
HDFS+Clickhouse+Spark:从0到1实现一款轻量级大数据分析系统
导语 | 在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析、版本迭代效果分析、运营活动效果分析等。这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足。本文尝试从0到1实现一款轻量级大数据分析系统——MVP,以解决上述痛点问题。文章作者:数据熊(笔名),腾讯云大数据分析工程师。
一、背景及问题
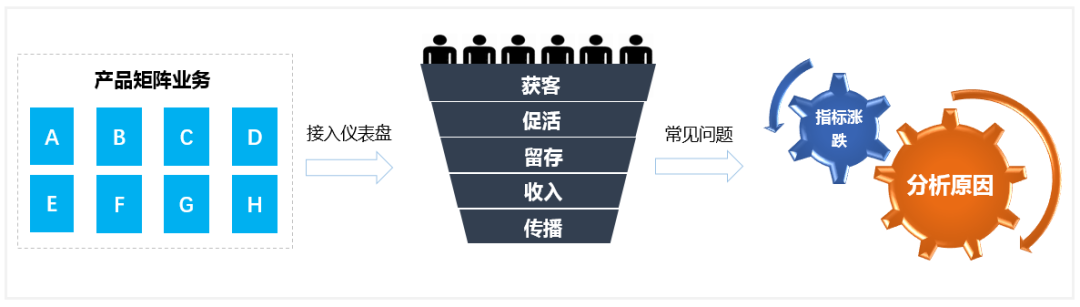

二、解决办法
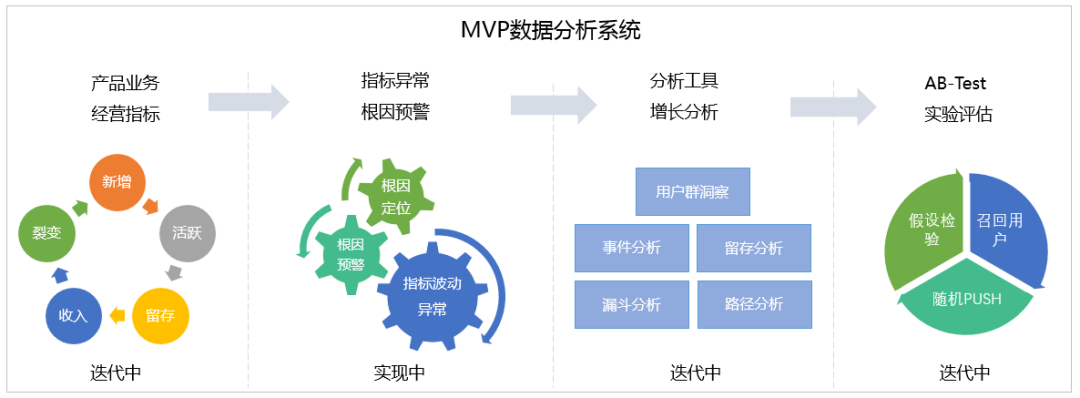
三、技术实现
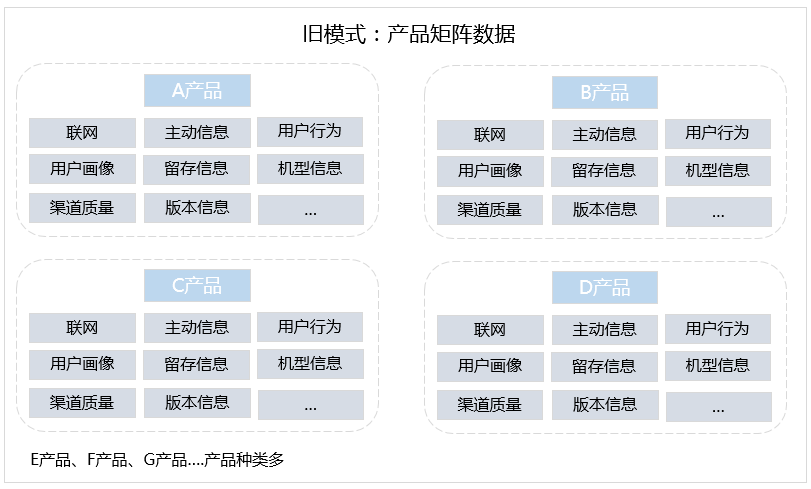
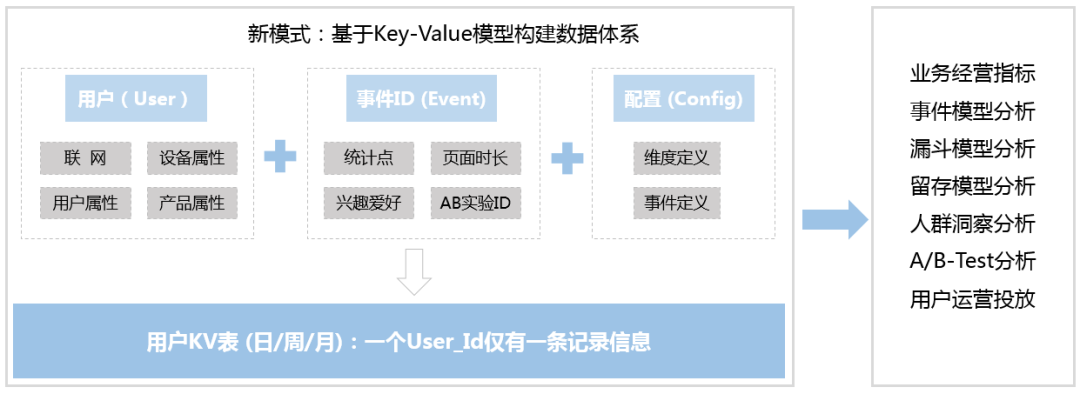
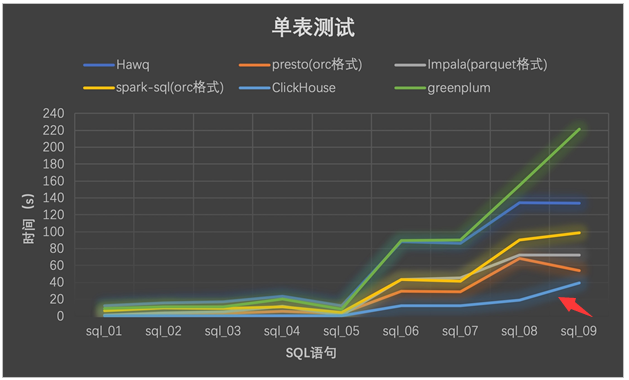
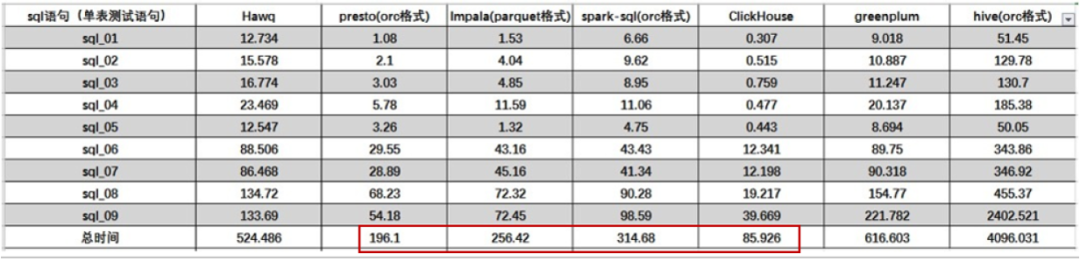
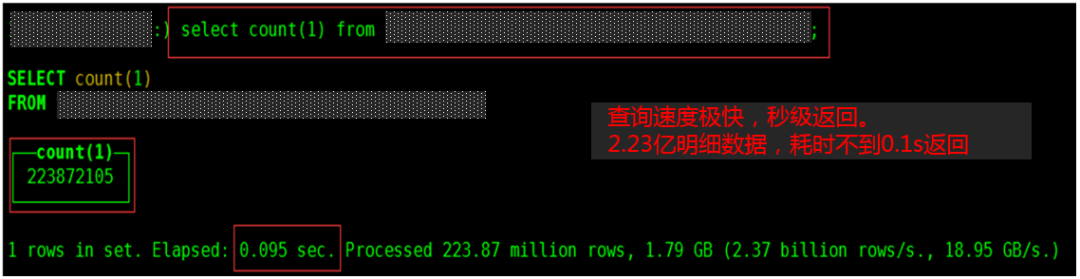
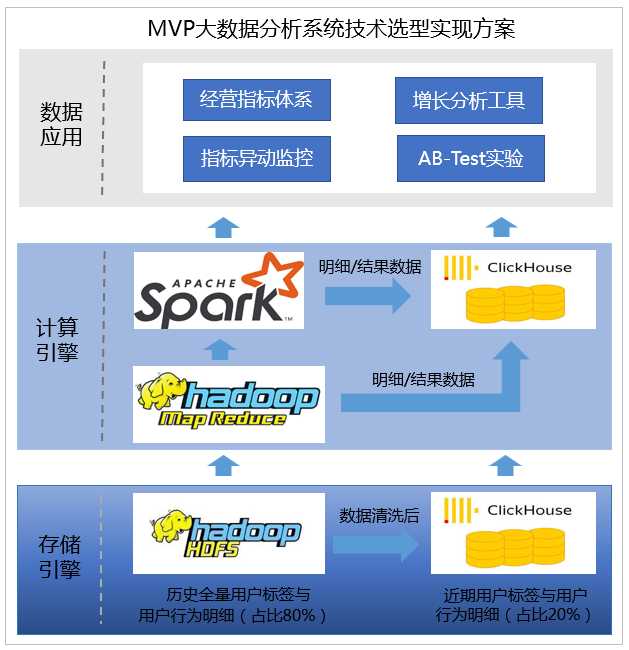
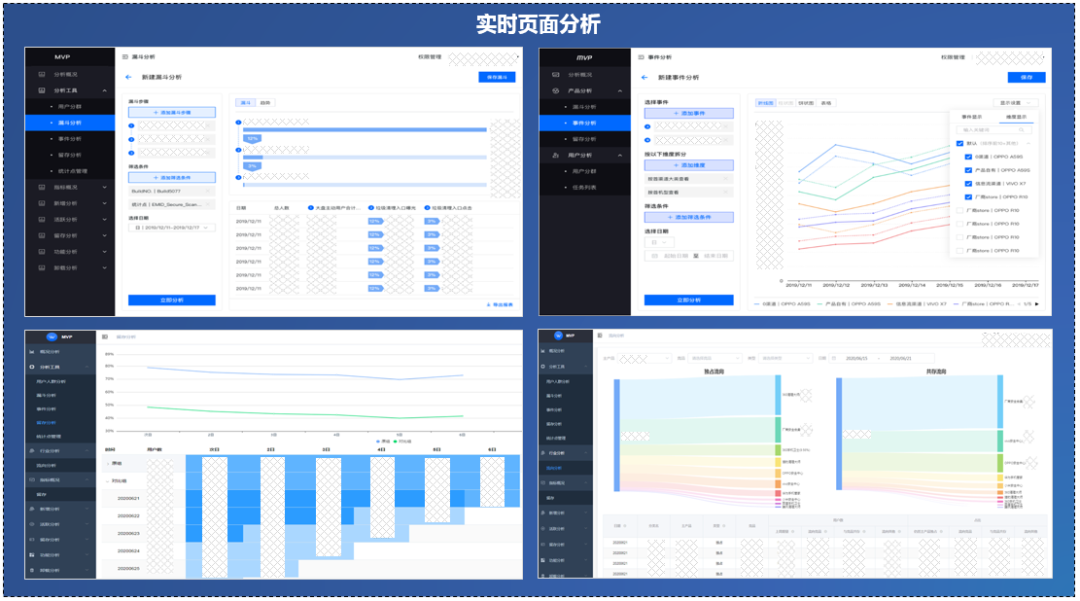
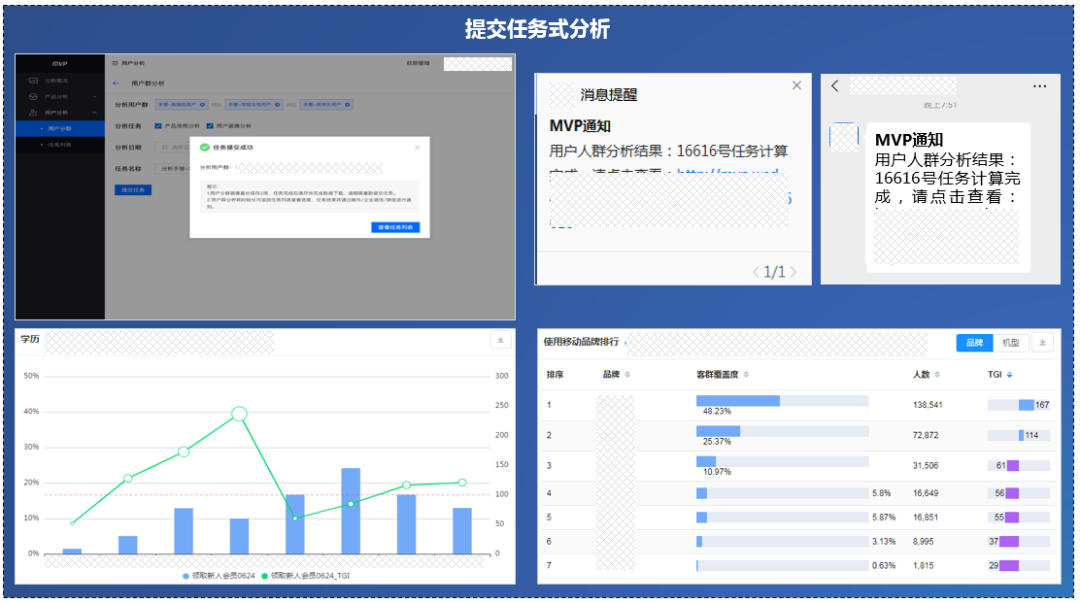
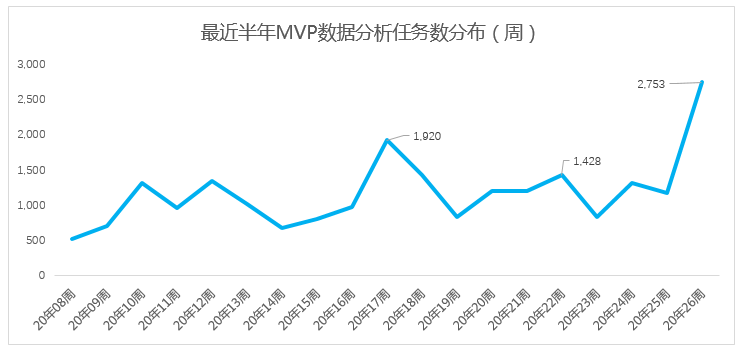
MVP乘风出海,结合先悉数据平台服务产业端
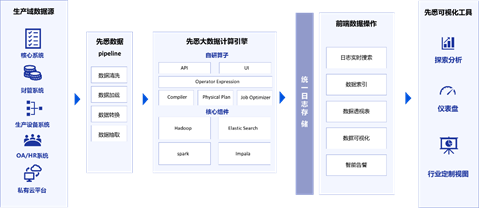
先悉功能简介:
先悉具备高性能、批流一体的大数据组件,无需自行部署各类繁杂的开源组件,快速实现私有化数据平台的部署; 先悉提供可视化任务流,作为数据开发平台,结合Spark SQL及我们提供的SPL,在图形化界面快速开发一款数据应用; 先悉自带强大可视化图表能力,可快速建立一个可视化站点,向同事、客户及领导展示您的数据指标。
[2] https://clickhouse.tech/docs/en/sql-reference/statements/create/
评论