
谷歌打怪升级之路:从EfficientNet到EfficientNetV2(上)
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
EfficientNet是继ResNet之后又一个大众所熟知的CNN网络,谷歌在19年提出的EfficientNet无论是效果,参数量还是速度均大幅度超越之前的网络,EfficientNet背后的主要设计是采用了复合缩放策略(Compound Model Scaling),其统一地缩放模型的三个维度(depth,width,resolution)。在21年4月,谷歌团队又提出了优化版本EfficientNetV2,相比V1版本,其参数量更小,但训练速度更快。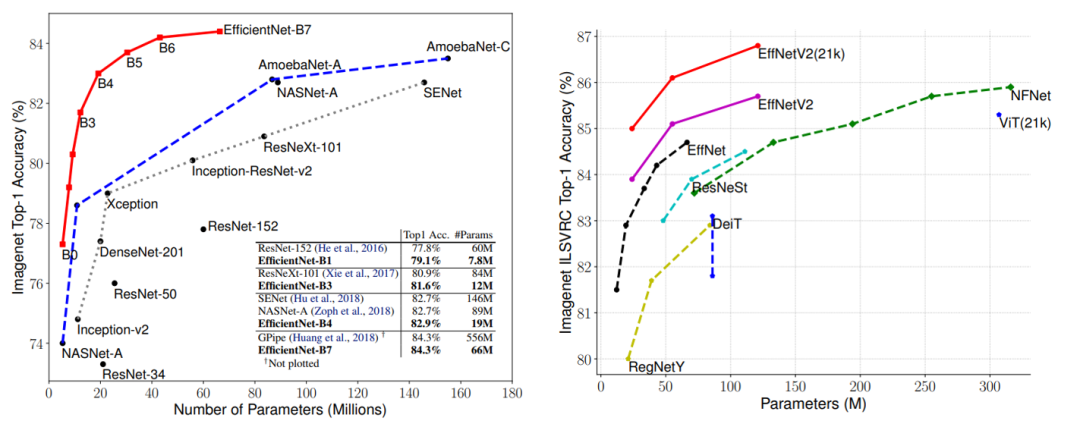
EfficientNet
对于一个CNN网络来说,影响模型参数大小和速度的主要有三个方面:depth,width,resolution (image size)。depth指的是模型的深度,即网络的层数,网络越深,感受野越大,提取的特征语义越强;width指的是网络特征维度大小(channels),特征维度越大,模型的表征能力越强;resolution指的是网络的输入图像大小,即HxW,输入图像分辨率越大,越有利于提出更细粒度特征。depth和width影响模型参数大小和速度,但是resolution只影响模型速度(分辨率越大,计算量越大)。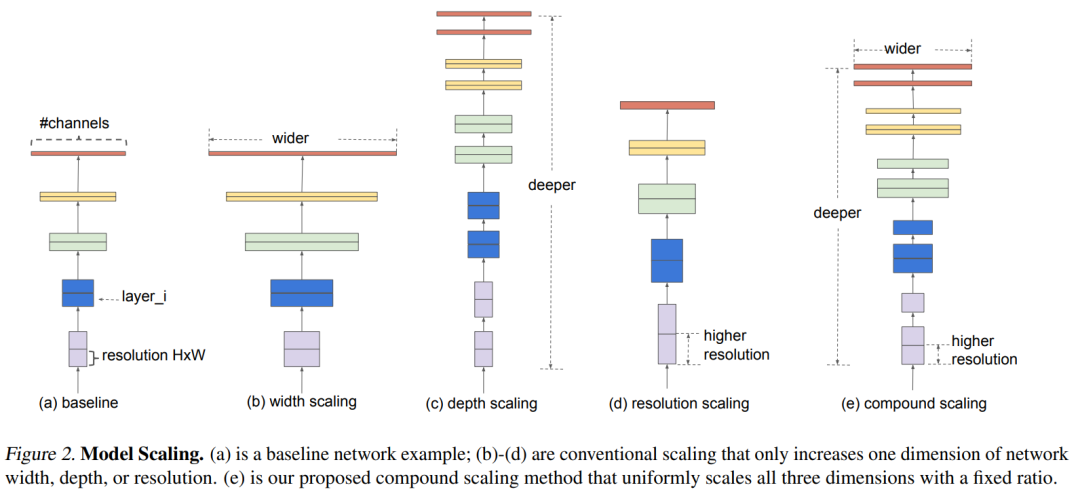 对于model scaling,也是通过scale这三个方面来实现的,上图中b,c和d分别是对三个方面进行scaling。但是之前的工作主要是调节这三个方面中的某一个方面来实现model scaling,如ResNet50到ResNet101只是增加了网络的深度depth,而WidResNet是调整网络的width。论文中发现,如果单纯地只对某一个方面scaling,随着模型增大,性能会很快达到瓶颈,如下图所示,对于baseline model,分别单独缩放模型的depth,width,resolution,随着模型变大,性能提升会很快饱和。
对于model scaling,也是通过scale这三个方面来实现的,上图中b,c和d分别是对三个方面进行scaling。但是之前的工作主要是调节这三个方面中的某一个方面来实现model scaling,如ResNet50到ResNet101只是增加了网络的深度depth,而WidResNet是调整网络的width。论文中发现,如果单纯地只对某一个方面scaling,随着模型增大,性能会很快达到瓶颈,如下图所示,对于baseline model,分别单独缩放模型的depth,width,resolution,随着模型变大,性能提升会很快饱和。
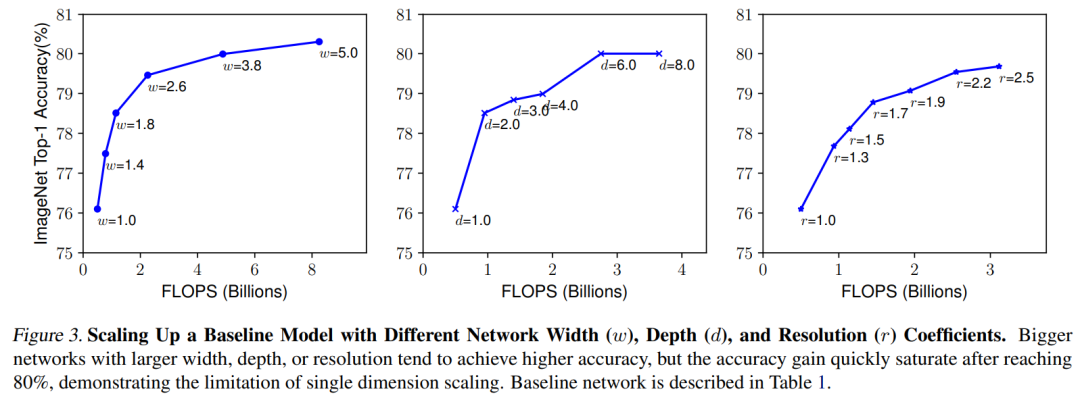 直观上看,如果模型的输入图片分辨率增加,那么应该同时增加模型深度来增大感受野以提取同样范围大小的特征,相应地,也应该增加模型width来捕获更细粒度的特征。所以说,理论上最好统一地对三个方面进行scaling,而不是只针对某一个方面。论文中对比了不同depth和resolution下的对width进行缩放的模型效果,如下图所示,对于d=1.0和r=1.0就是只改变width,可以看到模型效果很快达到瓶颈,但是如果设置更大的depth和resolution(d=2.0和r=1.3),对width进行缩放能取得更好的效果。
直观上看,如果模型的输入图片分辨率增加,那么应该同时增加模型深度来增大感受野以提取同样范围大小的特征,相应地,也应该增加模型width来捕获更细粒度的特征。所以说,理论上最好统一地对三个方面进行scaling,而不是只针对某一个方面。论文中对比了不同depth和resolution下的对width进行缩放的模型效果,如下图所示,对于d=1.0和r=1.0就是只改变width,可以看到模型效果很快达到瓶颈,但是如果设置更大的depth和resolution(d=2.0和r=1.3),对width进行缩放能取得更好的效果。
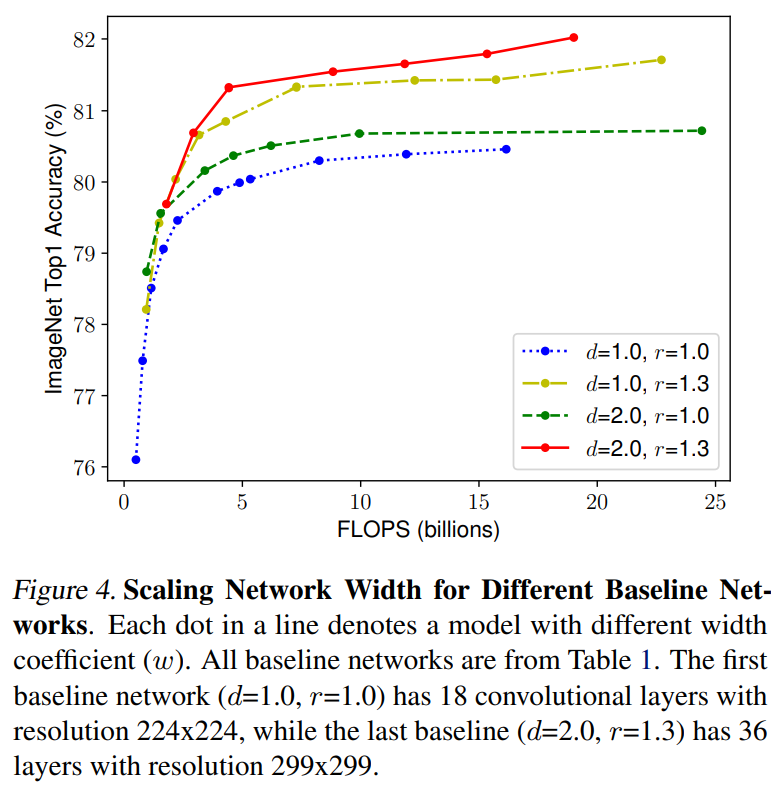 此外,为了实现更好的效果和模型效率,也应该要平衡网络的三个方面,让模型各个方面均衡发展。据此,论文提出了一种复合缩放策略( compound scaling ),即通过一个统一的系数来均衡地缩放depth,width,resolution,这里限制如下:
此外,为了实现更好的效果和模型效率,也应该要平衡网络的三个方面,让模型各个方面均衡发展。据此,论文提出了一种复合缩放策略( compound scaling ),即通过一个统一的系数来均衡地缩放depth,width,resolution,这里限制如下:
这里的是常量,分别表示depth,width和resolution三个方面的基础系数,这里只需要调整就可以实现模型的缩放。对于卷积操作,其FLOPS一般和成正比,如果depth变为2倍,那么计算量也变为2倍,但是width和resolution变为2倍的话,计算量变为4倍。对于baseline模型,其系数,当采用一个新的系数对模型进行缩放时,模型的FLOPS将变为baseline模型的,这里限制了,所以FLOPS就近似增加了。
论文中通过一个多目标的NAS来得到baseline模型(借鉴MnasNet),这里优化的目标是模型的ACC和FLOPS,其中target FLOPS是400M,最终得到了EfficientNet-B0模型,其模型架构如下表所示: 可以看到EfficientNet-B0的输入大小为224x224,首先是一个stride=2的3x3卷积层,最后是一个1x1卷积+global pooling+FC分类层,其余的stage主体是MBConv,这个指的是MobileNetV2中提出的mobile inverted bottleneck block(conv1x1-> depthwise conv3x3->conv1x1+shortcut),唯一的区别是增加了SE结构来进行优化,表中的MBConv后面的数字表示的是expand_ratio(第一个1x1卷积要扩大channels的系数)。目前EfficientNet已经在torchvision中实现,这里给出MBConv的实现源码:
可以看到EfficientNet-B0的输入大小为224x224,首先是一个stride=2的3x3卷积层,最后是一个1x1卷积+global pooling+FC分类层,其余的stage主体是MBConv,这个指的是MobileNetV2中提出的mobile inverted bottleneck block(conv1x1-> depthwise conv3x3->conv1x1+shortcut),唯一的区别是增加了SE结构来进行优化,表中的MBConv后面的数字表示的是expand_ratio(第一个1x1卷积要扩大channels的系数)。目前EfficientNet已经在torchvision中实现,这里给出MBConv的实现源码:
class MBConv(nn.Module):
def __init__(self, cnf: MBConvConfig, stochastic_depth_prob: float, norm_layer: Callable[..., nn.Module],
se_layer: Callable[..., nn.Module] = SqueezeExcitation) -> None:
super().__init__()
if not (1 <= cnf.stride <= 2):
raise ValueError('illegal stride value')
# 只有stride=1且输入和输出channels相同时才有shortcut
self.use_res_connect = cnf.stride == 1 and cnf.input_channels == cnf.out_channels
layers: List[nn.Module] = []
activation_layer = nn.SiLU
# expand
expanded_channels = cnf.adjust_channels(cnf.input_channels, cnf.expand_ratio)
if expanded_channels != cnf.input_channels:
layers.append(ConvBNActivation(cnf.input_channels, expanded_channels, kernel_size=1,
norm_layer=norm_layer, activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(expanded_channels, expanded_channels, kernel_size=cnf.kernel,
stride=cnf.stride, groups=expanded_channels,
norm_layer=norm_layer, activation_layer=activation_layer))
# squeeze and excitation
squeeze_channels = max(1, cnf.input_channels // 4)
layers.append(se_layer(expanded_channels, squeeze_channels))
# project
layers.append(ConvBNActivation(expanded_channels, cnf.out_channels, kernel_size=1, norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.stochastic_depth = StochasticDepth(stochastic_depth_prob, "row")
self.out_channels = cnf.out_channels
def forward(self, input: Tensor) -> Tensor:
result = self.block(input)
if self.use_res_connect:
result = self.stochastic_depth(result)
result += input
return result
通过NAS搜索得到的EfficientNet-B0作为baseline模型,其系数,根据前面的公式可以简单地通过网格搜索来确定,搜索得到的最佳设置是:。有了baseline模型,就可以按照复合缩放策略来对模型进行缩放以得到不同size的模型,论文中通过调整共得到了另外7个模型,即EfficientNet-B1~EfficientNet-B7,其中EfficientNet-B7的参数量为66M(输入大小为600),而EfficientNet-B0的参数量仅为5.3M。不过,在谷歌开源的源码中,不同的模型是通过给出width,depth增大的系数来确定的,如下所示::
def efficientnet_params(model_name):
"""Get efficientnet params based on model name."""
params_dict = {
# (width_coefficient, depth_coefficient, resolution, dropout_rate)
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
# 后面两个是更大的模型
'efficientnet-b8': (2.2, 3.6, 672, 0.5),
'efficientnet-l2': (4.3, 5.3, 800, 0.5),
}
return params_dict[model_name]
根据增大的系数,可以通过EfficientNet-B0来计算其他模型的depth和width,实际中是通过下面的函数来确定:
def _make_divisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# 简单乘以增大系数外,要限制depth和width是8的整数倍
def adjust_channels(channels: int, width_mult: float, min_value: Optional[int] = None) -> int:
return _make_divisible(channels * width_mult, 8, min_value)
EfficientNet在ImageNet数据集上的训练采用RMSProp 优化器,训练360epoch,而且策略上采用 SiLU (Swish-1) activation,AutoAugment和stochastic depth,这其实相比ResNet的训练已经增强了不少(ResNet训练epoch为90,数据增强只有随机裁剪(random-size cropping)和水平翻转(flip horizontal))。在ImageNet上效果如下表所示,可以看到不同size的EfficientNet比其它CNN模型在acc,模型参数和FLOPS上均存在绝对性优势。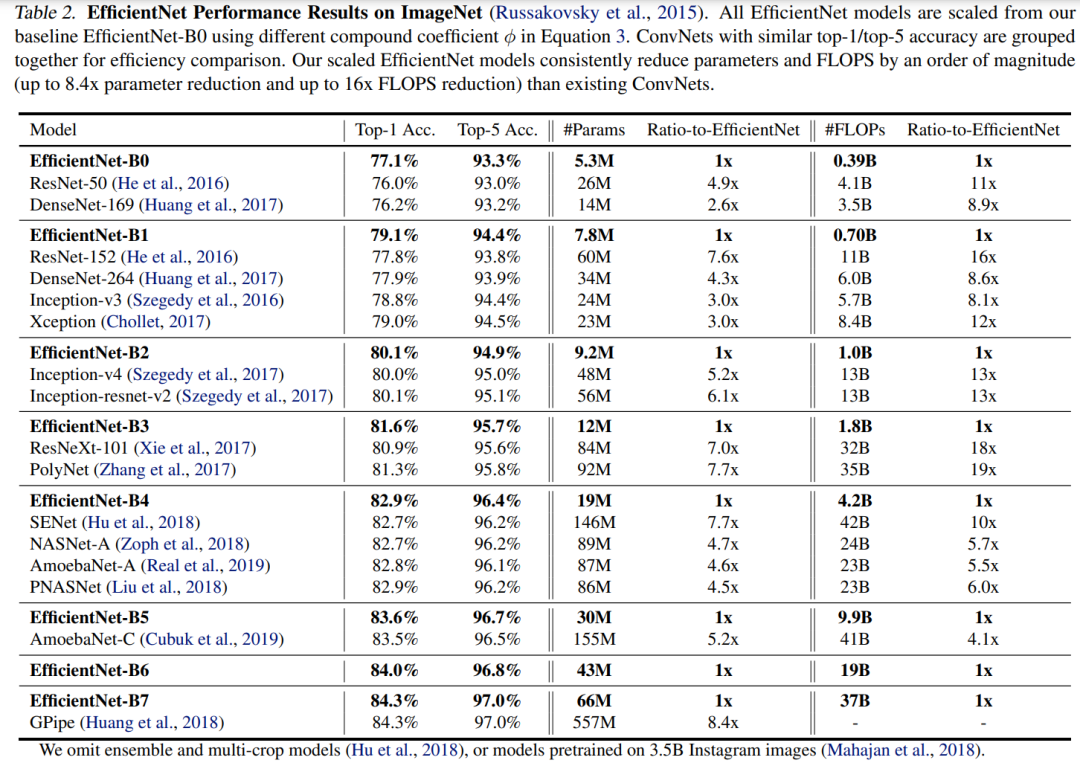 基于EfficientNet,谷歌在随后也做了很多其它工作,如其在19年提出Noisy Student Training (EfficientNet-L2) ,其在ImageNet上的top1-acc达到了 88.4% ,还有谷歌后面基于EfficientNet提出的检测模型EfficientDet。
基于EfficientNet,谷歌在随后也做了很多其它工作,如其在19年提出Noisy Student Training (EfficientNet-L2) ,其在ImageNet上的top1-acc达到了 88.4% ,还有谷歌后面基于EfficientNet提出的检测模型EfficientDet。
参考
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks EfficientNetV2: Smaller Models and Faster Training
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
