
100w的数据表比1000w的数据表查询更快吗?
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
当我们对一张表发起查询的时候,是不是这张表的数据越少,查询的就越快?
答案是不一定,这和mysql B+数索引结构有一定的关系。
innodb逻辑存储结构
从Innodb存储引擎的逻辑存储结构来看,所有数据都被逻辑的放在一个表空间(tablespace)中,默认情况下,所有的数据都放在一个表空间中,当然也可以设置每张表单独占用一个表空间,通过innodb_file_per_table来开启。
mysql> show variables like 'innodb_file_per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.00 sec)
表空间又是由各个段组成的,常见的有数据段,索引段,回滚段等。因为innodb的索引类型是b+树,那么数据段就是叶子结点,索引段为b+的非叶子结点。
段空间又是由区组成的,在任何情况下,每个区的大小都为1M,innodb引擎一般默认页的大小为16k,一般一个区中有64个连续的页(64*16k=1M)。
通过段我们知道,还存在一个最小的存储单元页。它是innodb管理的最小的单位,默认是16K,当然也可以通过innodb_page_size来设置为4K、8K...,我们的数据都是存在页中的
mysql> show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
所以innodb的数据结构应该大致如下:
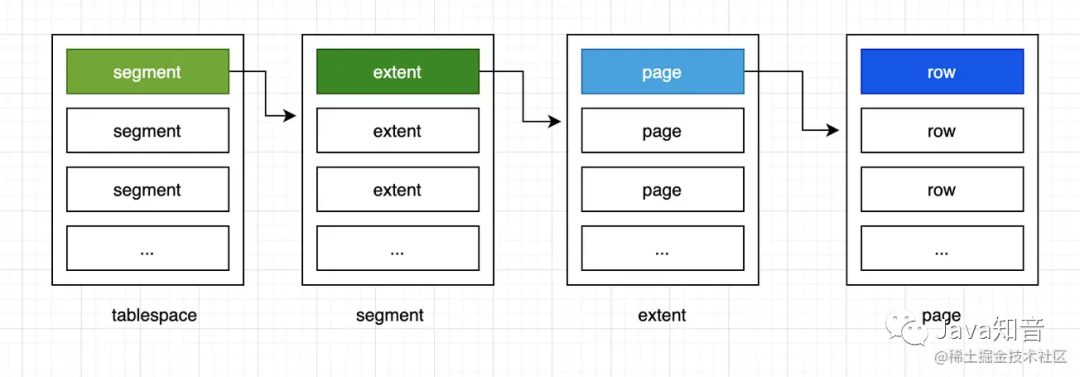
B+ 树
b+树索引的特点就是数据存在叶子结点上,并且叶子结点之间是通过双向链表方式组织起来的。
假设存在这样一张表:
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL DEFAULT '',
`age` int(10) NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
聚集索引
对于主键索引id,假设它的b+树结构可能如下:
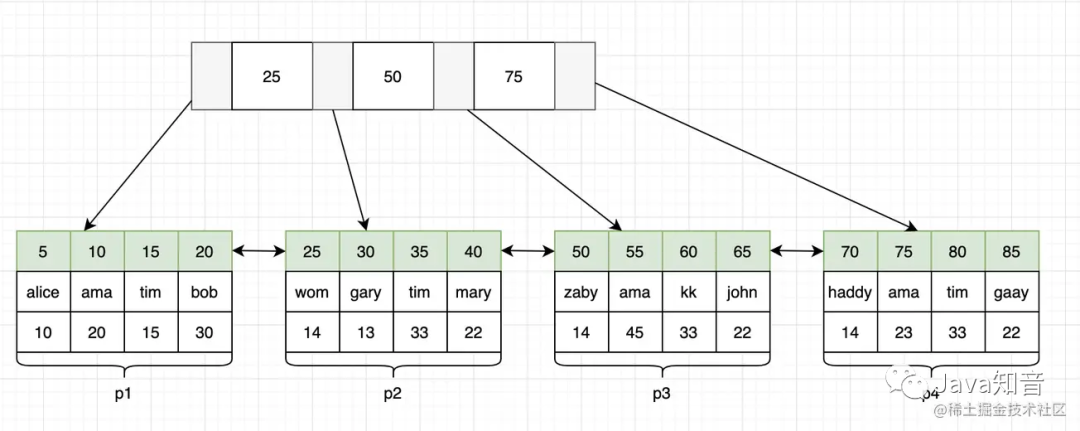
此时树的高度是2
叶子节点之间双向链表连接
叶子结点除了id外,还存了name、age字段(叶子结点包含整行数据)
我们来看看 select * from user where id=30 是如何定位到的。
首先根据id=30,判断在第一层的25-50之间
通过指针找到在第二层的p2中
把p2再加载到内存中
通过二分法找到id=30的数据
总结:可以发现一共发起两次io,最后加载到内存检索的时间忽略不计。总耗时就是两次io的时间。
非聚集索引
通过表结构我们知道,除了id,我们还有name这个非聚集索引。所以对于name索引,它的结构可能如下:
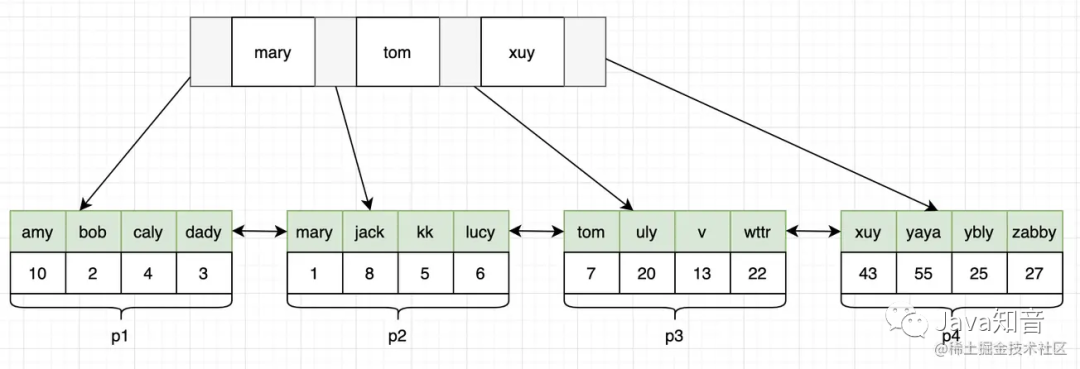
此时树的高度是2
叶子节点之间双向链表连接
叶子结点除了name外,还有对应的主键id
我们来看看 select * from user where name=jack 是如何定位到的。
首先根据name=jack,判断在第一层的mary-tom之间
通过指针找到在第二层的p2中
把p2再加载到内存中
通过二分法找到name=jack的数据(只有name和id)
因为是select *,所以通过id再去主键索引查找
同样的原理最终在主键索引中找到所有的数据
总结:name查询两次io,然后通过id再次回表查询两次io,加载到内存的时间忽略不计,总耗时是4次io。
一棵树能存多少数据
以上面的user表为例,我们先看看一行数据大概需要多大的空间:通过show table status like 'user'\G
mysql> show table status like 'user'\G
*************************** 1. row ***************************
Name: user
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 10143
Avg_row_length: 45
Data_length: 458752
Max_data_length: 0
Index_length: 311296
Data_free: 0
Auto_increment: 10005
Create_time: 2021-07-11 17:22:56
Update_time: 2021-07-11 17:31:52
Check_time: NULL
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
我们可以看到Avg_row_length=45,那么一行数据大概占45字节,因为一页的大小是16k,那么一页可以存储的数据是16k/45b = 364行数据,这是叶子结点的单page存储量。
以主键索引id为例,int占用4个字节,指针大小在InnoDB中占6字节,这样一共10字节,从root结点出来多少个指针,就可以知道root的下一层有多少个页。因为root结点只有一页,所以此时就是16k/10b = 1638个指针。
如果树的高度是2,那么能存储的数据量就是1638 * 364 = 596232条
如果树的高度是3,那么能存储的数据量就是1638 * 1638 * 364 = 976628016条
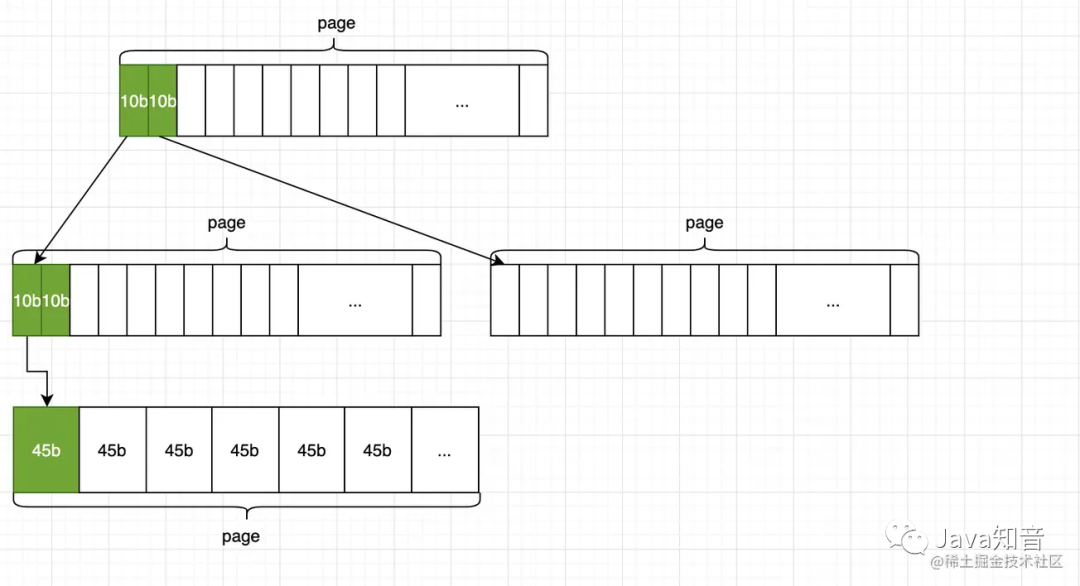
如何知道一个索引树的高度
innodb引擎中,每个页都包含一个PAGE_LEVEL的信息,用于表示当前页所在索引中的高度。默认叶子节点的高度为0,那么root页的PAGE_LEVEL + 1就是这棵索引的高度。
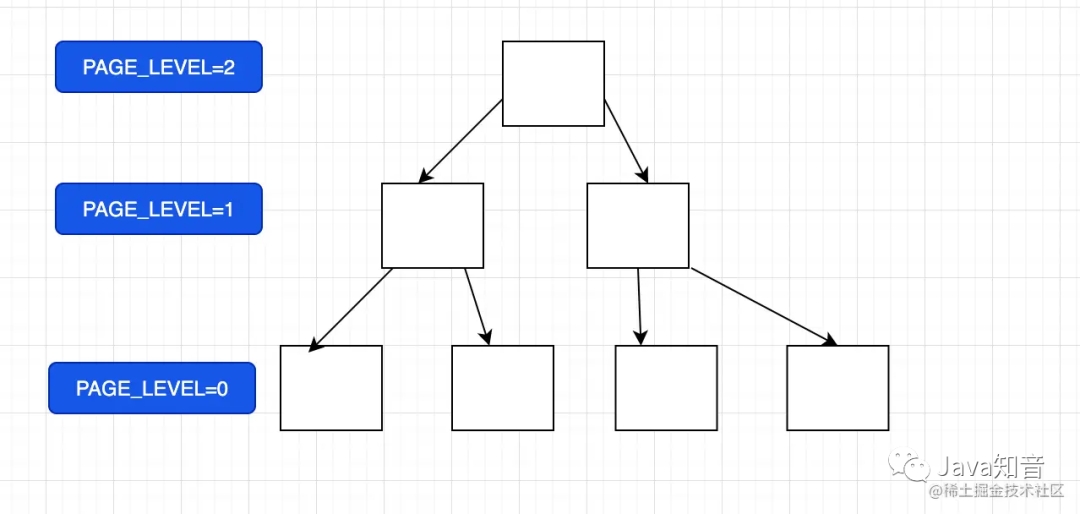
那么我们只要找到root页的PAGE_LEVEL就行了。
通过以下sql可以定位user表的索引的page_no:
mysql> SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO FROM information_schema.INNODB_SYS_INDEXES a, information_schema.INNODB_SYS_TABLES b WHERE a.table_id = b.table_id AND a.space <> 0 and b.name='test/user';
+-----------+---------+----------+------+-------+---------+
| name | name | index_id | type | space | PAGE_NO |
+-----------+---------+----------+------+-------+---------+
| test/user | PRIMARY | 105 | 3 | 67 | 3 |
| test/user | name | 106 | 0 | 67 | 4 |
+-----------+---------+----------+------+-------+---------+
2 rows in set (0.00 sec)
可以看到主键索引的page_no=3,因为PAGE_LEVEL在每个页的偏移量64位置开始,占用两个字节。所以算出它在文件中的偏移量:16384*3 + 64 = 49152 + 64 =49216,再取前两个字节就是root的PAGE_LEVEL了。
通过以下命令找到ibd文件目录
show global variables like "%datadir%" ;
+---------------+-----------------------+
| Variable_name | Value |
+---------------+-----------------------+
| datadir | /usr/local/var/mysql/ |
+---------------+-----------------------+
1 row in set (0.01 sec)
user.ibd在 /usr/local/var/mysql/test/下。
通过hexdump来分析data文件。
hexdump -s 49216 -n 10 user.ibd
000c040 00 01 00 00 00 00 00 00 00 69
000c04a
000c040 00 01 00 00 00 00 00 00 00 69
00 01就是说明PAGE_LEVEL=1,那么树的高度就是1+1=2。
回到题目
100w的数据表比1000w的数据表查询更快吗?通过查询的过程我们知道,查询耗时和树的高度有很大关系。如果100w的数据如果和1000w的数据的树的高度是一样的,那其实它们的耗时没什么区别。
来源:juejin.cn/post/6984034503362609165
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【
面试题】即可获取