
学懂 ONNX,PyTorch 模型部署再也不怕!
今天开始,我们将由浅入深地介绍 ONNX 相关的知识。ONNX 是目前模型部署中最重要的中间表示之一。学懂了 ONNX 的技术细节,就能规避大量的模型部署问题。
在把 PyTorch 模型转换成 ONNX 模型时,我们往往只需要轻松地调用一句 torch.onnx.export 就行了。这个函数的接口看上去简单,但它在使用上还有着诸多的“潜规则”。在这篇教程中,我们会详细介绍 PyTorch 模型转 ONNX 模型的原理及注意事项。除此之外,我们还会介绍 PyTorch 与 ONNX 的算子对应关系,以教会大家如何处理 PyTorch 模型转换时可能会遇到的算子支持问题。

预告一下:
在后面的文章中,我们将继续介绍如何在 PyTorch 中支持更多的 ONNX 算子,让大家能彻底走通 PyTorch 到 ONNX 这条部署路线;介绍 ONNX 本身的知识,以及修改、调试 ONNX 模型的常用方法,使大家能自行解决大部分和 ONNX 有关的部署问题。敬请期待哦~
torch.onnx.export 细解
在这一节里,我们将详细介绍 PyTorch 到 ONNX 的转换函数—— torch.onnx.export。我们希望大家能够更加灵活地使用这个模型转换接口,并通过了解它的实现原理来更好地应对该函数的报错(由于模型部署的兼容性问题,部署复杂模型时该函数时常会报错)。
计算图导出方法
TorchScript 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个torch.nn.Module 模型会被转换成 TorchScript 的 torch.jit.ScriptModule 模型。现在, TorchScript 也被常当成一种中间表示使用。我们在其他文章中对 TorchScript 有详细的介绍,这里介绍 TorchScript 仅用于说明 PyTorch 模型转 ONNX的原理。
torch.onnx.export 中需要的模型实际上是一个 torch.jit.ScriptModule。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和记录(script)两种导出计算图的方法。如果给 torch.onnx.export 传入了一个普通 PyTorch 模型(torch.nn.Module),那么这个模型会默认使用跟踪的方法导出。这一过程如下图所示:

回忆一下我们第一篇教程的知识点:跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);记录法则能通过解析模型来正确记录所有的控制流。我们以下面这段代码为例来看一看这两种转换方法的区别:
import torchclass Model(torch.nn.Module):def __init__(self, n):super().__init__()self.n = nself.conv = torch.nn.Conv2d(3, 3, 3)def forward(self, x):for i in range(self.n):x = self.conv(x)return xmodels = [Model(2), Model(3)]model_names = ['model_2', 'model_3']for model, model_name in zip(models, model_names):dummy_input = torch.rand(1, 3, 10, 10)dummy_output = model(dummy_input)model_trace = torch.jit.trace(model, dummy_input)model_script = torch.jit.script(model)# 跟踪法与直接 torch.onnx.export(model, ...)等价torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)# 记录法必须先调用 torch.jit.sciprttorch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
在这段代码里,我们定义了一个带循环的模型,模型通过参数 n 来控制输入张量被卷积的次数。之后,我们各创建了一个 n=2 和 n=3 的模型。我们把这两个模型分别用跟踪和记录的方法进行导出。
值得一提的是,由于这里的两个模型(model_trace, model_script)是 TorchScript 模型,export 函数已经不需要再运行一遍模型了。(如果模型是用跟踪法得到的,那么在执行 torch.jit.trace 的时候就运行过一遍了;而用记录法导出时,模型不需要实际运行。)参数中的 dummy_input 和 dummy_output 仅仅是为了获取输入和输出张量的类型和形状。
运行上面的代码,我们把得到的 4 个 onnx 文件用 Netron 可视化:
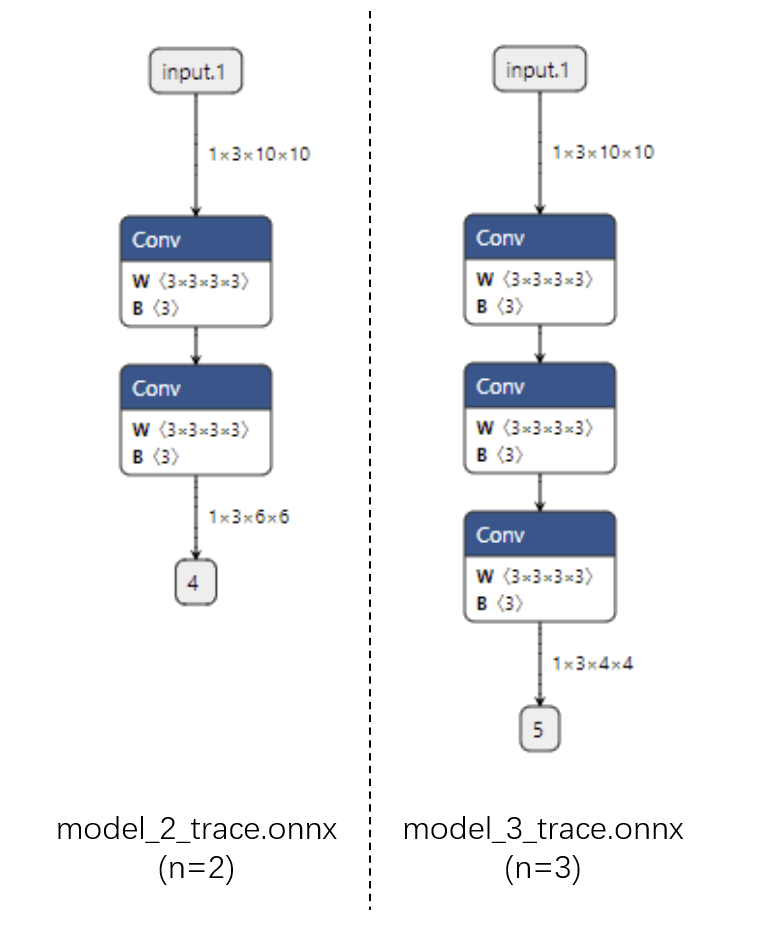
首先看跟踪法得到的 ONNX 模型结构。可以看出来,对于不同的 n,ONNX 模型的结构是不一样的。
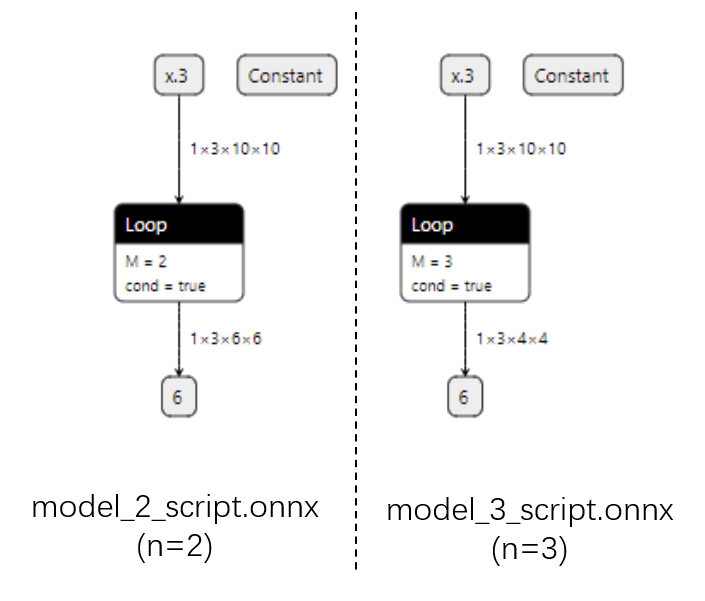
而用记录法的话,最终的 ONNX 模型用 Loop 节点来表示循环。这样哪怕对于不同的 n,ONNX 模型也有同样的结构。
由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用 torch.onnx.export 跟踪导出即可。了解这部分的知识主要是为了在模型转换报错时能够更好地定位问题是否发生在 PyTorch 转 TorchScript 阶段。
参数讲解
了解完转换函数的原理后,我们来详细介绍一下该函数的主要参数的作用。我们主要会从应用的角度来介绍每个参数在不同的模型部署场景中应该如何设置,而不会去列出每个参数的所有设置方法。该函数详细的 API 文档可参考 torch.onnx ‒ PyTorch 1.11.0 documentation。
torch.onnx ‒ PyTorch 1.11.0 documentation 链接:
https://pytorch.org/docs/stable/onnx.html#functions
torch.onnx.export 在 torch.onnx.__init__.py 文件中的定义如下:
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,input_names=None, output_names=None, aten=False, export_raw_ir=False,operator_export_type=None, opset_version=None, _retain_param_name=True,do_constant_folding=True, example_outputs=None, strip_doc_string=True,dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,enable_onnx_checker=True, use_external_data_format=False):
前三个必选参数为模型、模型输入、导出的 onnx 文件名,我们对这几个参数已经很熟悉了。我们来着重看一下后面的一些常用可选参数。
export_params
模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。
我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
input_names, output_names
设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。
ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。
在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
opset_version
转换时参考哪个 ONNX 算子集版本,默认为 9。后文会详细介绍 PyTorch 与 ONNX 的算子对应关系。
dynamic_axes
指定输入输出张量的哪些维度是动态的。
为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。
我们来看一个 dynamic_axes 的设置例子:
import torchclass Model(torch.nn.Module):def __init__(self):super().__init__()self.conv = torch.nn.Conv2d(3, 3, 3)def forward(self, x):x = self.conv(x)return xmodel = Model()dummy_input = torch.rand(1, 3, 10, 10)model_names = ['model_static.onnx','model_dynamic_0.onnx','model_dynamic_23.onnx']dynamic_axes_0 = {'in' : [0],'out' : [0]}dynamic_axes_23 = {'in' : [2, 3],'out' : [2, 3]}torch.onnx.export(model, dummy_input, model_names[0],input_names=['in'], output_names=['out'])torch.onnx.export(model, dummy_input, model_names[1],input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)torch.onnx.export(model, dummy_input, model_names[2],input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
首先,我们导出 3 个 ONNX 模型,分别为没有动态维度、第 0 维动态、第 2 第 3 维动态的模型。
在这份代码里,我们是用列表的方式表示动态维度,例如:
dynamic_axes_0 = {'in' : [0],'out' : [0]}
由于 ONNX 要求每个动态维度都有一个名字,这样写的话会引出一条 UserWarning,警告我们通过列表的方式设置动态维度的话系统会自动为它们分配名字。一种显式添加动态维度名字的方法如下:
dynamic_axes_0 = {'in' : {0: 'batch'},'out' : {0: 'batch'}}
由于在这份代码里我们没有更多的对动态维度的操作,因此简单地用列表指定动态维度即可。
之后,我们用下面的代码来看一看动态维度的作用:
import onnxruntimeimport numpy as nporigin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32)inputs = [origin_tensor, mult_batch_tensor, big_tensor]exceptions = dict()for model_name in model_names:for i, input in enumerate(inputs):try:ort_session = onnxruntime.InferenceSession(model_name)ort_inputs = {'in': input}ort_session.run(['out'], ort_inputs)except Exception as e:exceptions[(i, model_name)] = eprint(f'Input[{i}] on model {model_name} error.')else:print(f'Input[{i}] on model {model_name} succeed.')
我们在模型导出计算图时用的是一个形状为 (1, 3, 10, 10) 的张量。现在,我们来尝试以形状分别是 (1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20) 为输入,用 ONNX Runtime 运行一下这几个模型,看看哪些情况下会报错,并保存对应的报错信息。得到的输出信息应该如下:
Input[0] on model model_static.onnx succeed.Input[1] on model model_static.onnx error.Input[2] on model model_static.onnx error.Input[0] on model model_dynamic_0.onnx succeed.Input[1] on model model_dynamic_0.onnx succeed.Input[2] on model model_dynamic_0.onnx error.Input[0] on model model_dynamic_23.onnx succeed.Input[1] on model model_dynamic_23.onnx error.Input[2] on model model_dynamic_23.onnx succeed.
可以看出,形状相同的 (1, 3, 10, 10) 的输入在所有模型上都没有出错。而对于 batch(第 0 维)或者长宽(第 2、3 维)不同的输入,只有在设置了对应的动态维度后才不会出错。我们可以错误信息中找出是哪些维度出了问题。比如我们可以用以下代码查看 input[1] 在 model_static.onnx 中的报错信息:
print(exceptions[(1, 'model_static.onnx')])# output# [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
这段报错告诉我们名字叫 in 的输入的第 0 维不匹配。本来该维的长度应该为 1,但我们的输入是 2。实际部署中,如果我们碰到了类似的报错,就可以通过设置动态维度来解决问题。
使用提示
通过学习之前的知识,我们基本掌握了 torch.onnx.export 函数的部分实现原理和参数设置方法,足以完成简单模型的转换了。但在实际应用中,使用该函数还会踩很多坑。这里我们模型部署团队把在实战中积累的一些经验分享给大家。
使模型在 ONNX 转换时有不同的行为
有些时候,我们希望模型在直接用 PyTorch 推理时有一套逻辑,而在导出的 ONNX 模型中有另一套逻辑。比如,我们可以把一些后处理的逻辑放在模型里,以简化除运行模型之外的其他代码。torch.onnx.is_in_onnx_export() 可以实现这一任务,该函数仅在执行 torch.onnx.export() 时为真。以下是一个例子:
import torchclass Model(torch.nn.Module):def __init__(self):super().__init__()self.conv = torch.nn.Conv2d(3, 3, 3)def forward(self, x):x = self.conv(x)if torch.onnx.is_in_onnx_export():x = torch.clip(x, 0, 1)return x
这里,我们仅在模型导出时把输出张量的数值限制在 [0, 1] 之间。使用 is_in_onnx_export 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,is_in_onnx_export 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
利用中断张量跟踪的操作
PyTorch 转 ONNX 的跟踪导出法是不是万能的。如果我们在模型中做了一些很“出格”的操作,跟踪法会把某些取决于输入的中间结果变成常量,从而使导出的 ONNX 模型和原来的模型有出入。以下是一个会造成这种“跟踪中断”的例子:
class Model(torch.nn.Module):def __init__(self):super().__init__()def forward(self, x):x = x * x[0].item()return x, torch.Tensor([i for i in x])model = Model()dummy_input = torch.rand(10)torch.onnx.export(model, dummy_input, 'a.onnx')
如果你尝试去导出这个模型,会得到一大堆 warning,告诉你转换出来的模型可能不正确。这也难怪,我们在这个模型里使用了 .item() 把 torch 中的张量转换成了普通的 Python 变量,还尝试遍历 torch 张量,并用一个列表新建一个 torch 张量。这些涉及张量与普通变量转换的逻辑都会导致最终的 ONNX 模型不太正确。
另一方面,我们也可以利用这个性质,在保证正确性的前提下令模型的中间结果变成常量。这个技巧常常用于模型的静态化上,即令模型中所有的张量形状都变成常量。在未来的教程中,我们会在部署实例中详细介绍这些“高级”操作。
使用张量为输入(PyTorch版本 < 1.9.0)
正如我们第一篇教程所展示的,在较旧(< 1.9.0)的 PyTorch 中把 Python 数值作为 torch.onnx.export() 的模型输入时会报错。出于兼容性的考虑,我们还是推荐以张量为模型转换时的模型输入。
PyTorch 对 ONNX 的算子支持
在确保 torch.onnx.export() 的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。而具体添加算子的方法我们会在之后的文章里介绍。
在转换普通的 torch.nn.Module 模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
· 该算子可以一对一地翻译成一个 ONNX 算子。
· 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
· 该算子没有定义翻译成 ONNX 的规则,报错。
那么,该如何查看 PyTorch 算子与 ONNX 算子的对应情况呢?由于 PyTorch 算子是向 ONNX 对齐的,这里我们先看一下 ONNX 算子的定义情况,再看一下 PyTorch 定义的算子映射关系。
ONNX 算子文档
ONNX 算子的定义情况,都可以在官方的算子文档中查看。这份文档十分重要,我们碰到任何和 ONNX 算子有关的问题都得来”请教“这份文档。
算子文档链接:
https://github.com/onnx/onnx/blob/main/docs/Operators.md
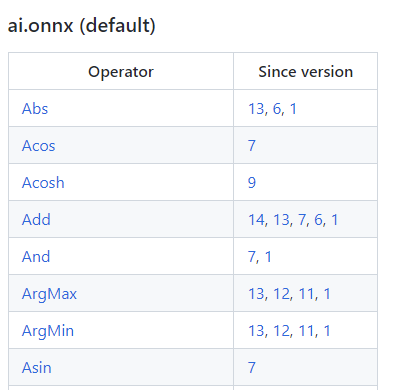
这份文档中最重要的开头的这个算子变更表格。表格的第一列是算子名,第二列是该算子发生变动的算子集版本号,也就是我们之前在 torch.onnx.export 中提到的 opset_version 表示的算子集版本号。通过查看算子第一次发生变动的版本号,我们可以知道某个算子是从哪个版本开始支持的;通过查看某算子小于等于 opset_version 的第一个改动记录,我们可以知道当前算子集版本中该算子的定义规则。
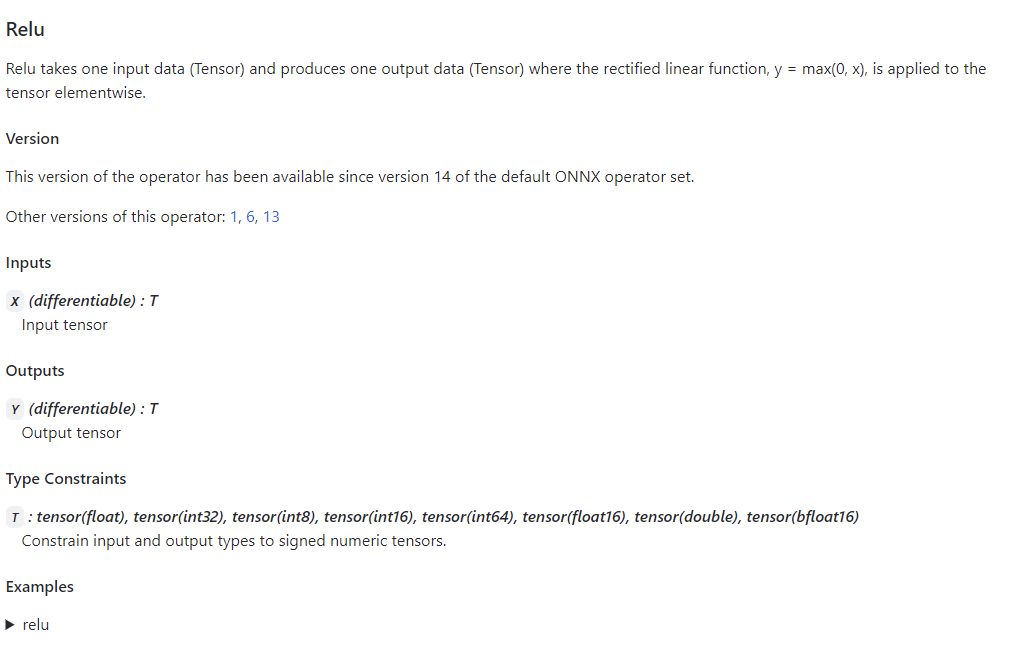
通过点击表格中的链接,我们可以查看某个算子的输入、输出参数规定及使用示例。比如上图是 Relu 在 ONNX 中的定义规则,这份定义表明 Relu 应该有一个输入和一个输入,输入输出的类型相同,均为 tensor。
PyTorch 对 ONNX 算子的映射
在 PyTorch 中,和 ONNX 有关的定义全部放在 torch.onnx 目录中,如下图所示:
torch.onnx 目录网址:
https://github.com/pytorch/pytorch/tree/master/torch/onnx
其中,symbolic_opset{n}.py(符号表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容。我们之前讲过, bicubic 插值是在第 11 个版本开始支持的。我们以它为例来看看如何查找算子的映射情况。
首先,使用搜索功能,在 torch/onnx 文件夹搜索 "bicubic",可以发现这个这个插值在第 11 个版本的定义文件中:
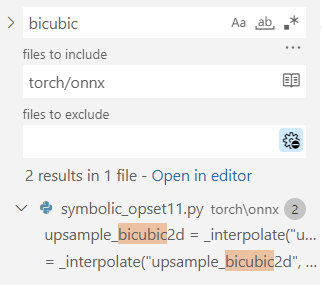
之后,我们按照代码的调用逻辑,逐步跳转直到最底层的 ONNX 映射函数:
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")->def _interpolate(name, dim, interpolate_mode):return sym_help._interpolate_helper(name, dim, interpolate_mode)->def _interpolate_helper(name, dim, interpolate_mode):def symbolic_fn(g, input, output_size, *args):...return symbolic_fn
最后,在 symbolic_fn 中,我们可以看到插值算子是怎么样被映射成多个 ONNX 算子的。其中,每一个 g.op 就是一个 ONNX 的定义。比如其中的 Resize 算子就是这样写的:
return g.op("Resize",input,empty_roi,empty_scales,output_size,coordinate_transformation_mode_s=coordinate_transformation_mode,cubic_coeff_a_f=-0.75, # only valid when mode="cubic"mode_s=interpolate_mode, # nearest, linear, or cubicnearest_mode_s="floor") # only valid when mode="nearest"
通过在前面提到的 ONNX 算子文档中查找 Resize 算子的定义,我们就可以知道这每一个参数的含义了。用类似的方法,我们可以去查询其他 ONNX 算子的参数含义,进而知道 PyTorch 中的参数是怎样一步一步传入到每个 ONNX 算子中的。
Resize 算子的定义:
https://github.com/onnx/onnx/blob/main/docs/Operators.md#resize
掌握了如何查询 PyTorch 映射到 ONNX 的关系后,我们在实际应用时就可以在 torch.onnx.export() 的 opset_version 中先预设一个版本号,碰到了问题就去对应的 PyTorch 符号表文件里去查。如果某算子确实不存在,或者算子的映射关系不满足我们的要求,我们就可能得用其他的算子绕过去,或者自定义算子了。
总结
在这篇教程中,我们系统地介绍了 PyTorch 转 ONNX 的原理。我们先是着重讲解了使用最频繁的 torch.onnx.export函数,又给出了查询 PyTorch 对 ONNX 算子支持情况的方法。通过本文,我们希望大家能够成功转换出大部分不需要添加新算子的 ONNX 模型,并在碰到算子问题时能够有效定位问题原因。具体而言,大家读完本文后应该了解以下的知识:
· 跟踪法和记录法在导出带控制语句的计算图时有什么区别。
· torch.onnx.export() 中该如何设置 input_names,output_names,dynamic_axes。
· 使用 torch.onnx.is_in_onnx_export() 来使模型在转换到 ONNX 时有不同的行为。
· 如何查询 ONNX 算子文档。
· 如何查询 PyTorch 对某个 ONNX 版本的新特性支持情况。
· 如何判断 PyTorch 对某个 ONNX 算子是否支持,支持的方法是怎样的。
这期介绍的知识比较抽象,大家会不会觉得有点“水”?没关系,下一期教程中,我们将以给出代码实例的形式,介绍多种为 PyTorch 转 ONNX 添加算子支持的方法,为大家在 PyTorch 转 ONNX 这条路上扫除更多的障碍。敬请期待哦!
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
