
你为什么不敢重构代码?

源 /顶级程序员 文/ 黑石
一、你为什么不敢发代码?
通过代码还原当时完整的产品逻辑太难了



没有自测用例
没有测试同学跟进
没有稳定发布方案
时间回到年初你刚刚接到重构任务的时候。
二、寻求组织保障
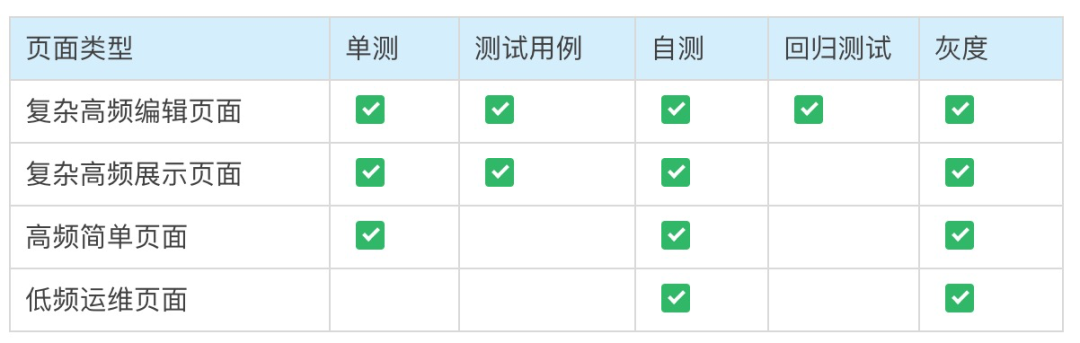
三、划分重构页面优先级

复杂高频页面:重兵压上,细致还原原始需求,抠代码,拉测试同学一起整理测试用例,按照测试用例自测,测试同学回归所有功能。但其实这部分页面中,也可以分为两种页面: 编辑页面:这样的页面是风险最高的页面,一旦因为后端接口没有做完整的数据校验,就会编辑出脏数据,或者错误的数据被保存,导致线上运行异常,这种后果将是不堪设想的,即使非常短的时间内回滚,也会造成难以挽回的故障,因此必须要像新需求一样测试到位。 展示页面:这样的页面不会影响运行时,不会产生脏数据,是风险相对低一点点的页面,本着不麻烦合作方的原则,毕竟资源有限,可以让测试帮你出完整的用例,然后你自己自测,或者多找几个同学帮你自测。 高频简单页面:自测,当然最好是能绑架几个经常用这个功能的开发,来帮你点点,但是自己测总是会有可能会有遗漏,因此就需要下面的步骤来保证了。 低频运维页面:选择性重构,因为很多页面基本上不会有迭代,且使用频率较低,基本上不需要重构,即使是有新的需求,也可以在做新需求的时候顺便重构下,以为并不能占用太多时间。
四、单测
当下的收益不高。 相比后端接口的单测,前端单测写起来相对复杂。 前端更多是面向 UI 的编程,但 UI 变动大,难以使用 TDD (测试驱动开发) 的开发模式。 没有写单测的习惯,可能是因为单测增加了工作量,且没有写纯函数的意识,不利于测试。 单测的工具难学又难用。

describe('utils', () => {
it('流程图:转换为提交的数据 transformForm', () => {
const result = transformForm(canvasData);
expect(result).toEqual(settingData);
});
it('流程图:转换为需要的数据 parseRuleSetData', () => {
const [result] = parseRuleSetData(settingData, rules);
expect(result).toEqual(canvasData);
});
it('流程图:反复转换 transformForm - parseRuleSetData', () => {
const [result] = parseRuleSetData(visualSettings, rulesData);
const newResult = transformForm(result);
expect(newResult).toEqual(visualSettings);
});
});
复制代码
五、测试用例
六、自测
七、回归测试
八、灰度发布
配置用户或者用户组 配置老路由和新路由 配置灰度状态提示 新老页面的自动打点

L1:所有项目开发,测试,设计师,内部运营人员 L2:核心用户,建立钉钉群,观察用户反馈,及时解决用户问题。 L3:适当加入更多用户,直到全量后,删除灰度策略的配置。

九、全量上线
十、总结
Double Check:让其他人参与进来,多一个人就能帮你发现更多问题。重构面前,不要相信自己,相信伙伴。 逻辑无死角:不要还有不懂的代码,不清楚的逻辑,按照程序员的第六感,不确定的都会出大问题。 集中注意力:重构不能碎片化进行,要集中大块时间来做,并一做到底,不然过个几天,你自己的代码都会不认识。 一跟到底:开发完成不是重点,全量上线,并下掉老的页面才是结束。

好文推荐

因故意引入漏洞,整所大学被禁止为Linux内核做贡献,回应来了!

今天,我的电脑被勒索了,嘿嘿嘿!

— 完 —
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~
评论