
【机器学习】用户分群:聚类和降维完美结合!
共 42774字,需浏览 86分钟
· 2023-11-09
作者:Peter
编辑:Peter
今天给大家介绍一个聚类和降维结合的项目,分为两块内容:
-
直接使用原数据,经过数据预处理和编码后,基于原生的K-Means和PCA/T-SNE实现用户的聚类
-
使用基于Transformer的预训练模型转换后的高维数据,再使用K-Means和PCA/T-SNE实现用户的聚类
本文先介绍第一种方案的完整过程。
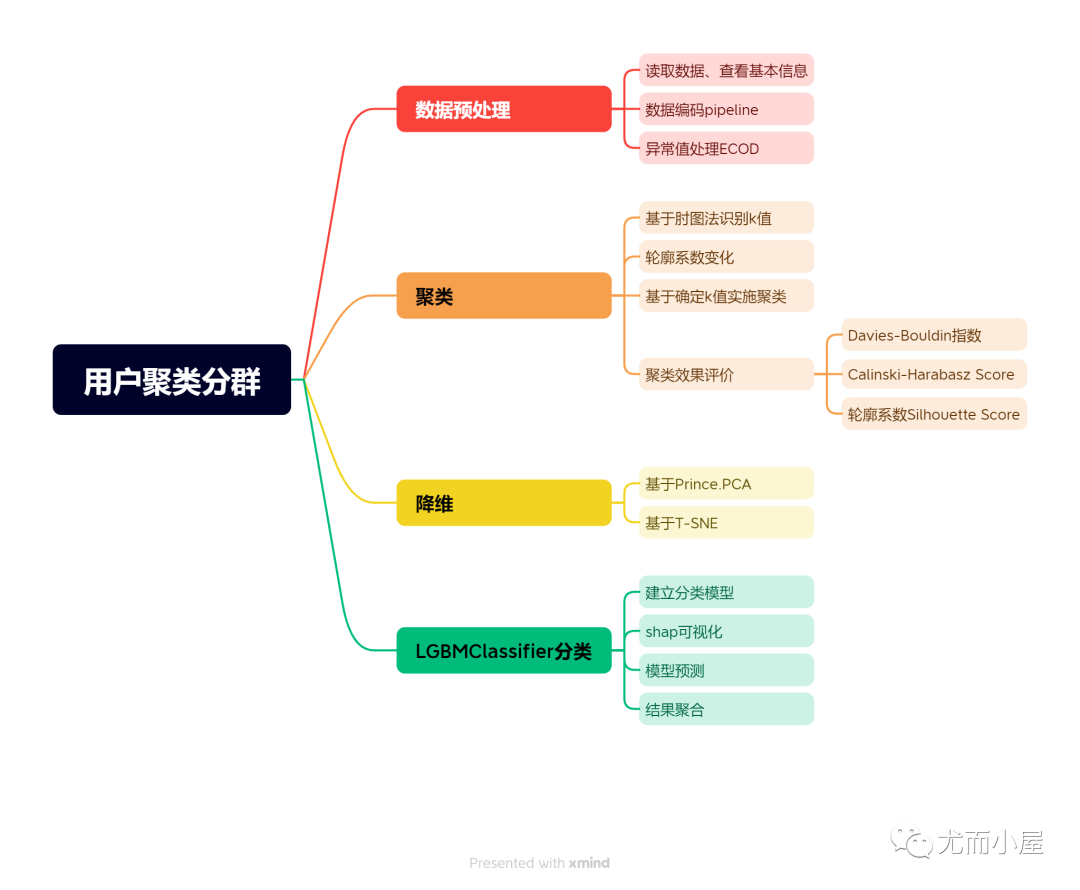
1 项目导图
整个项目的导图:
2 导入库
In [1]:
import pandas as pd
import numpy as np
np.random.seed(42)
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import plotly.express as px
import plotly.graph_objects as go
import seaborn as sns
import shap
from sklearn.cluster import KMeans
from sklearn.preprocessing import PowerTransformer, OrdinalEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.manifold import TSNE
from sklearn.metrics import silhouette_score, silhouette_samples, accuracy_score, classification_report
from pyod.models.ecod import ECOD
from yellowbrick.cluster import KElbowVisualizer
import lightgbm as lgb
import prince
from tqdm.notebook import tqdm
from time import sleep
import warnings
warnings.filterwarnings("ignore")
3 读取数据
In [2]:
df = pd.read_csv("train/train.csv",sep=";")
数据的探索性分析过程,了解数据基本信息:
In [3]:
df.shape
Out[3]:
(45211, 17)
In [4]:
df.columns
Out[4]:
Index(['age', 'job', 'marital', 'education', 'default', 'balance', 'housing',
'loan', 'contact', 'day', 'month', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'y'],
dtype='object')
In [5]:
df.dtypes
Out[5]:
age int64
job object
marital object
education object
default object
balance int64
housing object
loan object
contact object
day int64
month object
duration int64
campaign int64
pdays int64
previous int64
poutcome object
y object
dtype: object
In [6]:
pd.Series.value_counts(df.dtypes)
Out[6]:
object 10
int64 7
Name: count, dtype: int64
In [7]:
# 缺失值信息
df.isnull().sum()
Out[7]:
age 0
job 0
marital 0
education 0
default 0
balance 0
housing 0
loan 0
contact 0
day 0
month 0
duration 0
campaign 0
pdays 0
previous 0
poutcome 0
y 0
dtype: int64
结果表明数据中没有缺失值。
In [8]:
# 取出前面8个特征进行建模
df = df.iloc[:, 0:8]
4 数据预处理Preprocessing
主要是针对分类型的数据进行编码工作:
In [9]:
# 1-独热码
categorical_transformer_onehot = Pipeline(
steps = [("encoder", OneHotEncoder(handle_unknown="ignore",drop="first", sparse=False))])
# 2-顺序编码
caterogorical_transformer_ordinal = Pipeline(
steps=[("encoder", OrdinalEncoder())]
)
# 3-数据转换(对数变换、标准化、归一化等)
num = Pipeline(
steps=[("encoder",PowerTransformer())]
)
In [10]:
df.dtypes
Out[10]:
age int64
job object
marital object
education object
default object
balance int64
housing object
loan object
dtype: object
设定数据预处理器:
In [11]:
preprocessor = ColumnTransformer(transformers=[
("cat_onehot", categorical_transformer_onehot, ["default","housing","loan","job","marital"]),
("cat_ordinal", caterogorical_transformer_ordinal, ["education"]),
("num", num, ["age", "balance"])
])
5 创建pipeline
In [12]:
pipeline = Pipeline(
steps=[("preprocessor", preprocessor)]
)
# 训练
pipe_fit = pipeline.fit(df)
In [13]:
data = pd.DataFrame(pipe_fit.transform(df), columns=pipe_fit.get_feature_names_out().tolist())
data.shape
Out[13]:
(45211, 19)
In [14]:
data.columns
Out[14]:
Index(['cat_onehot__default_yes', 'cat_onehot__housing_yes',
'cat_onehot__loan_yes', 'cat_onehot__job_blue-collar',
'cat_onehot__job_entrepreneur', 'cat_onehot__job_housemaid',
'cat_onehot__job_management', 'cat_onehot__job_retired',
'cat_onehot__job_self-employed', 'cat_onehot__job_services',
'cat_onehot__job_student', 'cat_onehot__job_technician',
'cat_onehot__job_unemployed', 'cat_onehot__job_unknown',
'cat_onehot__marital_married', 'cat_onehot__marital_single',
'cat_ordinal__education', 'num__age', 'num__balance'],
dtype='object')
6 异常处理(ECOD)
基于Python Outlier Detection库进行异常值处理(Kmeans对异常值敏感)。
另外一种方法ECOD(empirical cumulative distribution functions for outlier detection)基于经验累积分布函数的异常值检测方法。
In [15]:
from pyod.models.ecod import ECOD
clf = ECOD()
clf.fit(data)
outliers = clf.predict(data)
outliers
Out[15]:
array([0, 0, 0, ..., 1, 0, 0])
In [16]:
data["outliers"] = outliers # 添加预测结果
df["outliers"] = outliers # 原始数据添加预测结果
In [17]:
# 包含异常值和不含包单独处理
# data无异常值
data_no_outliers = data[data["outliers"] == 0]
data_no_outliers = data_no_outliers.drop(["outliers"],axis=1)
# data有异常值
data_with_outliers = data.copy()
data_with_outliers = data_with_outliers.drop(["outliers"],axis=1)
# 原始数据无异常值
df_no_outliers = df[df["outliers"] == 0]
df_no_outliers = df_no_outliers.drop(["outliers"], axis = 1)
In [18]:
data_no_outliers.head()
Out[18]:
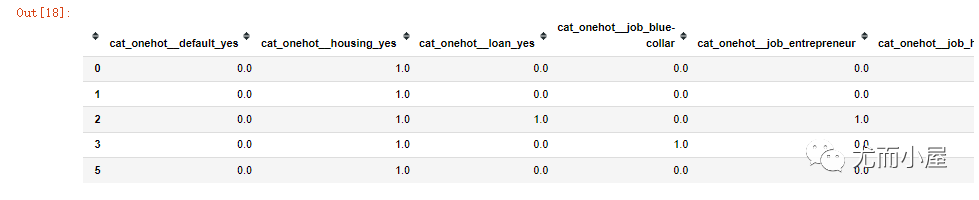
查看数据量:
In [19]:
data_no_outliers.shape
Out[19]:
(40690, 19)
In [20]:
data_with_outliers.shape
Out[20]:
(45211, 19)
7 聚类建模(K-Means)
7.1 肘图识别k值
聚类过程中的k值如何确定?介绍基于肘图的方法,详细参考:
https://www.geeksforgeeks.org/elbow-method-for-optimal-value-of-k-in-kmeans/
In [21]:
from yellowbrick.cluster import KElbowVisualizer
km = KMeans(init="k-means++", random_state=0, n_init="auto")
visualizer = KElbowVisualizer(km, k=(2,10))
visualizer.fit(data_no_outliers)
visualizer.show()
Out[21]:
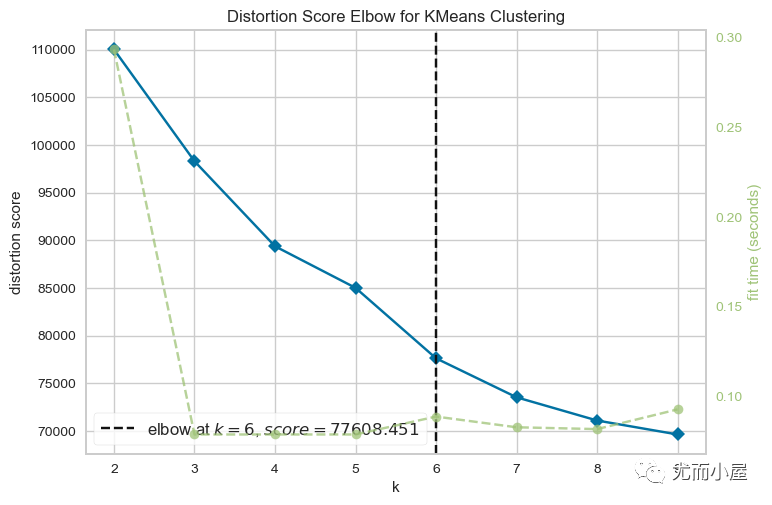
<Axes: title={'center': 'Distortion Score Elbow for KMeans Clustering'}, xlabel='k', ylabel='distortion score'>
我们可以看到k=6的时候是最好的。
7.2 轮廓系数变化
In [22]:
from sklearn.metrics import davies_bouldin_score, silhouette_score, silhouette_samples
import matplotlib.cm as cm
def make_Silhouette_plot(X, n_clusters):
plt.xlim([-0.1, 1])
plt.ylim([0, len(X) + (n_clusters + 1) * 10])
# 建立聚类模型
clusterer = KMeans(n_clusters=n_clusters,
max_iter=1000,
n_init=10,
init="k-means++",
random_state=10)
# 聚类预测生成标签label
cluster_label = clusterer.fit_predict(X)
# 计算轮廓系数均值(整体数据样本)
silhouette_avg = silhouette_score(X,cluster_label)
print(f"n_clusterers: {n_clusters}, silhouette_score_avg:{silhouette_avg}")
# 单个数据样本
sample_silhouette_value = silhouette_samples(X, cluster_label)
y_lower = 10
for i in range(n_clusters):
# 第i个簇群的轮廓系数
i_cluster_silhouette_value = sample_silhouette_value[cluster_label == i]
# 进行排序
i_cluster_silhouette_value.sort()
size_cluster_i = i_cluster_silhouette_value.shape[0]
y_upper = y_lower + size_cluster_i
# 颜色设置
color = cm.nipy_spectral(float(i) / n_clusters)
# 边界填充
plt.fill_betweenx(
np.arange(y_lower, y_upper),
0,
i_cluster_silhouette_value,
facecolor=color,
edgecolor=color,
alpha=0.7
)
# 添加文本信息
plt.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
plt.title(f"The Silhouette Plot for n_cluster = {n_clusters}", fontsize=26)
plt.xlabel("The silhouette coefficient values", fontsize=24)
plt.ylabel("Cluter Label", fontsize=24)
plt.axvline(x=silhouette_avg, color="red", linestyle="--")
# x-y轴的刻度标签
plt.xticks([-0.1,0,0.2,0.4,0.6,0.8,1])
plt.yticks([])
range_n_clusters = list(range(2, 10))
for n in range_n_clusters:
print(f"N cluster:{n}")
make_Silhouette_plot(data_no_outliers, n)
plt.savefig(f"Silhouette_Plot_{n}.png")
plt.close()
N cluster:2
n_clusterers: 2, silhouette_score_avg:0.18112038570087005
......
N cluster:9
n_clusterers: 9, silhouette_score_avg:0.1465020645956104
不同k值下的轮廓系数对比:
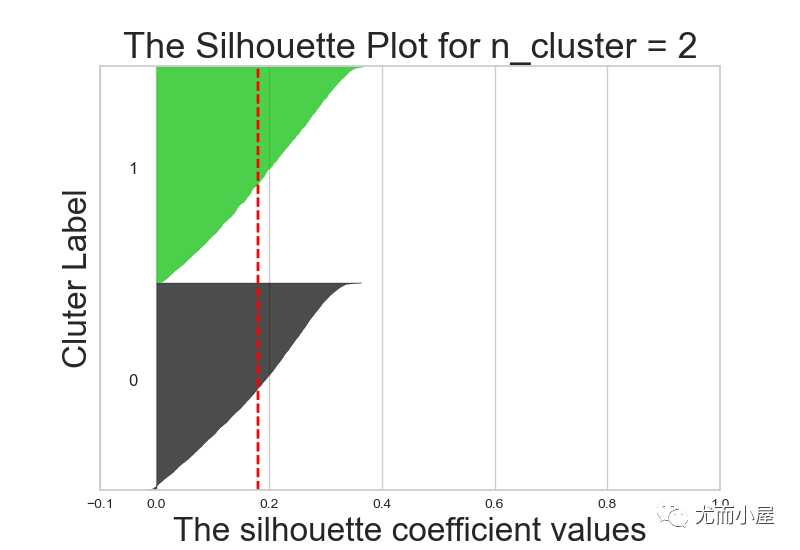
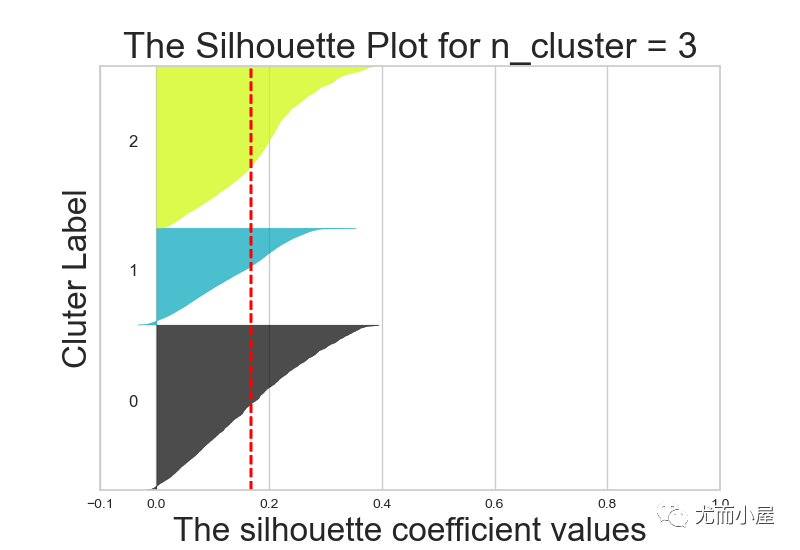
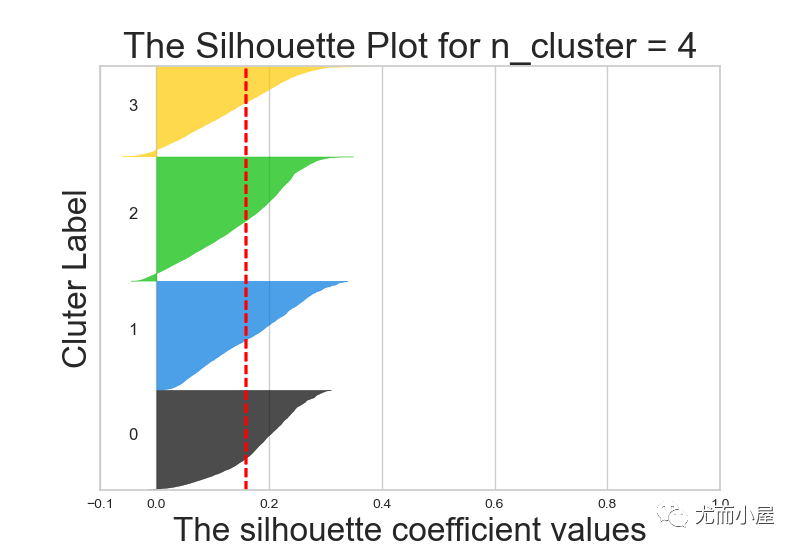
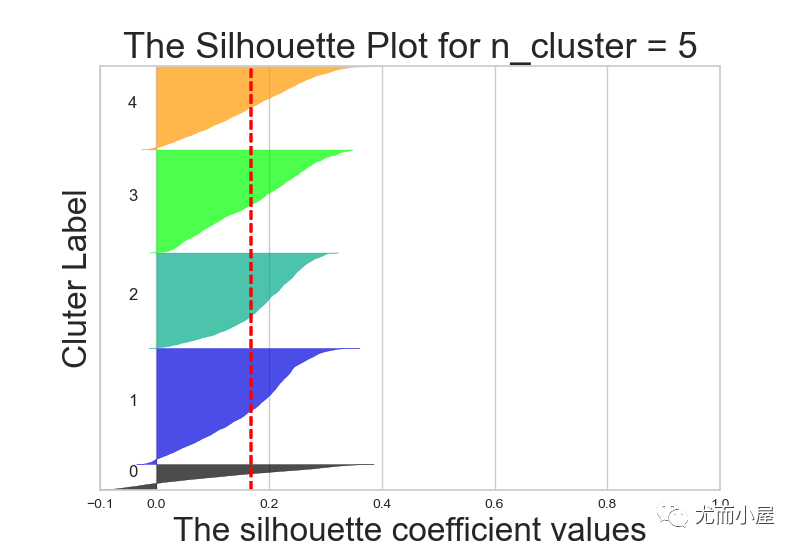

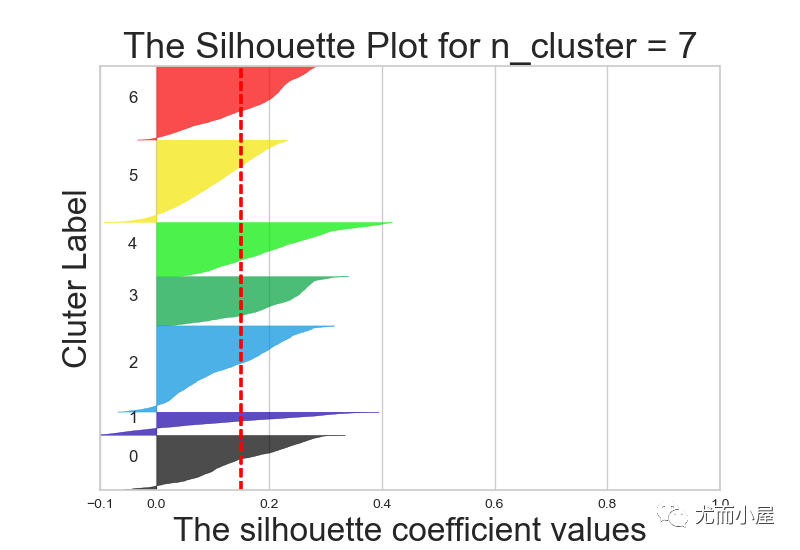
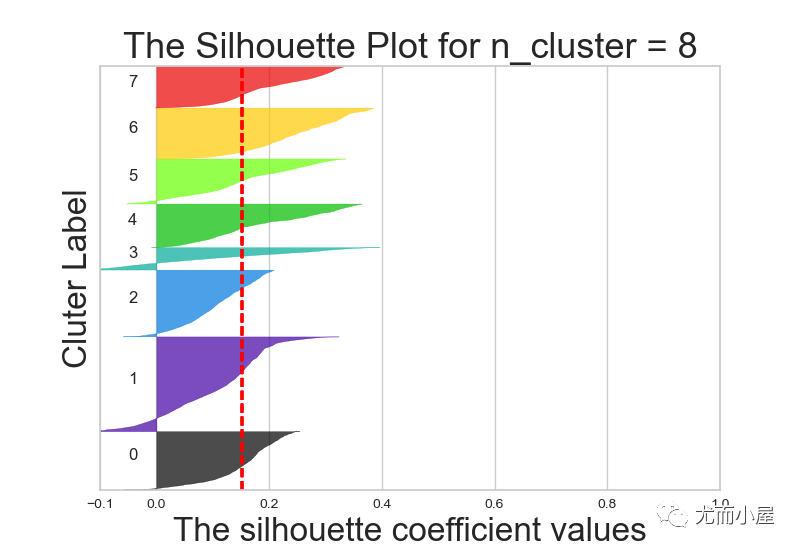
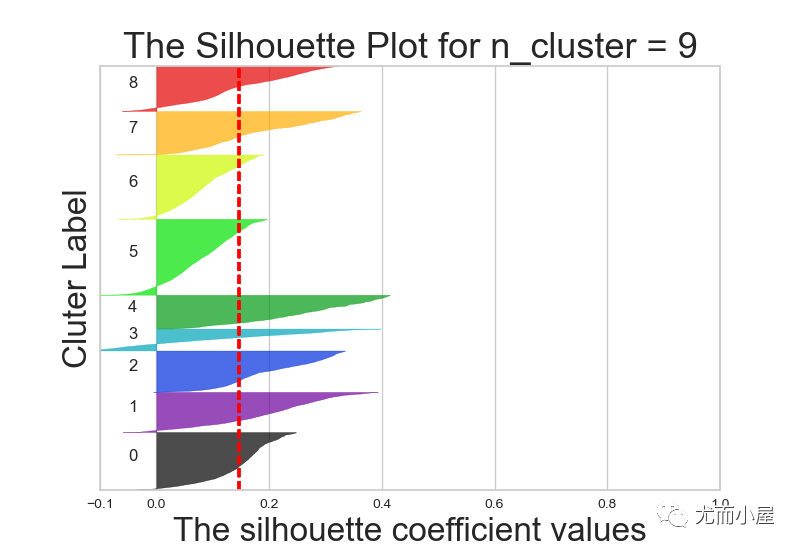
7.3 实施聚类
从结果来说,k=6或者5效果都还OK,在这里我们最终选择k=5进行聚类分群:
In [23]:
km = KMeans(n_clusters=5,
init="k-means++",
n_init=10,
max_iter=100,
random_state=42
)
# 对无离群点数据的聚类
clusters_predict = km.fit_predict(data_no_outliers)
7.4 评价聚类效果
聚类效果如何评价?常用的三种评价指标:
-
Davies-Bouldin指数 -
Calinski-Harabasz Score -
Silhouette Score
In [24]:
from sklearn.metrics import silhouette_score # 轮廓系数
from sklearn.metrics import calinski_harabasz_score
from sklearn.metrics import davies_bouldin_score # 戴维森堡丁指数(DBI)
Davies-Bouldin指数
Davies-Bouldin指数是聚类算法的一种评估方法,其值越小则表示聚类结果越好。该指数的原理是通过比较不同聚类簇之间的距离和不同聚类簇内部距离来测量聚类的效果。其计算方法如下:
-
对于每一个聚类簇,计算其中心点(centroid)。 -
计算每个聚类簇内点与其中心点的距离,并求其平均值,得到聚类内部距离(intra-cluster distance)。 -
计算不同聚类簇之间中心点的距离,并求其平均值,得到聚类间距离(inter-cluster distance)。 -
对于每个聚类簇,计算其Davies-Bouldin指数:除该簇外所有其他簇中心点与该簇中心点距离的平均值与该簇内部距离的比值。 -
对所有聚类簇的Davies-Bouldin指数求平均值,得到聚类总体的Davies-Bouldin指数。
通过Davies-Bouldin指数,我们可以比较不同聚类算法、不同参数下的聚类效果,从而选择最佳的聚类方案。Davies-Bouldin指数能够考虑到聚类结果的波动情况,对于相似的聚类结果,其Davies-Bouldin指数较大。因此,Davies-Bouldin指数能够区分不同聚类结果的相似程度。
此外,Davies-Bouldin指数没有假设聚类簇形状和大小的先验知识,因此可以适用于不同聚类场景。
Calinski-Harabasz Score
Calinski-Harabasz Score是一种用于评估聚类质量的指标,它基于聚类中心之间的方差和聚类内部的方差之比来计算。该指数越大,表示聚类效果越好。
Calinski-Harbasz Score是通过评估类之间方差和类内方差来计算得分,具体公式表示为:
其中, 代表聚类类别数, 代表全部数据数目, 是类间方差, 是类内方差。
的计算公式:
trace只考虑了矩阵对角上的元素,即类 中所有数据点到类的欧几里得距离。
的计算公式为:
其中, 是类 中所有数据的集合, 是类q的质点, 是所有数据的中心点, 是类 数据点的总数。
Silhouette Score
Silhouette Score表示为轮廓系数。
Silhouette Score 是一种衡量聚类结果质量的指标,它结合了聚类内部的紧密度和不同簇之间的分离度。对于每个数据点,Silhouette Score 考虑了以下几个因素:
-
a:数据点到同簇其他点的平均距离(簇内紧密度) -
b:数据点到最近不同簇的平均距离(簇间分离度)
具体而言,Silhouette Score 计算公式为:
轮廓系数的取值在 -1 到 1 之间,越接近 1 表示聚类效果越好,越接近 -1 则表示聚类结果较差。
In [25]:
print(f"Davies bouldin score: {davies_bouldin_score(data_no_outliers,clusters_predict)}")
print(f"Calinski Score: {calinski_harabasz_score(data_no_outliers,clusters_predict)}")
print(f"Silhouette Score: {silhouette_score(data_no_outliers,clusters_predict)}")
Davies bouldin score: 1.6775659296391374
Calinski Score: 6914.724747148267
Silhouette Score: 0.1672869940907178
8 降维(基于Prince.PCA)
参考官网学习地址:https://github.com/MaxHalford/prince
8.1 降维函数
In [26]:
import prince
import plotly.express as px
def get_pca_2d(df, predict):
"""
建立聚类模型,保留2个主成分
"""
pca_2d_object = prince.PCA(
n_components=2, # 保留两个主成分
n_iter=3, # 迭代次数
rescale_with_mean=True, # 基于均值和标准差的尺度缩放
rescale_with_std=True,
copy=True,
check_input=True,
engine="sklearn",
random_state=42
)
# 模型训练
pca_2d_object.fit(df)
# 原数据转换
df_pca_2d = pca_2d_object.transform(df)
df_pca_2d.columns = ["comp1", "comp2"]
# 添加聚类预测结果
df_pca_2d["cluster"] = predict
return pca_2d_object, df_pca_2d
# 同样的方式创建保留3个主成分的功能函数
def get_pca_3d(df, predict):
"""
保留3个主成分
"""
pca_3d_object = prince.PCA(
n_components=3, # 保留3个主成分
n_iter=3,
rescale_with_mean=True,
rescale_with_std=True,
copy=True,
check_input=True,
engine='sklearn',
random_state=42
)
pca_3d_object.fit(df)
df_pca_3d = pca_3d_object.transform(df)
df_pca_3d.columns = ["comp1", "comp2", "comp3"]
df_pca_3d["cluster"] = predict
return pca_3d_object, df_pca_3d
8.2 降维可视化
下面是基于2个主成分的可视化绘图函数:
In [27]:
def plot_pca_2d(df, title="PCA Space", opacity=0.8, width_line=0.1):
"""
2个主成分的降维可视化
"""
df = df.astype({"cluster": "object"}) # 指定字段的数据类型
df = df.sort_values("cluster")
columns = df.columns[0:3].tolist()
# 绘图
fig = px.scatter(
df,
x=columns[0],
y=columns[1],
color='cluster',
template="plotly",
color_discrete_sequence=px.colors.qualitative.Vivid,
title=title
)
# trace更新
fig.update_traces(marker={
"size": 8,
"opacity": opacity,
"line":{"width": width_line,
"color":"black"}
})
# layout更新
fig.update_layout(
width=800, # 长宽
height=700,
autosize=False,
showlegend = True,
legend=dict(title_font_family="Times New Roman", font=dict(size= 20)),
scene = dict(xaxis=dict(title = 'comp1', titlefont_color = 'black'),
yaxis=dict(title = 'comp2', titlefont_color = 'black')),
font = dict(family = "Gilroy", color = 'black', size = 15))
fig.show()
下面是基于3个主成分的可视化绘图函数:
In [28]:
def plot_pca_3d(df, title="PCA Space", opacity=0.8, width_line=0.1):
"""
3个主成分的降维可视化
"""
df = df.astype({"cluster": "object"})
df = df.sort_values("cluster")
# 定义fig
fig = px.scatter_3d(
df,
x='comp1',
y='comp2',
z='comp3',
color='cluster',
template="plotly",
color_discrete_sequence=px.colors.qualitative.Vivid,
title=title
)
# trace更新
fig.update_traces(marker={
"size":4,
"opacity":opacity,
"line":{"width":width_line,
"color":"black"}
})
# layout更新
fig.update_layout(
width=800, # 长宽
height=800,
autosize=True,
showlegend = True,
legend=dict(title_font_family="Times New Roman", font=dict(size= 20)),
scene = dict(xaxis=dict(title = 'comp1',
titlefont_color = 'black'),
yaxis=dict(title = 'comp2',
titlefont_color = 'black'),
zaxis=dict(title = 'comp3',
titlefont_color = 'black')),
font = dict(family = "Gilroy", color = 'black', size = 15))
fig.show()
8.2.1 2维
下面是2维可视化的效果:
In [29]:
pca_2d_object, df_pca_2d = get_pca_2d(data_no_outliers, clusters_predict)
In [30]:
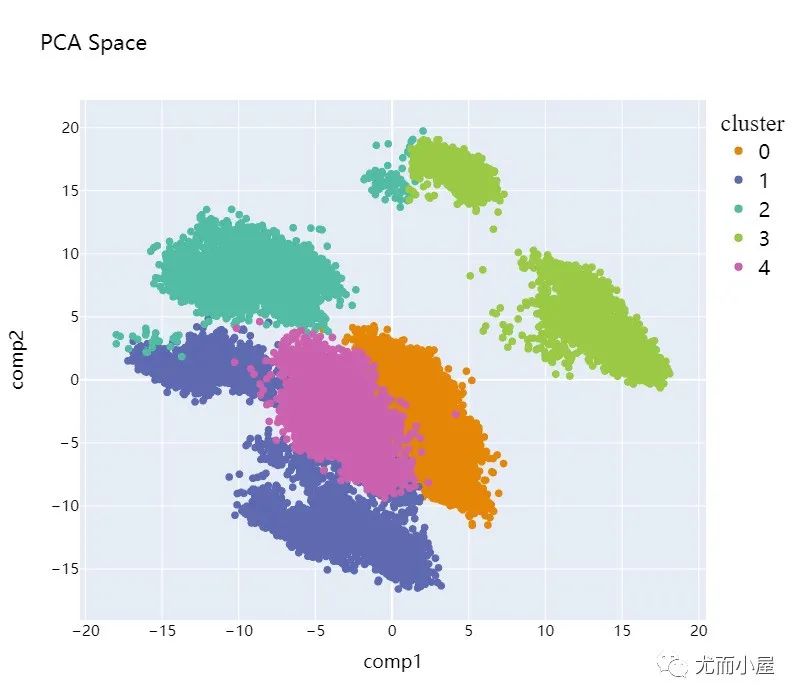
plot_pca_2d(df_pca_2d, title = "PCA Space", opacity=1, width_line = 0.1)
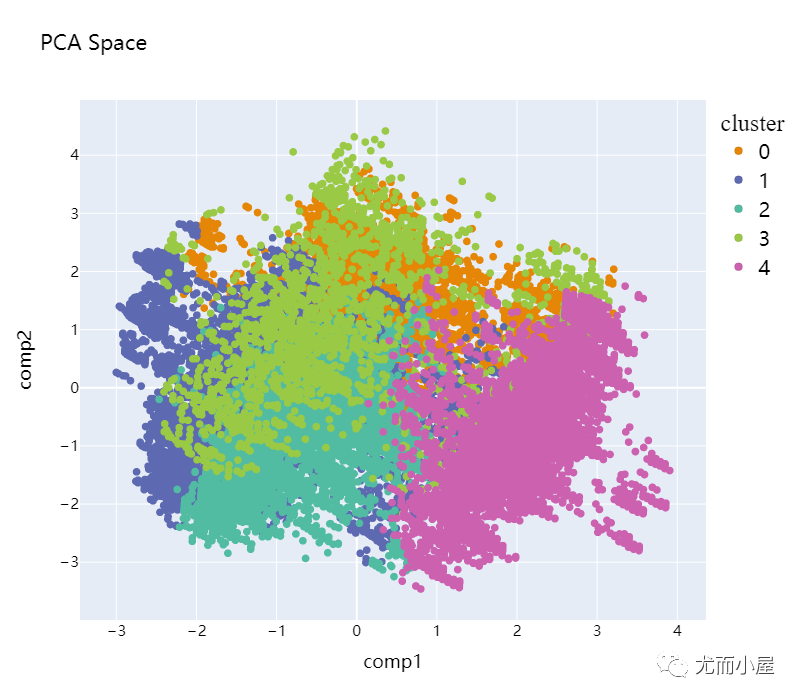
可以看到聚类效果并不是很好,数据并没有隔离开。
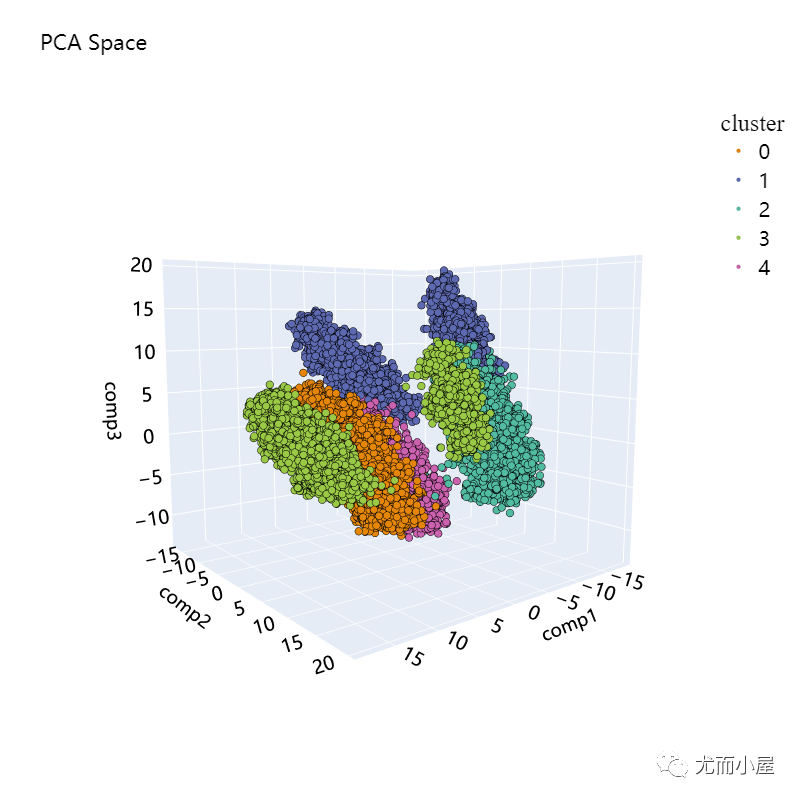
8.2.2 3维
下面是3维可视化的效果:
In [31]:
pca_3d_object, df_pca_3d = get_pca_3d(data_no_outliers, clusters_predict)
In [32]:
plot_pca_3d(df_pca_3d, title = "PCA Space", opacity=1, width_line = 0.1)
print("The variability is : ", pca_3d_object.eigenvalues_summary)
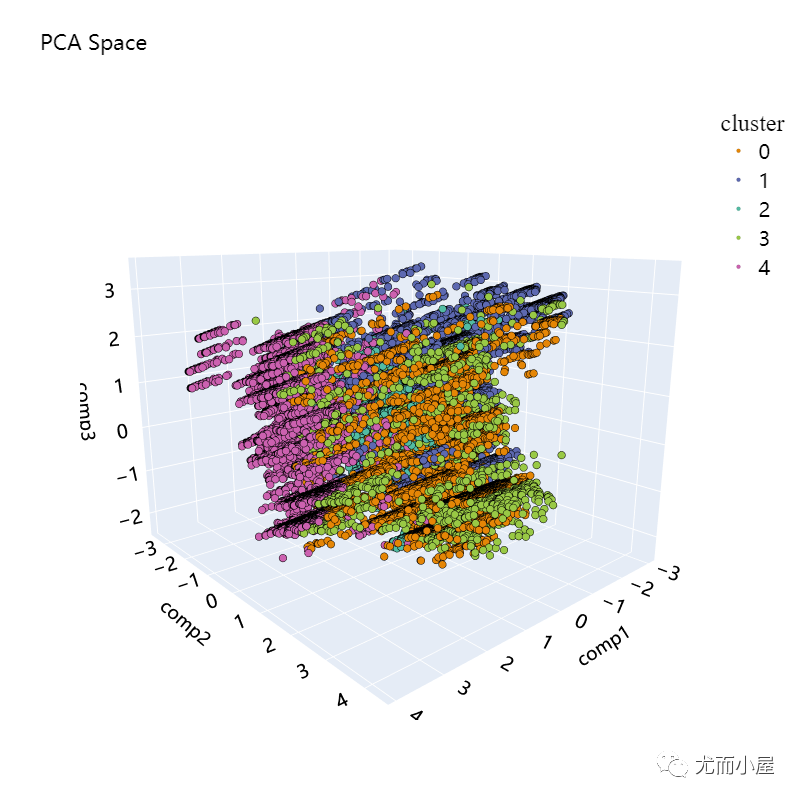
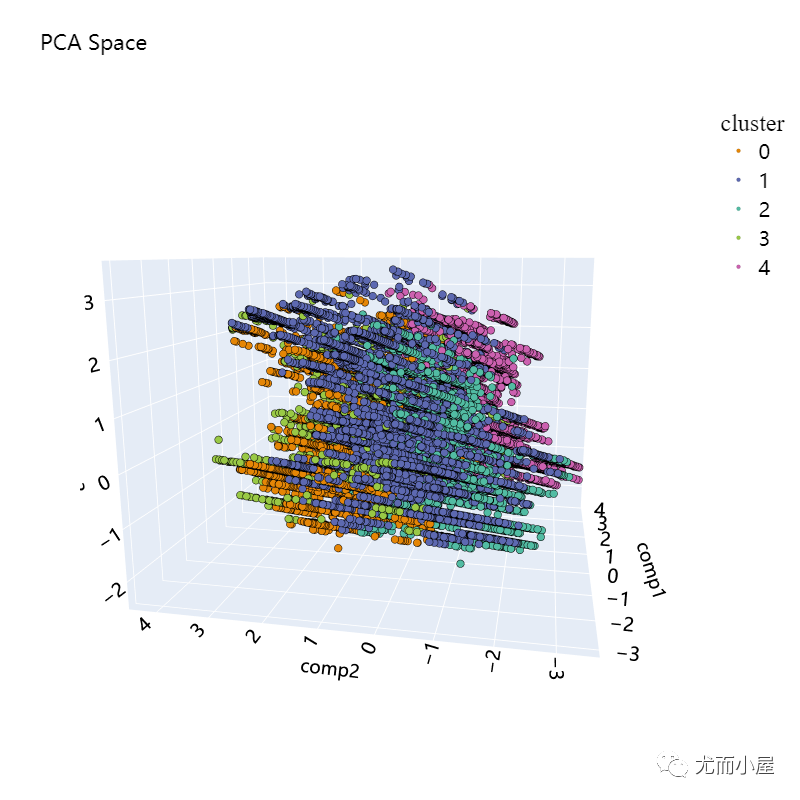
The variability is : eigenvalue % of variance % of variance (cumulative)
component
0 2.245 11.81% 11.81%
1 1.774 9.34% 21.15%
2 1.298 6.83% 27.98%
从结果中看到,聚类效果并不是很好,样本并没有分离开。
前面3个主成分的占比总共为27.98%,不足以捕捉到原始的数据信息和模式。下面介绍基于T-SNE的降维,该方法主要是用于高维数据的降维可视化:
9 降维优化(基于T-SNE)
取出部分样本
In [33]:
from sklearn.manifold import TSNE
# 无离群点的数据随机取数
sampling_data = data_no_outliers.sample(frac=0.5, replace=True, random_state=1)
# 聚类后的数据随机取数
# clusters_predict 表示从聚类结果中随机取数
sampling_cluster = pd.DataFrame(clusters_predict).sample(frac=0.5, replace=True, random_state=1)[0].values
sampling_cluster
Out[33]:
array([4, 1, 1, ..., 2, 0, 4])
9.1 实施2D降维
9.1.1 降维
In [34]:
# 建立降维模型
tsne2 = TSNE(
n_components=2,
learning_rate=500,
init='random',
perplexity=200,
n_iter = 5000)
In [35]:
data_tsne_2d = tsne2.fit_transform(sampling_data)
In [36]:
# 转成df格式 + 原聚类结果
df_tsne_2d = pd.DataFrame(data_tsne_2d, columns=["comp1","comp2"])
df_tsne_2d["cluster"] = sampling_cluster
9.1.2 可视化
In [37]:
plot_pca_2d(df_tsne_2d, title = "T-SNE Space", opacity=1, width_line = 0.1)
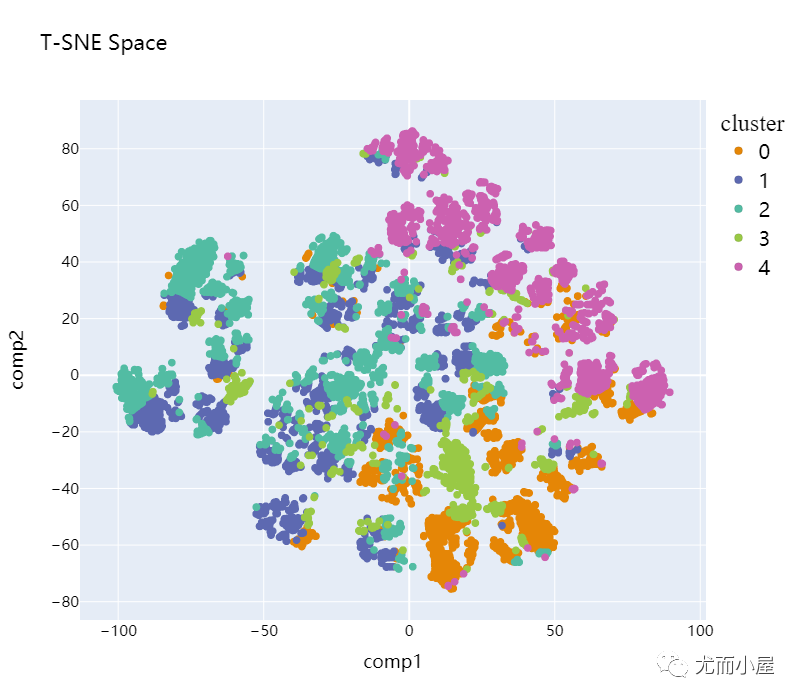
9.2 实施3D降维
9.2.1 降维
对聚类后的结果实施T-SNE降维:
In [38]:
# 建立3D降维模型
tsne3 = TSNE(
n_components=3,
learning_rate=500,
init='random',
perplexity=200,
n_iter = 5000
)
In [39]:
# 模型训练并转换数据
data_tsne_3d = tsne3.fit_transform(sampling_data)
In [40]:
# 转成df格式 + 原聚类结果
df_tsne_3d = pd.DataFrame(data_tsne_3d, columns=["comp1","comp2","comp3"])
df_tsne_3d["cluster"] = sampling_cluster
9.2.2 降维结果可视化
In [41]:
plot_pca_3d(df_tsne_3d, title = "T-SNE Space", opacity=1, width_line = 0.1)
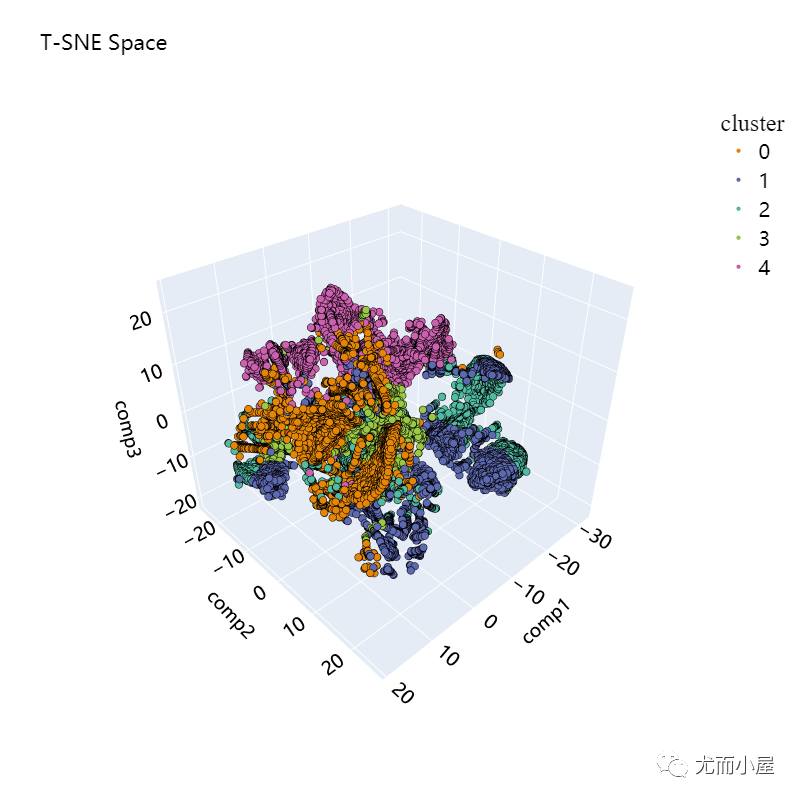
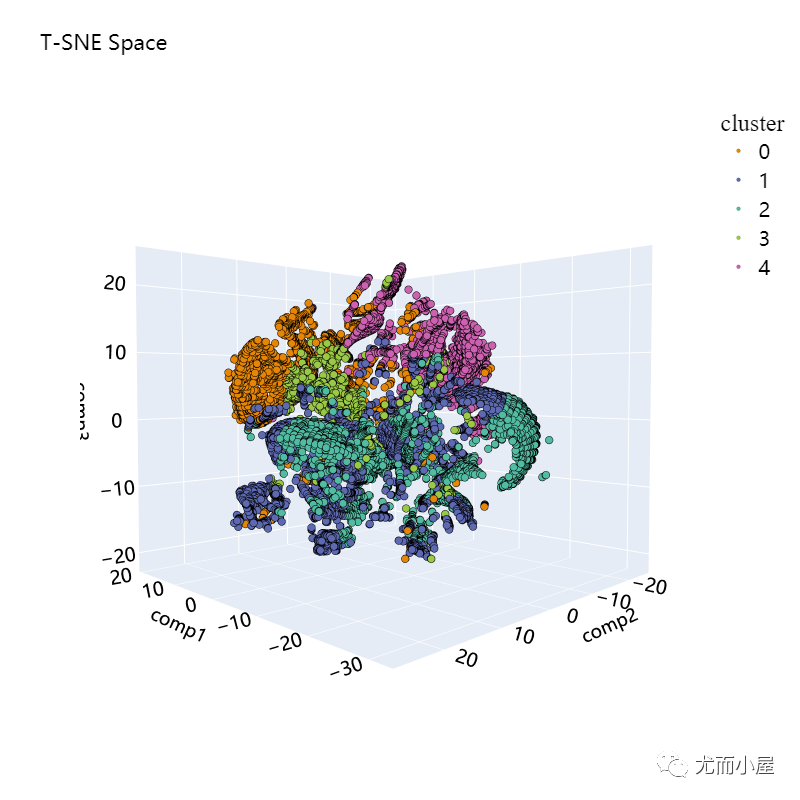
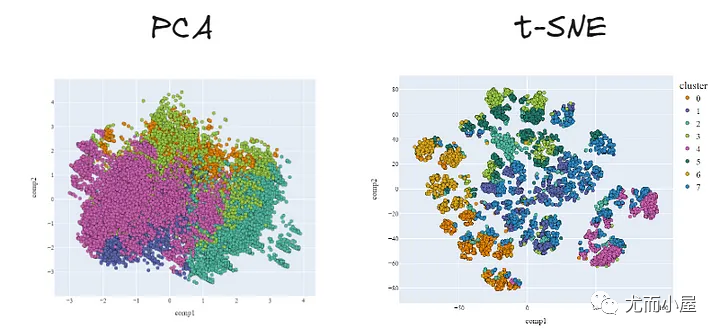
对比两种降维方法在二维效果上的比较:很明显,T-SNE的效果好很多~
10 基于LGBMClassifer的分类
将无异常的原始数据df_no_outliers作为特征X,聚类后的标签clusters_predict作为目标标签y,建立一个LGBMClassifer分类模型:
10.1 建立模型
In [42]:
import lightgbm as lgb
import shap
clf_lgb = lgb.LGBMClassifier(colsample_by_tree=0.8)
# 将部分字段的数据类型进行转化
for col in ["job","marital","education","housing","loan","default"]:
df_no_outliers[col] = df_no_outliers[col].astype("category")
clf_lgb.fit(X=df_no_outliers,
y=clusters_predict,
feature_name = "auto",
categorical_feature = "auto"
)
[LightGBM] [Warning] Unknown parameter: colsample_by_tree
[LightGBM] [Warning] Unknown parameter: colsample_by_tree
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000593 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 342
[LightGBM] [Info] Number of data points in the train set: 40690, number of used features: 8
[LightGBM] [Info] Start training from score -1.626166
[LightGBM] [Info] Start training from score -1.292930
[LightGBM] [Info] Start training from score -1.412943
[LightGBM] [Info] Start training from score -2.815215
[LightGBM] [Info] Start training from score -1.489282
Out[42]:
LGBMClassifier
LGBMClassifier(colsample_by_tree=0.8)
10.2 shap可视化
In [43]:
explainer = shap.TreeExplainer(clf_lgb) # 建立解释器
shap_values = explainer.shap_values(df_no_outliers) # 求出shap值
shap.summary_plot(shap_values, df_no_outliers, plot_type="bar",plot_size=(15,10))
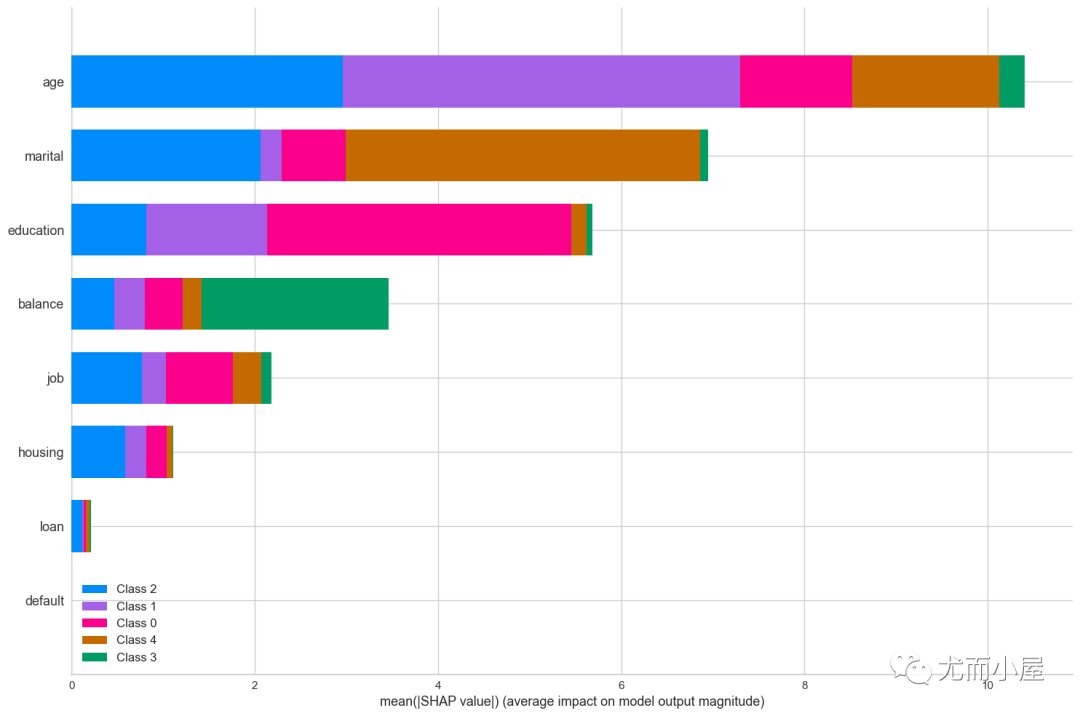
从结果中可以看到,age字段是最为重要的。
10.3 模型预测
In [44]:
y_pred = clf_lgb.predict(df_no_outliers) # 预测
acc = accuracy_score(y_pred, clusters_predict) # 预测值和真实值计算acc
# acc
print('Training-set accuracy score: {0:0.4f}'. format(acc))
[LightGBM] [Warning] Unknown parameter: colsample_by_tree
Training-set accuracy score: 1.0000
In [45]:
# 分类报告
print(classification_report(clusters_predict, y_pred))
precision recall f1-score support
0 1.00 1.00 1.00 8003
1 1.00 1.00 1.00 11168
2 1.00 1.00 1.00 9905
3 1.00 1.00 1.00 2437
4 1.00 1.00 1.00 9177
accuracy 1.00 40690
macro avg 1.00 1.00 1.00 40690
weighted avg 1.00 1.00 1.00 40690
10.4 聚合结果
In [46]:
# 原始数据无异常
df_no_outliers = df[df.outliers == 0]
df_no_outliers["cluster"] = clusters_predict # 聚类结果
以聚类的簇结果cluster为分组字段:
-
统计数值型字段的均值(mean) -
分类型字段的最高频数字段(分组后的第一个数据信息)
In [47]:
df_no_outliers.groupby("cluster").agg({
"job":lambda x: x.value_counts().index[0],
"marital": lambda x: x.value_counts().index[0],
"education":lambda x: x.value_counts().index[0],
"housing":lambda x: x.value_counts().index[0],
"loan":lambda x: x.value_counts().index[0],
"age":"mean",
"balance":"mean",
"default":lambda x: x.value_counts().index[0]
}).sort_values("age").reset_index()
Out[47]:
| cluster | job | marital | education | housing | loan | age | balance | default | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | technician | single | secondary | yes | no | 32.069740 | 794.696306 | no |
| 1 | 2 | blue-collar | married | secondary | yes | no | 34.569409 | 592.025644 | no |
| 2 | 3 | management | married | secondary | yes | no | 42.183012 | 7526.310217 | no |
| 3 | 0 | management | married | tertiary | no | no | 43.773960 | 872.797951 | no |
| 4 | 1 | blue-collar | married | secondary | no | no | 50.220989 | 836.407504 | no |
参考
参考原英文学习地址:https://towardsdatascience.com/mastering-customer-segmentation-with-llm-3d9008235f41
后面会给大家分享Transformer模型+Kmeans+PCA/T-SNE的方案~
代码已经整理完成,文章梳理中。先提前看看基于Transformer模型转换的数据(数据扩充到384维)使用PCA的效果:的确好太多了!
往期精彩回顾
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)