
从0到1剖析并编码实现短链系统
30X重定向基本也就可以了。Part one 短链系统分析
判断对应短链已存在,则直接返回
判断对应短链不存在,则生成短链,并存储
长链->短链的映射关系
也可以根据短链映射到长链,寻找真实服务地址提供服务:
根据
短链->长链查询存储,获取对应的长链

条条大路通罗马,系统方案有很多,但采取哪种最合适,还需要和存储策略以及访问性能联合起来一起看~
Part two 实现方案分析
Hash策略关键点解析
Hash策略的存储设计
mysql进行结构化存储比较简单:id | 短链 | 长链MD5 | 长链 | 时间戳并且需要给
短链 和 长链MD5 构建索引,供查询时使用。优点是结构化查询、结构清晰,可以设置索引提升效率;
缺点是高并发下性能需要额外关注,保存的数据要过期,理论上得进行额外处理;
redis等非结构化kv存储,则需要存储多个关系用于查询:长链MD5 -> 短链 |短链 -> 长链MD5 |长链MD5 -> 长链优点是查询性能高,可以抗量,且自带过期机制;
缺点是需要维护多个KV关系,稍显繁琐。
改进-- 自增ID+高位进制法
短链 -> 长链MD5的转化这里来下手了。短链 -> 长链MD5的存储呢?进制转换,可以知道,进制越高所占位数越少。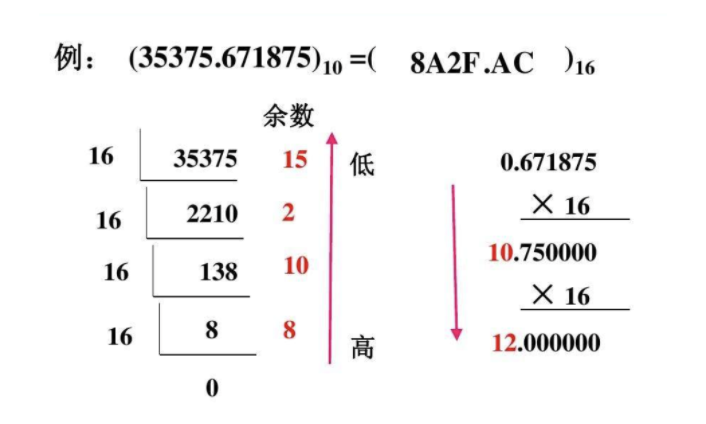
MD5应该就不太合适了,不好参与计算,因此,我们改用纯数字的分布式ID来代替MD5串(一般公司应该都有现成的分布式ID生成服务吧)。加密处理。编码实现带加密的进制转换
private static final String DIGITAL_STRING = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
//byte数组
private static final byte[] DIGITAL;
static {
DIGITAL = DIGITAL_STRING.getBytes(StandardCharsets.US_ASCII);
}public static String encode(long 分布式id) {
//内部复制
long value = id;
//创建短链所需长度的空间,这里可以限制短链长度为最多12位,最少6位
ByteBuffer buf = ByteBuffer.allocate(12);
//最多执行12次转换
for (int i = 0; i < 12; i++) {
//分布式ID对62取模
int mod = (int) (value % 62);
//加密, 再取模
int pos = (mod + (OFFSET << i)) % 62;
//根据模值从数组中获取对应的值,加入结果集中
buf.put(DIGITAL[pos]);
//求余数,用余数继续参加后续模操作,直到余数为0 或 短链长度达到要求
value = value / 62;
if (value==0 && i >= 6) {
break;
}
}
//从ByteBuffer中获取结果集合
byte[] result=new byte[buf.position()];
buf.rewind();
buf.get(result);
//反转顺序
ArrayUtils.reverse(result);
return new String(result);
}(mod + (OFFSET << i)) % 62 这个操作,其目的是在模值上加上一个偏移量(偏移大小和所处位置有关,非固定偏移) ,用来防止被直接解码。//将短链串解码为分布式ID
public static long decode(String code) {
long value = 0;
byte[] buf = code.getBytes();
int length = buf.length;
//循环次数为短链字符串长度
for (int i = 0; i < length; i++) {
byte digital = buf[i];
//当前字符对应的下标
int index = Arrays.binarySearch(DIGITAL, digital);
//当前下标需要减掉加密时增加的部分(同样和所处位置有关)
index = index - (OFFSET << (length - i - 1));
//因为减掉的有可能是一个非常大的值,再把index对62取余,如果任然小于0 ,就加上62(62进制内负变正)
index = index % 62;
if (index < 0) {
index = index + 62;
}
//10进制复原原值
value = value * 62 + index;
}
return value;
}Part three 总结
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。
评论