
复购分析实战 | Pandas遇到了大难题..(附40000+数据源和代码)
在电商等消费场景下,复购率是最耳熟能详的指标之一了。上到平台、下到品牌、店铺,各种复盘分析一定绕不开复购率,今天我们就从实战的角度聊聊复购率。
本文是Pandas实战系列的番外篇,特意总结的案例,对于pandas操作是一个很大的考验。
食用建议:略硬略干,建议食用前先喝杯水
初识复购率
实际业务经常会遇到以下场景:
“哈,我们的复购率同比/环比提升了XXX!”台下一片欣然..
“哎,近XX时间复购率有明显下降趋势”Boss脸色变得难看...
我们发现,复购率的讨论很容易陷入鸡同鸭讲,明面上都在说复购率,但实际连指标计算逻辑都是不同的:
有留存角度的,A时间段购买人数,在其后B时间段重复购买人数占比
有客户生命周期角度的,A时间段购买人数,在整个生命周期中,重复购买人数占比
有截断角度的,A时间(这个时间一般比较长)段购买人数,在A时间段重复购买人数的占比
还有自定义角度的....
各种眼花缭乱的复购计算方法,及其延伸的复购分析体系,以后会详细展开讲解。这次,我们先以一种计算逻辑切入,搞清楚如何用Pandas计算客户复购率。
复购率计算
本文采用一种比较简单,但非常考验Pandas技巧的口径来定义(可能是一些同学用pandas遇到的最大挑战)
复购率:一段时期内,购买两次及以上的客户占总人数的比重
比如最近半年,有10000个客户购买我们的产品,在这半年内,有1000个客户重复购买(购买2次及以上),那半年期复购率就是1000 / 10000 = 10%
有同学会说“订单去重之后,按照客户ID来groupby一下不就行了,有啥好讲的!”
Too young too simple~
一般拿到的订单是产品维度的,像这样:
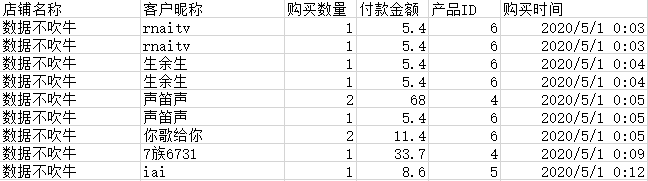
一个客户同时购买了A、B、C三款产品,后台会生成三笔产品订单,如果直接按照ID来分组统计,这种连带性质的订单都会被统计,结果指标一定非常浮夸。
“那按照日期和买家ID来去重,把当天购买的行为归为一次,再按照ID来分组统计呗”
在一些场景中,这是相对简单的计算方法,但还是不够严谨,也没有充分触达到复购的本质。
这种计算方式很容易受到特定活动和特殊产品的影响:
比如品牌在活动期连续三天搞大型秒杀活动,很多客户连续三天参与购买,这个口径下的复购率会大大注水。
比如大促期间消费者抢购一波,结果第二天发现还想购买配套产品..
对于复购的分析,我们真正在意的是客户正常的消耗周期,比如一款脱毛膏,就算全身上下涂个遍,也够用15天,那A客户1号首次购买,在3号又来购买,严格意义上是不算复购的,只能算第一次购买的补充(连带购买)
我们应该根据业务实际情况制定一个规则,即客户前后购买行为间隔超过多少天,算作复购。
下面的实战场景中,这个值定义为2:即客户后一次和前一次购买时间间隔必须大于2天,才算复购行为。
举个栗子
概念晦涩,栗子清晰:
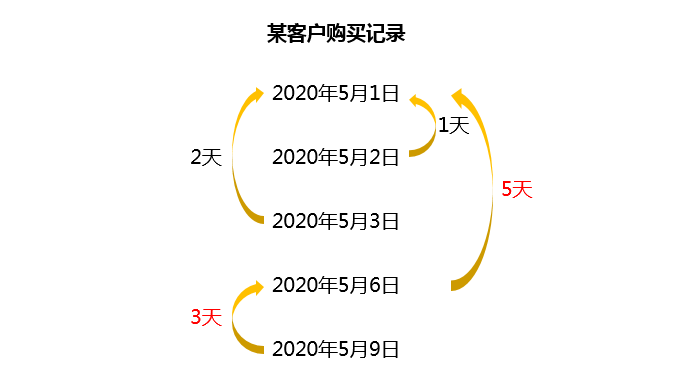
某客户,第一次购买时间是5月1日,随后5月2日又产生了购买行为,这里间隔时间只有1天,所以不算复购。
顺延下一次购买时间,5月3日和5月1日的间隔正好是2天,不满足我们大于2天算复购的定义,也不能算复购。
时间继续朝后推,5月6日和5月1日时间差整整有5天,这次购买间隔符合复购定义。记作该客户第一次复购,于是5月6日变成了新的锚点,以对比计算后续购买行为的时间差。
客户最后一次购买行为发生于5月9日,和最近的锚点5月6日有3天的间隔,亦满足我们对复购的定义,因此最后一次消费也算作复购。
总的来说,客户在5月1日-5月3日是一次购买行为,在5月6日的消费是第二次购买行为,5月9日则是第三次购买行为,整体复购了两次。
Pandas看了这个计算逻辑,感觉遇到了严峻的挑战....
Pandas实战
读取我们的案例源数据:
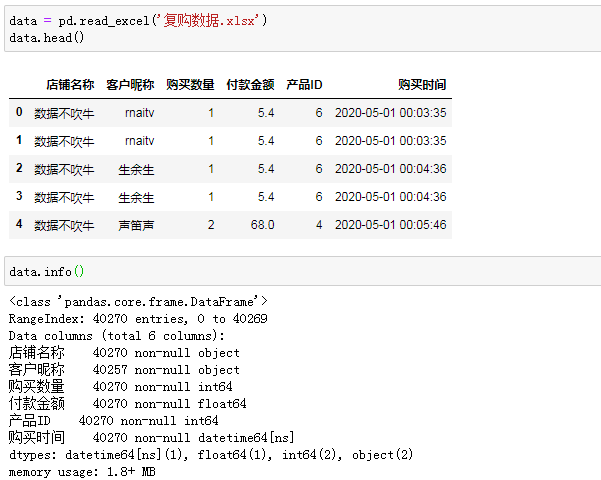
时间范围是2020年5月-6月两个月的数据,一共40270条,目标是计算两月期的复购率。
先对客户ID和付款时间做升序排列,方便后续计算:
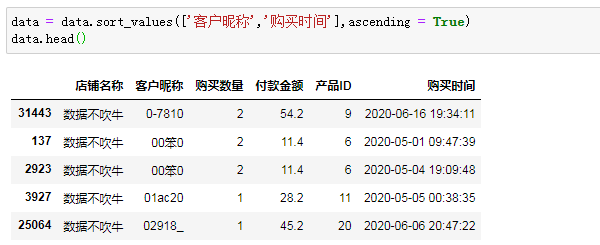
复购计算是建立在按客户ID分组的基础之上,下面的重点工作是搞定apply里面的函数。

首先,用一个空列 lst 来记录客户的复购间隔时间。当客户在时间范围内购买次数大于1时,再对客户的购买时间进行循环遍历,否则返回空列表:

接着,重点研究购买次数大于1的客户,为了有一个锚定的日期,我们引入变量anchor,当客户第二次购买时间间隔在2天以内,则用第三次购买时间和anchor做计算,依次遍历,直到找到购买时间间隔大于2的消费行为或者循环匹配完客户所有订单信息:

为了避免索引超出范围,在while循环内部,当 i 等于len(x) - 2时,跳出内部循环,否则index + 1
一旦客户两次购买行为间隔超过2天,则判定为复购行为,并且把复购时间间隔记录在lst列表
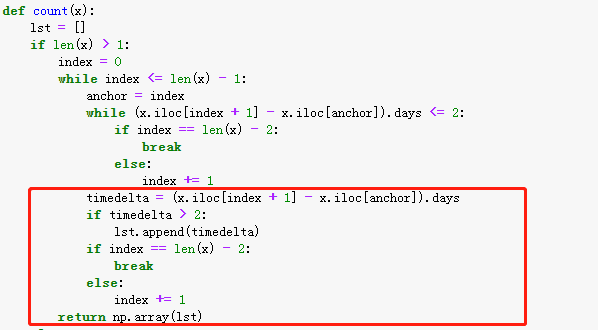
一遍复购间隔计算完之后,进行下次的循环(这里判断index同样是为了避免超出索引),最终得到的是每个客户符合定义的间隔时间列表。
把定义好的函数应用到我们的数据集上,结果如丝般顺滑:
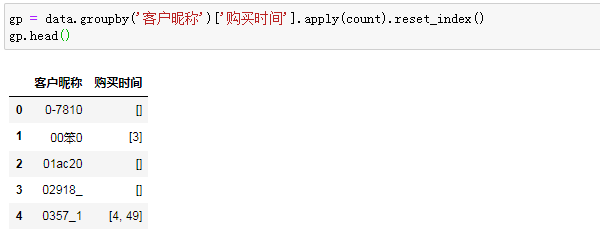
大功已经告成。计算复购率已然是信手拈来,只需要统计复购次数大于等于1的:
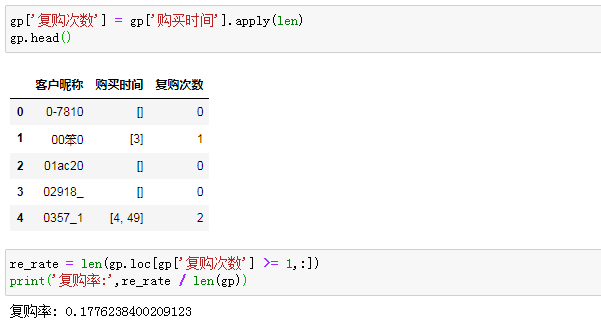
以2天作为我们的复购时间间隔,最终复购率是17.76%。
apply强大不止于此,我们对count函数略加修改,加入一个变量作为间隔,就可以自定义复购时间间隔,想大于3天就大于3天,想大于7天就大于7天,完全实现复购率的灵活计算。
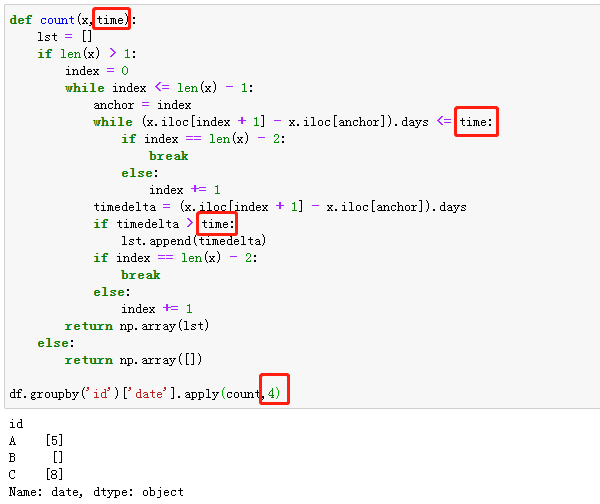
整个复购计算到此为止,问题的关键在于count函数,如何把规则用函数复现,以及索引怎样递进,需要花一些时间来思考。
最后,我已经把数据源和代码打包好,赶紧动手试试吧~
注:后台回复“复购率”,即可获取完整数据源和代码。