
OpenCV DNN支持的对象检测模型
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:opencv学堂
OpenCV DNN不光支持图像分类,对象检测作为计算机视觉主要任务之一,OpenCV DNN支持多种对象检测模型,可以快速实现基于COCO数据集与Pascal VOC数据集的对象检测。此外基于自定义数据集,通过tensorflow对象检测框架或者pytorch的ONNX格式还可以支持自定义对象检测模型训练导出与部署。本文总结了OpenCV DNN支持的各种对象检测模型与它们的输入输出。
SSD对象检测模型的全称是Single Shot MultiBox Detector,是一阶段的对象检测网络,基于回归思想在多个特征层实现对象检测,其主要的思想可以用下面一张图表示:

可以看出越是分辨率大的对象在高层特征抽象上毕竟容易被预测检测,分辨率小的对象在底层特征会被检测,如果分辨率过小则有可能无法检测,所以SSD对象检测是对微小目标检测效果不佳的对象检测方法,根据使用的特征网络不同可以分为VGG-SSD,MobileNet-SSD等,下图是基于VGG16的SSD对象检测网络模型结构:
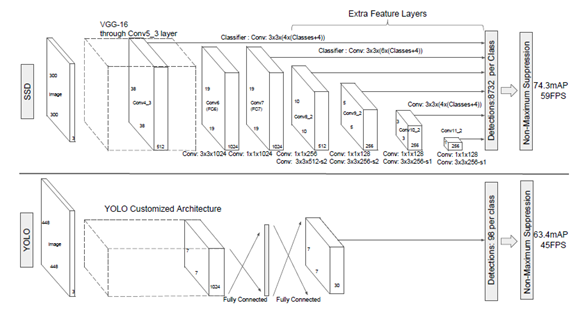
OpenCV DNN支持SSD-VGG, SSD-MobileNet两种SSD对象检测模型。
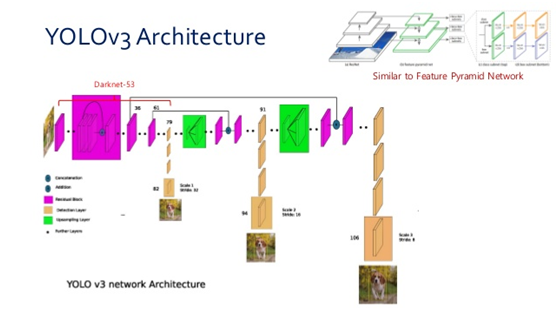
YOLO对象检测模型得全称是You Only Look Once,也是一阶段得对象检测模型。最初的YOLO对象检测模型跟SSD对象检测模型相比,它只有一个输出层,无法实现多分辨率特征的预测,虽然速度很快,但是精度不够,后来改进的YOLOv2,YOLOv3,YOLOv4都具有多个输出层,实现了多尺度的对象检测,检测精度跟准确率得到提高。YOLO网络结构
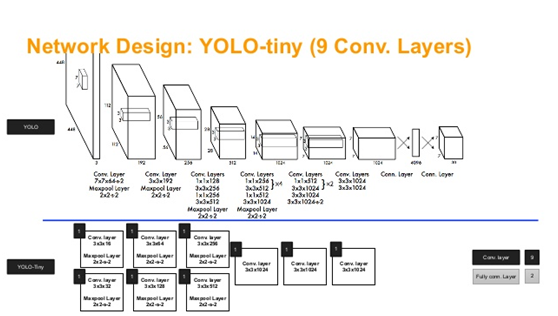
多个输出层。OpenCV DNN模块支持最新版本的YOLOv4对象检测模型部署,同时还支持Tiny-YOLO网络。

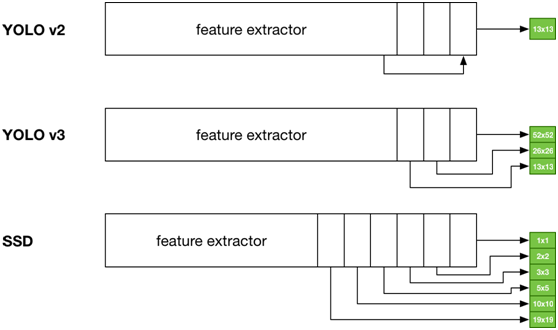
YOLOv2与YOLOv3版本模型跟SSD模型之间的输出对比
Faster-RCNN是典型的两阶段对象检测网络,基于RPN实现区域推荐,

网络结构如下:

该模型也是两阶段网络,在输出时候多出了一个实例分割的分支,但是该实例分割严格意义上来说并没有进行上采样,不是pixelwise的实例分割模型,可以看成是blockwise/patch wise的实例分割输出。整个网络结构跟Faster-RCNN很相似,网络模型结构如下:
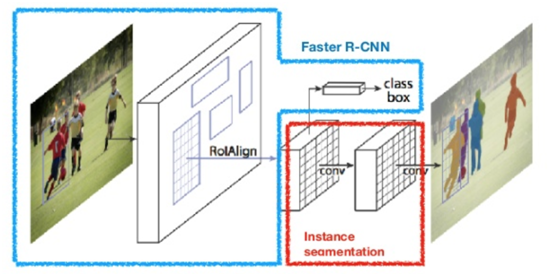
OpenCV支持Caffe与Tensorflow Object DetectionAPI中的mask-rcnn模型部署推理。
2016年提出的对象检测网络,全称为Region-based Fully Convolutional Network (R-FCN)其核心思想是基于全卷积神经网络生成一个3x3的位置敏感卷积实现对位置信息编码,完成预测,实现对象检测。

该网络同样是两阶段的对象检测网络,模型架构如下:
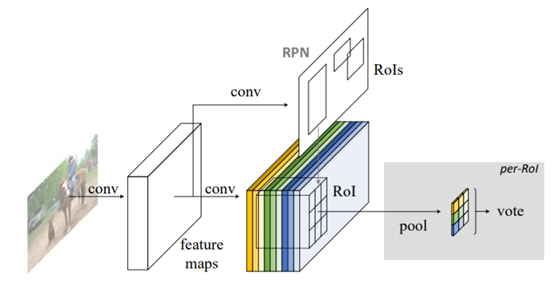
位置敏感ROI矩形解码

该模型是一阶段的对象检测网络,在2019年提出,tensorflow2.x的对象检测网络框架支持的网络模型。模型的结构如下:

基于EfficientNet网络作为基础网络,使用多尺度双向金字塔特征融合技术,其中权重特征融合使用了交叉尺度链接与权重快速归一化融合。下图是普通的金字塔特征融合到双向金字塔特征融合各种方法:
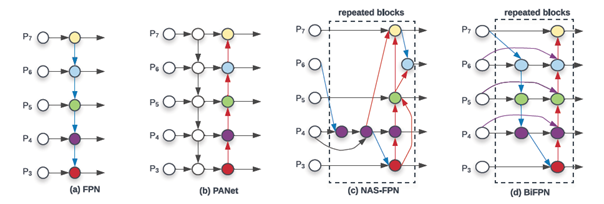
对,你没看错,OpenCV4.4最新版本支持该模型。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~