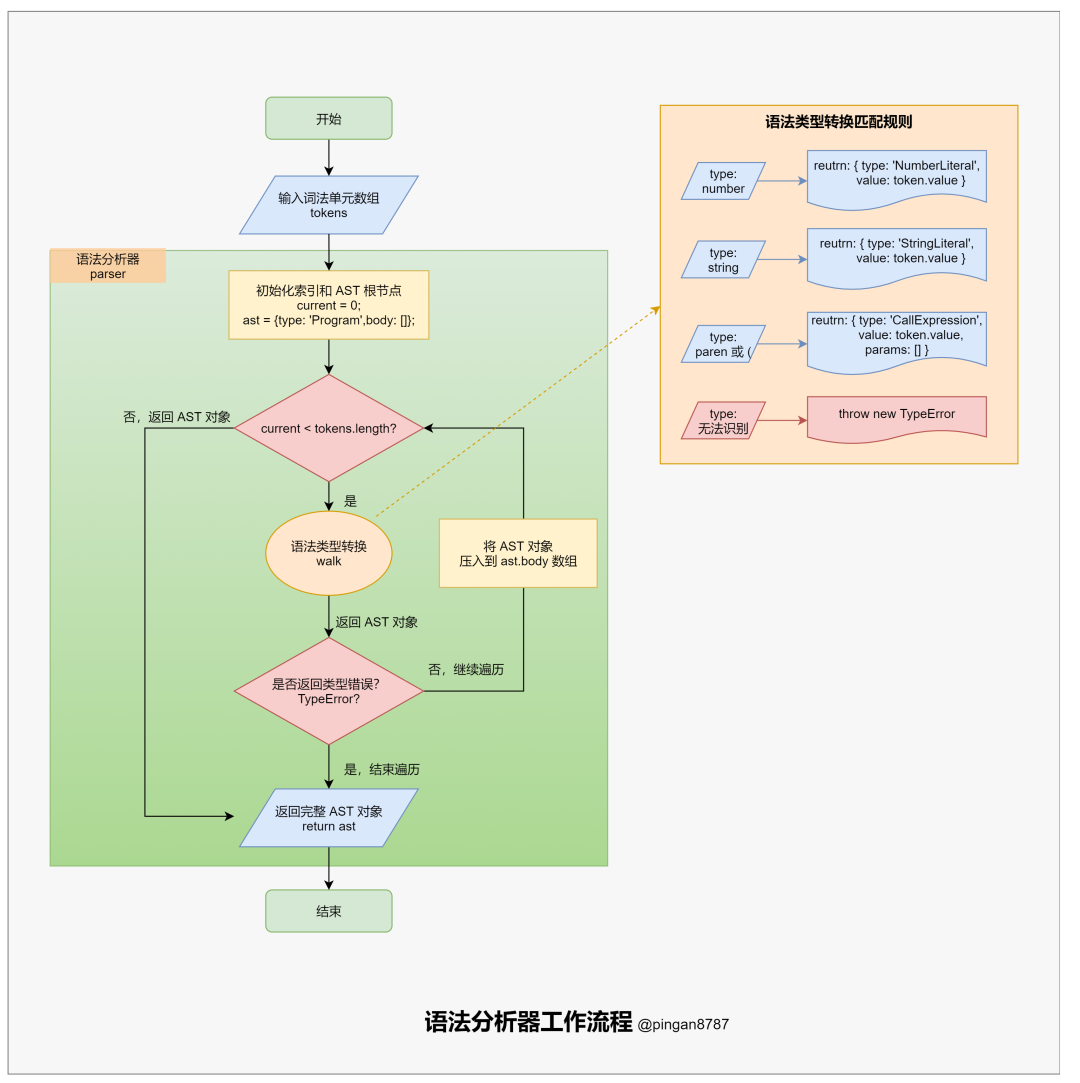
// 语法分析器 参数:词法单元数组tokens
function parser(tokens) {
let current = 0; // 设置当前解析的词法单元的索引,作为游标
// 递归遍历(因为函数调用允许嵌套),将词法单元转成 LISP 的 AST 节点
function walk() {
// 获取当前索引下的词法单元 token
let token = tokens[current];
// 数值类型词法单元
if (token.type === 'number') {
current++; // 自增当前 current 值
// 生成一个 AST节点 'NumberLiteral',表示数值字面量
return {
type: 'NumberLiteral',
value: token.value,
};
}
// 字符串类型词法单元
if (token.type === 'string') {
current++;
// 生成一个 AST节点 'StringLiteral',表示字符串字面量
return {
type: 'StringLiteral',
value: token.value,
};
}
// 函数类型词法单元
if (token.type === 'paren' && token.value === '(') {
// 跳过左括号,获取下一个词法单元作为函数名
token = tokens[++current];
let node = {
type: 'CallExpression',
name: token.value,
params: []
};
// 再次自增 current 变量,获取参数词法单元
token = tokens[++current];
// 遍历每个词法单元,获取函数参数,直到出现右括号")"
while ((token.type !== 'paren') || (token.type === 'paren' && token.value !== ')')) {
node.params.push(walk());
token = tokens[current];
}
current++; // 跳过右括号
return node;
}
// 无法识别的字符,抛出错误提示
throw new TypeError(token.type);
}
// 初始化 AST 根节点
let ast = {
type: 'Program',
body: [],
};
// 循环填充 ast.body
while (current < tokens.length) {
ast.body.push(walk());
}
// 最后返回ast
return ast;
}
3.4 转换阶段
在转换阶段中,定义了转换器 transformer 函数,使用词法分析器返回的 LISP 的 AST 对象作为参数,将 AST 对象转换成一个新的 AST 对象。
为了方便代码组织,我们定义一个遍历器 traverser 方法,用来处理每一个节点的操作。
// 遍历器 参数:ast 和 visitor
function traverser(ast, visitor) {
// 定义方法 traverseArray
// 用于遍历 AST节点数组,对数组中每个元素调用 traverseNode 方法。
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
// 定义方法 traverseNode
// 用于处理每个 AST 节点,接受一个 node 和它的父节点 parent 作为参数
function traverseNode(node, parent) {
// 获取 visitor 上对应方法的对象
let methods = visitor[node.type];
// 获取 visitor 的 enter 方法,处理操作当前 node
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
// 根节点
case 'Program':
traverseArray(node.body, node);
break;
// 函数调用
case 'CallExpression':
traverseArray(node.params, node);
break;
// 数值和字符串,忽略
case 'NumberLiteral':
case 'StringLiteral':
break;
// 当遇到无法识别的字符,抛出错误提示,并退出
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
}
// 首次执行,开始遍历
traverseNode(ast, null);
}
在看「遍历器」 traverser 方法时,建议结合下面介绍的「转换器」 transformer 方法阅读:
// 转化器,参数:ast
function transformer(ast) {
// 创建 newAST,与之前 AST 类似,Program:作为新 AST 的根节点
let newAst = {
type: 'Program',
body: [],
};
// 通过 _context 维护新旧 AST,注意 _context 是一个引用,从旧的 AST 到新的 AST。
ast._context = newAst.body;
// 通过遍历器遍历 处理旧的 AST
traverser(ast, {
// 数值,直接原样插入新AST,类型名称 NumberLiteral
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
});
},
},
// 字符串,直接原样插入新AST,类型名称 StringLiteral
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value,
});
},
},
// 函数调用
CallExpression: {
enter(node, parent) {
// 创建不同的AST节点
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
};
// 函数调用有子类,建立节点对应关系,供子节点使用
node._context = expression.arguments;
// 顶层函数调用算是语句,包装成特殊的AST节点
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression: expression,
};
}
parent._context.push(expression);
},
}
});
return newAst;
}
重要一点,这里通过 _context 引用来「维护新旧 AST 对象」,管理方便,避免污染旧 AST 对象。
3.5 代码生成
接下来到了最后一步,我们定义「代码生成器」 codeGenerator 方法,通过递归,将新的 AST 对象代码转换成 JavaScript 可执行代码字符串。
// 代码生成器 参数:新 AST 对象
function codeGenerator(node) {
switch (node.type) {
// 遍历 body 属性中的节点,且递归调用 codeGenerator,按行输出结果
case 'Program':
return node.body.map(codeGenerator)
.join('\n');
// 表达式,处理表达式内容,并用分号结尾
case 'ExpressionStatement':
return (
codeGenerator(node.expression) +
';'
);
// 函数调用,添加左右括号,参数用逗号隔开
case 'CallExpression':
return (
codeGenerator(node.callee) +
'(' +
node.arguments.map(codeGenerator)
.join(', ') +
')'
);
// 标识符,返回其 name
case 'Identifier':
return node.name;
// 数值,返回其 value
case 'NumberLiteral':
return node.value;
// 字符串,用双引号包裹再输出
case 'StringLiteral':
return '"' + node.value + '"';
// 当遇到无法识别的字符,抛出错误提示,并退出
default:
throw new TypeError(node.type);
}
}
3.6 编译器测试
截止上一步,我们完成简易编译器的代码开发。接下来通过前面原始需求的代码,测试编译器效果如何:
const add = (a, b) => a + b;
const subtract = (a, b) => a - b;
const source = "(add 2 (subtract 4 2))";
const target = compiler(source); // "add(2, (subtract(4, 2));"
const result = eval(target); // Ok result is 4
3.7 工作流程小结
总结 The Super Tiny Compiler 编译器整个工作流程:
「1、input => tokenizer => tokens」
「2、tokens => parser => ast」
「3、ast => transformer => newAst」
「4、newAst => generator => output」
其实多数编译器的工作流程都大致相同: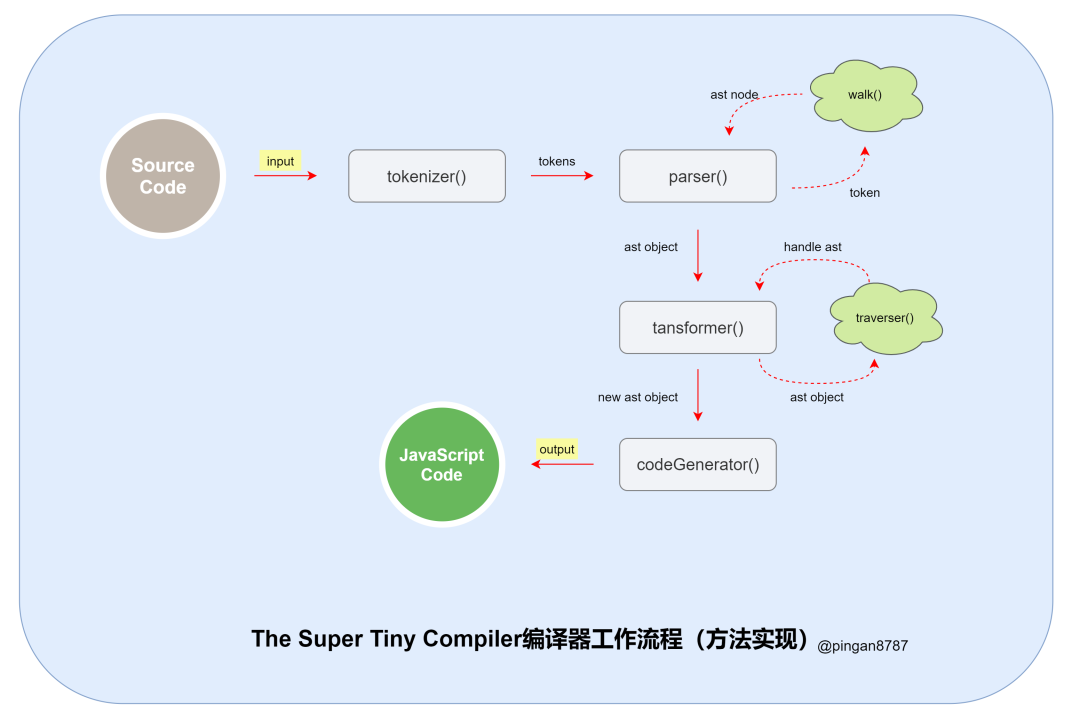
四、手写 Webpack 编译器
根据之前介绍的 The Super Tiny Compiler编译器核心工作流程,再来手写 Webpack 的编译器,会让你有种众享丝滑的感觉~
话说,有些面试官喜欢问这个呢。当然,手写一遍能让我们更了解 Webpack 的构建流程,这个章节我们简要介绍一下。
4.1 Webpack 构建流程分析
从启动构建到输出结果一系列过程:
「初始化参数」
解析 Webpack 配置参数,合并 Shell 传入和 webpack.config.js 文件配置的参数,形成最后的配置结果。
「开始编译」
上一步得到的参数初始化 compiler 对象,注册所有配置的插件,插件监听 Webpack 构建生命周期的事件节点,做出相应的反应,执行对象的 run 方法开始执行编译。
「确定入口」
从配置的 entry 入口,开始解析文件构建 AST 语法树,找出依赖,递归下去。
「编译模块」
递归中根据「文件类型」和 「loader 配置」,调用所有配置的 loader 对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。
「完成模块编译并输出」
递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据 entry 配置生成代码块 chunk 。
「输出完成」
输出所有的 chunk 到文件系统。
注意:在构建生命周期中有一系列插件在做合适的时机做合适事情,比如 UglifyPlugin 会在 loader 转换递归完对结果使用 UglifyJs 压缩「覆盖之前的结果」。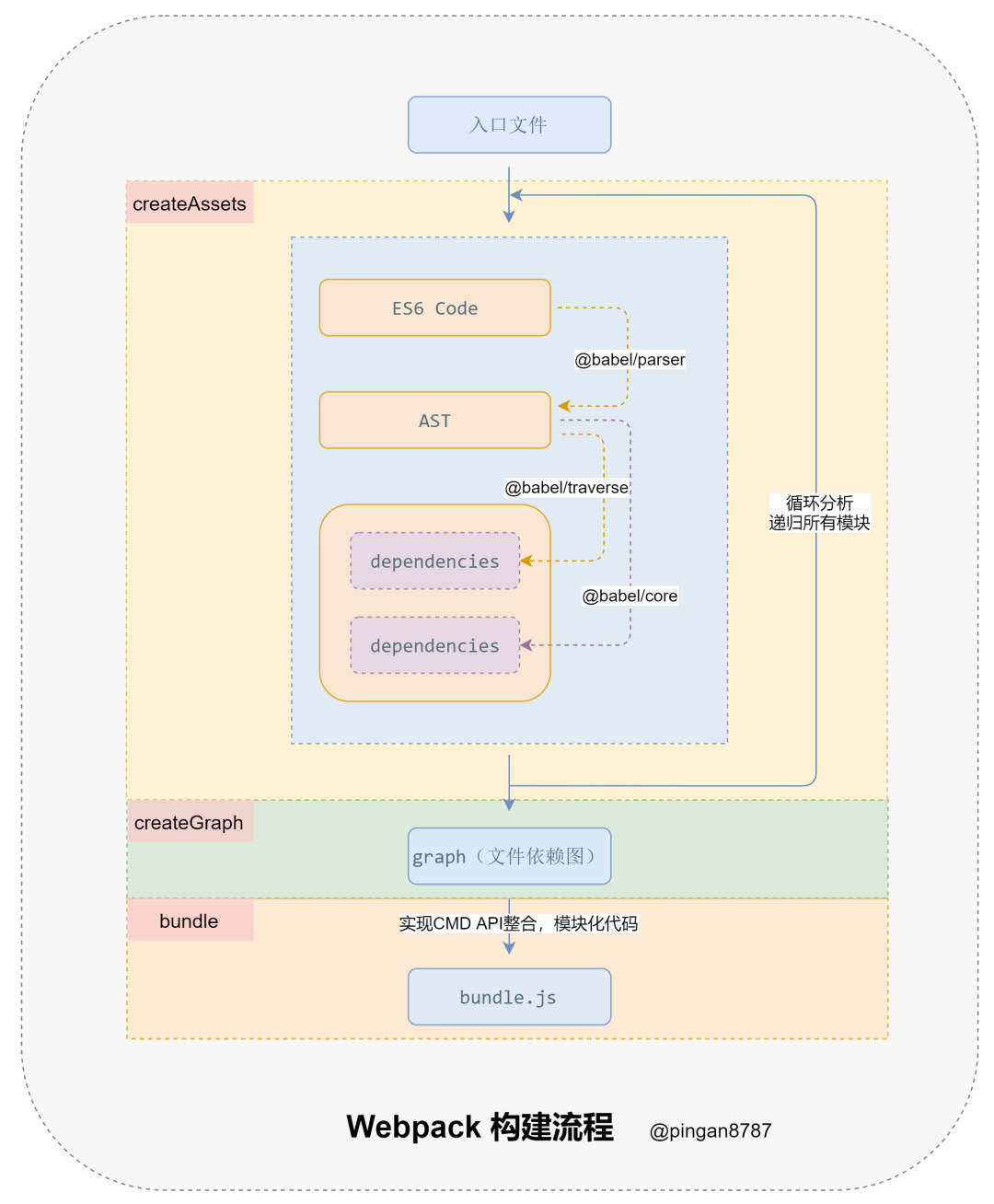
4.2 代码实现
手写 Webpack 需要实现以下三个核心方法:
createAssets: 收集和处理文件的代码;createGraph:根据入口文件,返回所有文件依赖图;bundle: 根据依赖图整个代码并输出;
1. createAssets
function createAssets(filename){
const content = fs.readFileSync(filename, "utf-8"); // 根据文件名读取文件内容
// 将读取到的代码内容,转换为 AST
const ast = parser.parse(content, {
sourceType: "module" // 指定源码类型
})
const dependencies = []; // 用于收集文件依赖的路径
// 通过 traverse 提供的操作 AST 的方法,获取每个节点的依赖路径
traverse(ast, {
ImportDeclaration: ({node}) => {
dependencies.push(node.source.value);
}
});
// 通过 AST 将 ES6 代码转换成 ES5 代码
const { code } = babel.transformFromAstSync(ast, null, {
presets: ["@babel/preset-env"]
});
let id = moduleId++;
return {
id,
filename,
code,
dependencies
}
}2. createGraph
function createGraph(entry) {
const mainAsset = createAssets(entry); // 获取入口文件下的内容
const queue = [mainAsset];
for(const asset of queue){
const dirname = path.dirname(asset.filename);
asset.mapping = {};
asset.dependencies.forEach(relativePath => {
const absolutePath = path.join(dirname, relativePath); // 转换文件路径为绝对路径
const child = createAssets(absolutePath);
asset.mapping[relativePath] = child.id;
queue.push(child); // 递归去遍历所有子节点的文件
})
}
return queue;
}3. bunlde
function bundle(graph) {
let modules = "";
graph.forEach(item => {
modules += `
${item.id}: [
function (require, module, exports){
${item.code}
},
${JSON.stringify(item.mapping)}
],
`
})
return `
(function(modules){
function require(id){
const [fn, mapping] = modules[id];
function localRequire(relativePath){
return require(mapping[relativePath]);
}
const module = {
exports: {}
}
fn(localRequire, module, module.exports);
return module.exports;
}
require(0);
})({${modules}})
`
}
五、总结
本文从编译器概念和基本工作流程开始介绍,然后通过 The Super Tiny Compiler 译器源码,详细介绍核心工作流程实现,包括「词法分析器」、「语法分析器」、「遍历器」和「转换器」的基本实现,最后通过「代码生成器」,将各个阶段代码结合起来,实现了这个号称「可能是有史以来最小的编译器。」
本文也简要介绍了「手写 Webpack 的实现」,需要读者自行完善和深入哟!
「是不是觉得很神奇~」
当然通过本文学习,也仅仅是编译器相关知识的边山一脚,要学的知识还有非常多,不过好的开头,更能促进我们学习动力。加油!
最后,文中介绍到的代码,我存放在 Github 上:
[learning]the-super-tiny-compiler.js[4] [writing]webpack-compiler.js[5]
六、参考资料
《The Super Tiny Compiler》[6] 《有史以来最小的编译器源码解析》[7] 《Angular 2 JIT vs AOT》[8]
Reference
https://segmentfault.com/a/1190000008739157: https://segmentfault.com/a/1190000008739157
[2]编译器: https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E5%99%A8?wprov=srpw1_0
[3]The Super Tiny Compiler: https://the-super-tiny-compiler.glitch.me/
[4][learning]the-super-tiny-compiler.js: https://github.com/pingan8787/Leo-JavaScript/blob/master/Cute-Frontend/learningSourceCode/%5Blearning%5Dthe-super-tiny-compiler.js
[5][writing]webpack-compiler.js: https://github.com/pingan8787/Leo-JavaScript/blob/master/Cute-Frontend/learningSourceCode/%5Bwriting%5Dwebpack-compiler.js
[6]《The Super Tiny Compiler》: https://the-super-tiny-compiler.glitch.me/
[7]《有史以来最小的编译器源码解析》: https://segmentfault.com/a/1190000016402699
[8]《Angular 2 JIT vs AOT》: https://segmentfault.com/a/1190000008739157
END