图解|什么是缓存系统三座大山
点击上方蓝色“后端技术学堂”关注后加个“星标”
最新分享第一时间看!
1.无处不在的缓存
缓存在计算机系统是无处不在,在CPU层面有L1-L3的Cache,在Linux中有TLB加速虚拟地址和物理地址的转换,在浏览器有本地缓存、手机有本地缓存等。
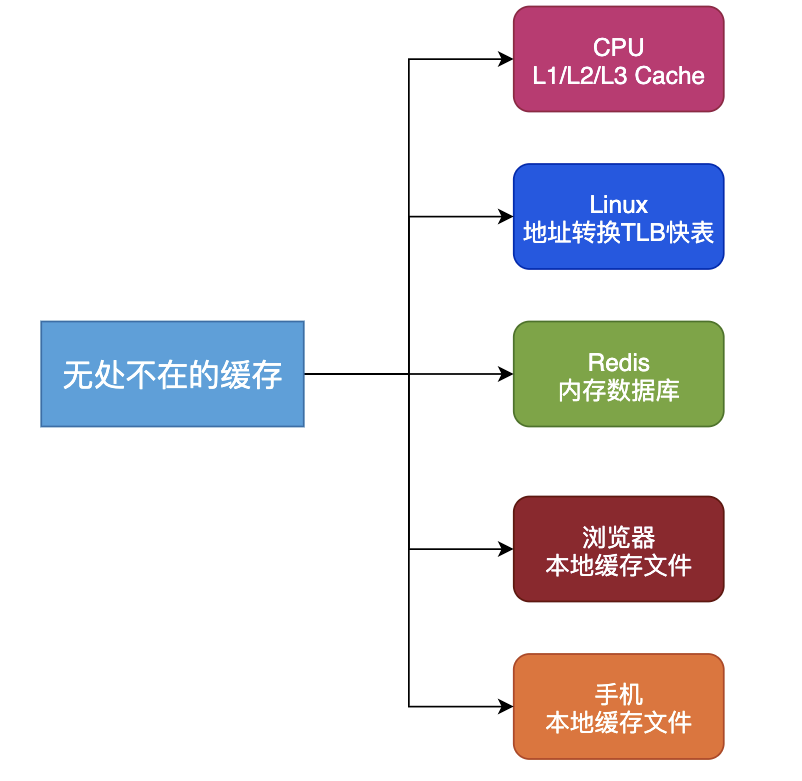
可见,缓存在计算机系统中有非常重要的地位,其主要作用是提高响应速度、减少磁盘访问等,本文主要讨论在高并发系统中的缓存系统。
一句话概括缓存系统在高并发系统中的地位的话:如果高并发系统是烤羊肉串,那么缓存系统就是那一撮孜然。

2.高并发系统中的缓存
2.1 缓存系统的作用
缓存系统在高并发系统的作用很大,在某种程度上可以说没有缓存系统很难支撑高并发场景。
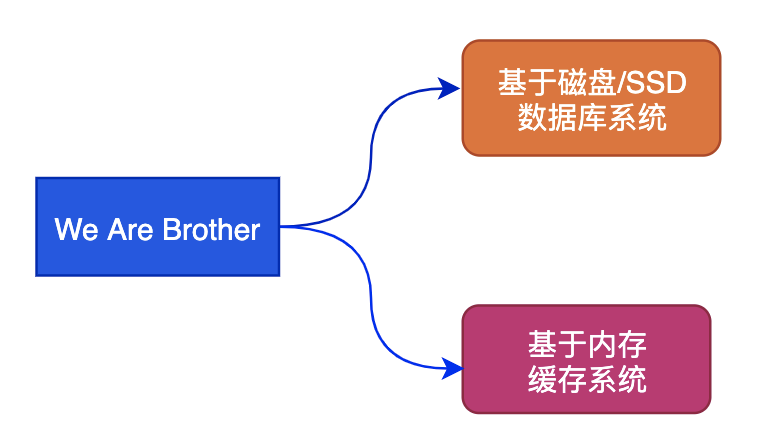
基于机械磁盘或SSD的数据库系统,一般来说读写的速度远慢于内存,因此单纯磁盘介质的数据库无法支撑很高的并发,可以简单认为缓存是保护磁盘数据库的重要屏障。
对于一些基于LSM的存储引擎数据库来说,随机写改为顺序写速度提升很大,但是随机读仍然是个问题,所以缓存系统是很有必要的。
2.2 缓存系统访问流程
实际场景也是读多写少,看看请求是如何得到响应的,简单看下交互流程:
- 请求到达之后,业务线程首先访问缓存,如果缓存命中则返回
- 如果未命中则继续请求磁盘数据库系统,获取数据返回
- 从磁盘获取数据后将结果回写到缓存系统且增加老化时间,为下次请求做准备
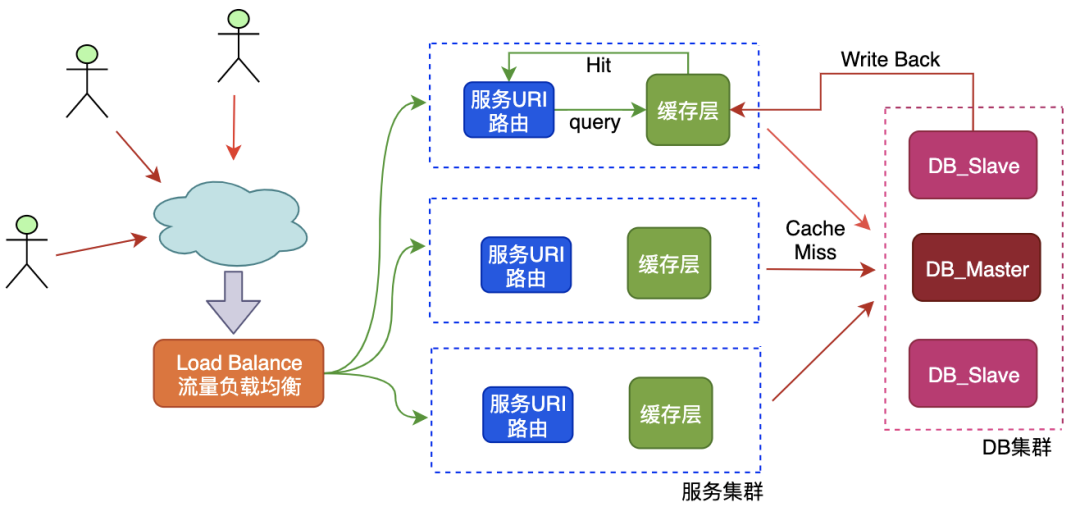
以上是高并发系统中缓存和磁盘数据库系统、客户端请求之间的交互过程,后续的问题分析,也是基于此过程展开的。
3.缓存系统的三大问题
网络上对于缓存三大问题的文章很多,提到的三个问题主要是:
- 缓存雪崩 Cache Avalanche
- 缓存穿透 Cache Penetration
- 缓存击穿 Hotspot Invalid
对于上面的三个名词我一直分不清楚,脑海中并没有清晰的区别。
于是想到去谷歌看看歪果仁是怎么说的,然而英文表述就是上面的英文,基本上和汉语翻译是一样的,所以只能强记,太难了。

3.1 缓存雪崩问题
所谓雪崩就是原来有所支撑的冰雪,某一瞬间失去依托,瞬间涌下来。
这个场景让我想起了2011年上映的柯南剧场版《沉默的十五分钟》,柯南在北泽村水库为了拯救村庄制造的雪崩:

可见雪崩确实很可怕,回到高并发系统,如果缓存系统故障,大量的请求无法从缓存完成数据请求,就全量汹涌冲向磁盘数据库系统,导致数据库被打死,整个系统彻底崩溃。
3.2 缓存雪崩解决方案
造成缓存雪崩的主要原因是缓存系统不够高可用,因此提高缓存系统的稳定性和可用性十分必要,比如对于使用Redis作为缓存的系统而言可以使用哨兵机制、集群化、持久化等来提高缓存系统的HA。
除了保证缓存系统的HA之外,服务本身也需要支持降级,可以借助比如Hystrix来实现服务的熔断、降级、限流来降低出现雪崩时的故障程度。
说白了就是别让服务彻底死掉就行,就像大雪封高速肯定不能通行了,堵车慢一些至少可以走。
3.3 缓存穿透问题
穿透形象一点就是:请求过来了 转了一圈 一无所获 就像穿过透明地带一样。
在高并发系统中缓存穿透,如果一个req需要请求的数据在缓存中没有,这时业务线程就会访问磁盘数据库系统,然而磁盘数据库也没有这个数据,无奈业务线程只能白白处理一圈。
如果某时段有大量恶意的不存在的key的集中请求,那么服务将一直处理这些根本不存在的请求,导致正常请求无法被处理,从而出现问题。
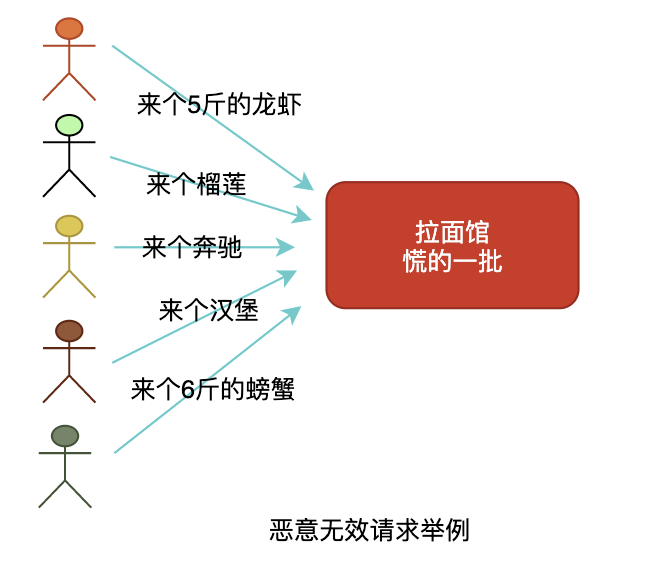
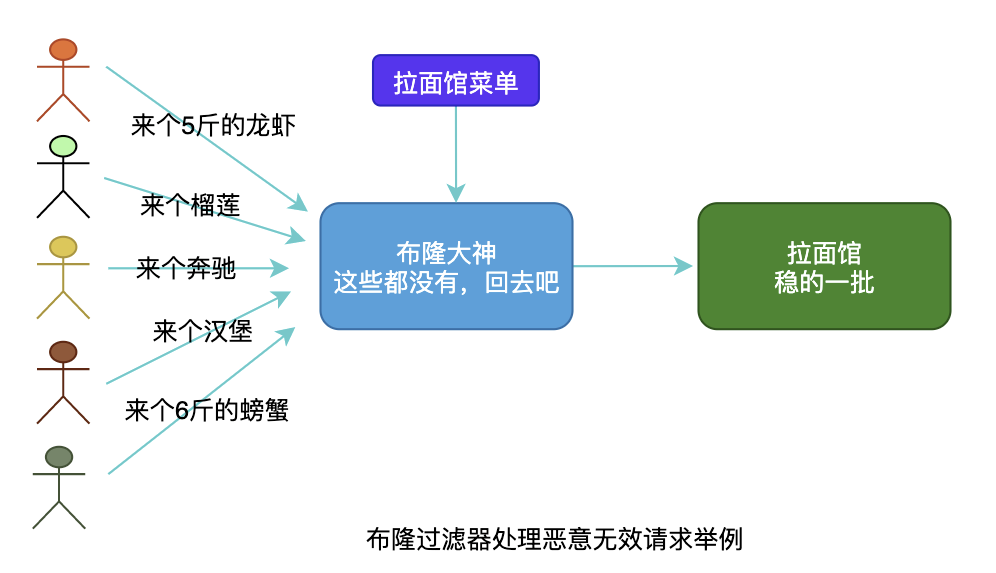
举个栗子:
拉面馆的服务员和厨师不允许拒绝已经进来的消费者,但是拉面馆的经营范围有限。此时恶意消费者点了一只5斤的澳洲龙虾,经过服务员和厨师都无法响应这个需求,此时轮流来了1000个这样的恶意消费者,拉面馆基本要歇菜了。
3.4 缓存穿透解决方案
有效甄别是否存在这个key再决定是否读取很重要,常见的做法有:
把不存在的key写一下null,这样再来就相当于命中了,其实这种方法局限性很大,今天是5斤龙虾,明天改成6斤的螃蟹,缓存系统和数据库中存储大量无用key本身是无意义的,所以一般不建议
另外一种思路,转换为查找问题,类似于在海量数据中查找某个key是否存在,考虑空间复杂度和时间复杂度,一般选用布隆过滤器来实现。
布隆过滤器是个好东西,有非常多的用途,包括:垃圾邮件识别、搜索蜘蛛爬虫url去重等,主要借助K个哈希函数和一个超大的bit数组来降低哈希冲突本身带来的误判,从而提高识别准确性。
布隆过滤器也存在一定的误判,假如判断存在可能不一定存在,但是假如判断不存在就一定不存在,因此刚好用在解决缓存穿透的key查找场景,事实上很多系统都是基于布隆过滤器来解决缓存穿透问题的。
3.5 缓存击穿问题
缓存击穿是这样一种情况:
由于缓存系统中的热点数据都有过期时间,如果没有过期时间就造成了主存和缓存的数据不一致,因此过期时间一般都不会太长。
设想某时刻一批热点数据同时在缓存系统中过期失效,那么这部分数据就都将请求磁盘数据库系统。
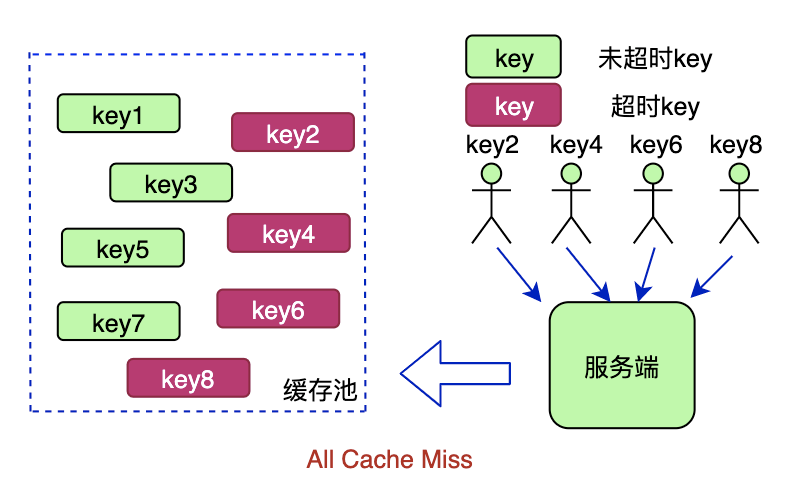
从描述上来看有点像微小规模的雪崩,但是对数据库的压力就很小了,只不过会影响并发性能,然而在多线程场景中缓存击穿却是经常发生的,相反缓存穿透和雪崩频率不如缓存击穿,因此研究击穿的现实意义更大一些。

3.6 缓存击穿解决方案
可以采用的方案大概有几种:
在设置热点数据过期时间时尽量分散,比如设置100ms的基础值,在此基础上正负浮动10ms,从而降低相同时刻出现CacheMiss的key的数量。
另外一种做法是多线程加锁,其中第一个线程发现CacheMiss之后进行加锁,再从数据库获取内容之后写到缓存中,其他线程获取锁失败则阻塞数ms之后再进行缓存读取,这样可以降低访问数据数据库的线程数,需要注意在单机和集群需要使用不同的锁,集群环境使用分布式锁来实现,但是由于锁的存在也会影响并发效率。
一种方法是在业务层对使用的热点数据查看是否即将过期,如果即将过期则去数据库获取最新数据进行更新并延长该热点key在缓存系统中的时间,从而避免后面的过期CacheMiss,相当于把事情提前解决了。
缓存击穿的解决方法都有一定的权衡,实际中根据自己的需求来解决。
缓存击穿的影响一般来说并不会太大,或许在你的服务跑了很久之后你才意识到会有缓存击穿问题。
4.小结
缓存系统无论在实际工作中还是在面试中都是热点内容,缓存系统目的是为了让访问又准又快,不要一味追求缓存命中率,缓存和主数据库的数据一致性是需要重点考虑的。
总起来说,如何在保证数据正确性的前提下提高缓存命中率就是核心问题。

如果觉得文章写的还行,对你有所帮助,请不吝三连「在看、点赞、分享」,这是对我持续创作的最大支持。
今天的技术分享就到这里,我们下期再见。
精选好文
别再说你不懂Linux内存管理了,10张图给你安排的明明白白!
带你学够浪:Go基础系列-环境配置和 Hello world
关注公众号「后端技术学堂」
带你一起学编程
回复「资源」送你编程学习大礼包
包括3个G的编程「学习资源」
我建了个学习交流群,群内不定期分享优质技术文章,一起学习一起进阶,加下面我微信备注「进群」我拉你加入
扫一扫,备注「进群」
学会了吗?在看分享了吗