
Python爬虫+颜值打分,5000+图片找到你的Mrs. Right

一见钟情钟的不是情,是脸日久生情生的不是脸,是情
项目简介
本项目利用Python爬虫和百度人脸识别API,针对简书交友专栏,爬取用户照片(侵删),并进行打分。本项目包括以下内容:
图片爬虫
人脸识别API使用
颜值打分并进行文件归类
图片爬虫
现在各大交友网站都会有一些用户会爆照,本文爬取简书交友专栏(https://www.jianshu.com/c/bd38bd199ec6)的所有帖子,并进入详细页,获取所有图片并下载到本地。
代码
import requests
from lxml import etree
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
def get_url(url):
res = requests.get(url,headers=headers)
html = etree.HTML(res.text)
infos = html.xpath('//ul[@class="note-list"]/li')
for info in infos:
root = 'https://www.jianshu.com'
url_path = root + info.xpath('div/a/@href')[0]
# print(url_path)
get_img(url_path)
time.sleep(3)
def get_img(url):
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
title = html.xpath('//div[@class="article"]/h1/text()')[0].strip('|').split(',')[0]
name = html.xpath('//div[@class="author"]/div/span/a/text()')[0].strip('|')
infos = html.xpath('//div[@class = "image-package"]')
i = 1
for info in infos:
try:
img_url = info.xpath('div[1]/div[2]/img/@data-original-src')[0]
print(img_url)
data = requests.get('http:' + img_url,headers=headers)
try:
fp = open('row_img/' + title + '+' + name + '+' + str(i) + '.jpg','wb')
fp.write(data.content)
fp.close()
except OSError:
fp = open('row_img/' + name + '+' + str(i) + '.jpg', 'wb')
fp.write(data.content)
fp.close()
except IndexError:
pass
i = i + 1
if __name__ == '__main__':
urls = ['https://www.jianshu.com/c/bd38bd199ec6?order_by=added_at&page={}'.format(str(i)) for i in range(1,201)]
for url in urls:
get_url(url)
人脸识别API使用
由于爬取了帖子下面的所有图片,里面有各种图片(不包括人脸),而且是为了找到高颜值小姐姐,如果人工筛选费事费力,这里调用百度的人脸识别API,进行图片过滤和颜值打分。
人脸识别应用申请
首先,进入百度人脸识别官网(http://ai.baidu.com/tech/face),点击立即使用,登陆百度账号(没有就注册一个)。
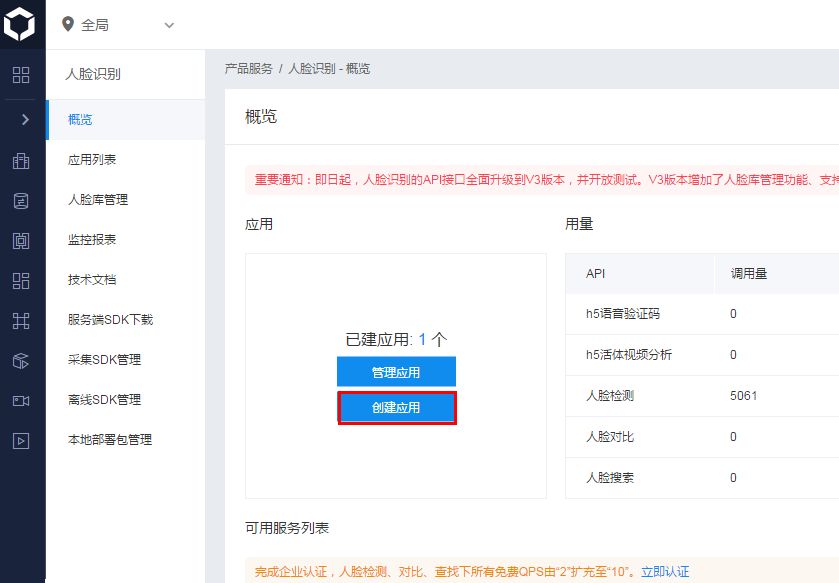
创建应用,完成后,点击管理应用,就能看到AppID等,这些在调用API时需要使用的。

API调用
这里使用杨超越的图片先试下水。通过结果,可以看到75分,还算比较高了(自己用了一些网红和明星测试了下,分数平均在80左右,最高也没有90以上的)。

from aip import AipFace
import base64
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
aipFace = AipFace(APP_ID, API_KEY, SECRET_KEY)
filePath = r'C:\Users\LP\Desktop\6.jpg'
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
content = base64.b64encode(fp.read())
return content.decode('utf-8')
imageType = "BASE64"
options = {}
options["face_field"] = "age,gender,beauty"
result = aipFace.detect(get_file_content(filePath),imageType,options)
print(result)

颜值打分并进行文件归类
最后结合图片数据和颜值打分,设计代码,过滤掉非人物以及男性图片,获取小姐姐图片的分数(这里处理为1-10分),并分别存在不同的文件夹中。
from aip import AipFace
import base64
import os
import time
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
aipFace = AipFace(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
content = base64.b64encode(fp.read())
return content.decode('utf-8')
imageType = "BASE64"
options = {}
options["face_field"] = "age,gender,beauty"
file_path = 'row_img'
file_lists = os.listdir(file_path)
for file_list in file_lists:
result = aipFace.detect(get_file_content(os.path.join(file_path,file_list)),imageType,options)
error_code = result['error_code']
if error_code == 222202:
continue
try:
sex_type = result['result']['face_list'][-1]['gender']['type']
if sex_type == 'male':
continue
# print(result)
beauty = result['result']['face_list'][-1]['beauty']
new_beauty = round(beauty/10,1)
print(file_list,new_beauty)
if new_beauty >= 8:
os.rename(os.path.join(file_path,file_list),os.path.join('8分',str(new_beauty) + '+' + file_list))
elif new_beauty >= 7:
os.rename(os.path.join(file_path,file_list),os.path.join('7分',str(new_beauty) + '+' + file_list))
elif new_beauty >= 6:
os.rename(os.path.join(file_path,file_list),os.path.join('6分',str(new_beauty) + '+' + file_list))
elif new_beauty >= 5:
os.rename(os.path.join(file_path,file_list),os.path.join('5分',str(new_beauty) + '+' + file_list))
else:
os.rename(os.path.join(file_path,file_list),os.path.join('其他分',str(new_beauty) + '+' + file_list))
time.sleep(1)
except KeyError:
pass
except TypeError:
pass
最后结果8分以上的小姐姐很少,如图(侵删)。

讨论
简书交友小姐姐数量较少,读者可以去试试微博网红或知乎美女。
虽然这是一个看脸的时代,但喜欢一个人,始于颜值,陷于才华,忠于人品
左手Python,右手Java,升职就业不愁啦!
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案

点阅读原文,领AI全套资料!
