
深入理解字符编码(ASCII、Unicode、UTF-8、UTF-16、UTF-32)
大家都知道,程序中的所有信息都是以二进制的形式存储在计算机的底层的,也就是说我们在代码中定义的一个 char 字符或者一个 int 整数都会被转换成二进制码储存起来,这个过程可以被称为编码,而将计算机底层的二进制码转换成屏幕上有意义的字符(如“hello world”),这个过程就称为解码。
ASCII 编码
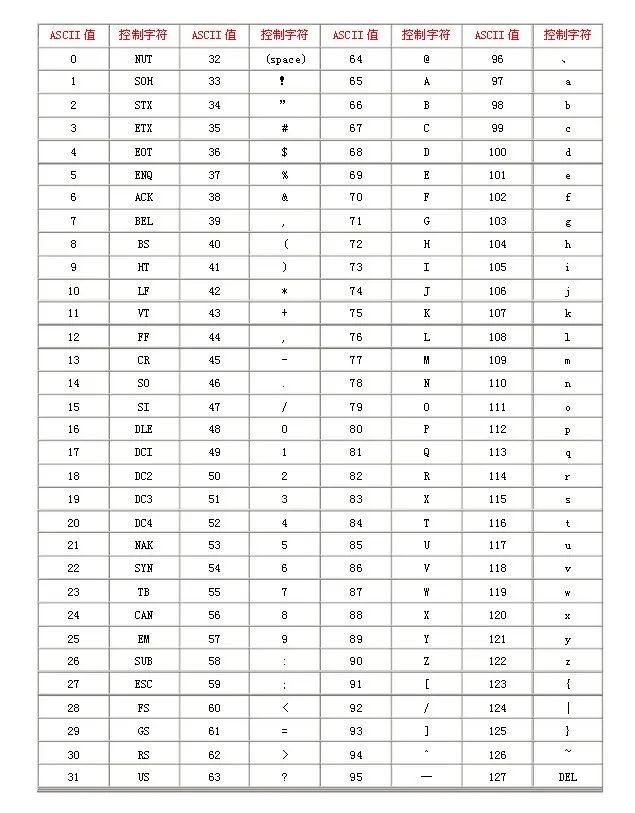
é,又制定了 ASCII 额外扩展的版本 EASCII,这里就可以使用一个完整子节的 8 个 bit 位表示共 256 个字符,其中就又包括了一些衍生的拉丁字母。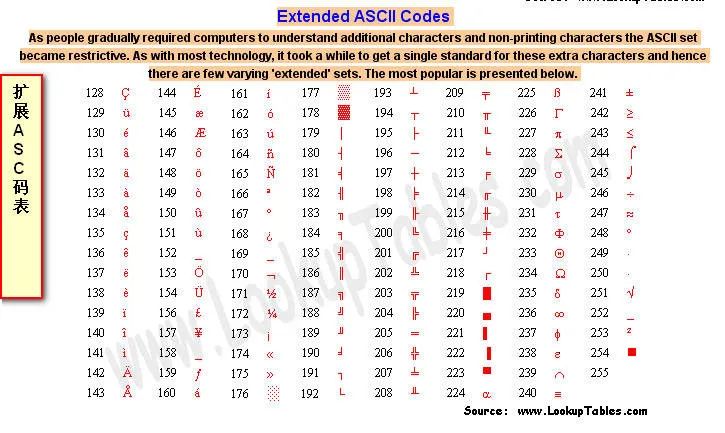
非 ASCII 编码
"一个汉字算两个英文字符!一个汉字算两个英文字符……"
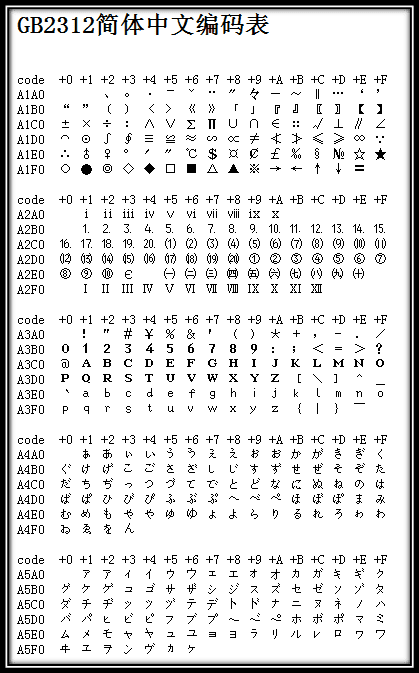
é,在希伯来语编码中却代表了字母 Gimel (ג),在俄语编码中又会代表另一个符号。但是所有这些编码方式中,0--127 表示的符号依然都是一样的,因为他们都兼容 ASCII 码,这一点,如今也是一样。Unicode
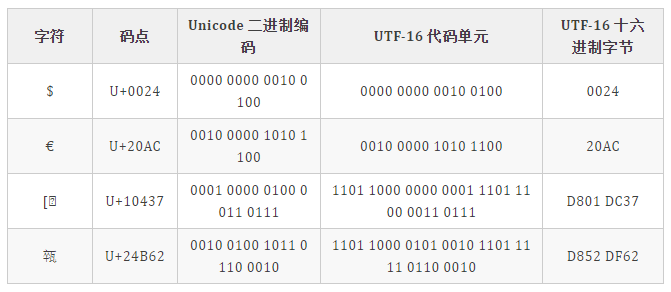
码点
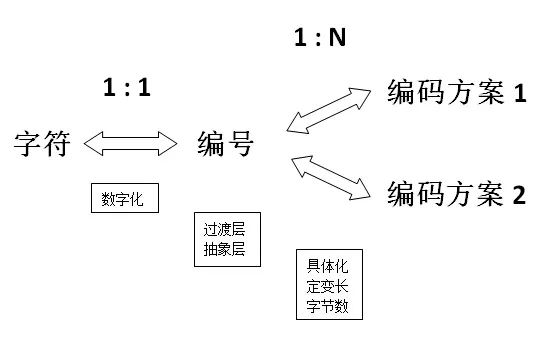
Unicode 编码

定长与变长
大富大贵没有灾难要小心
大富大贵,没有灾难要小心
大富大贵没有,灾难要小心
UTF-32
00000000 00000000 00000000 01000001
UTF-8
0,后面 7 位为这个符号的 Unicode 码。此时,对于英语字母UTF-8 编码和 ASCII 码是相同的。n 字节的符号(n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码,如下表所示: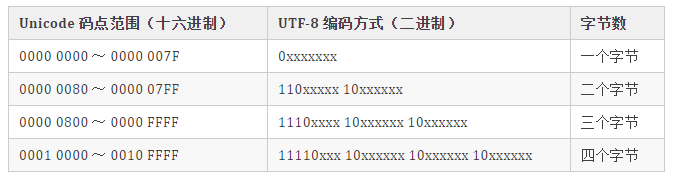

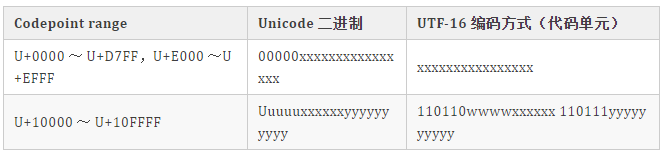
1,则连续有多少个 1,就表示当前字符占用多少个字节,"丑" 有三个 1 表示占三个字符,然后取出有效位即可。UTF-16
何为代理?
什么是代理区?

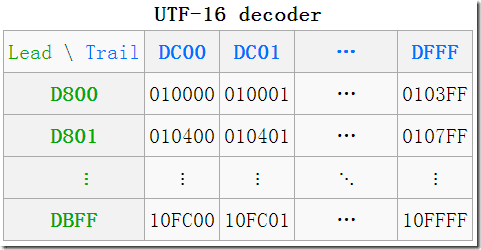
从 UTF-16 转换为字符代码的算法是什么?
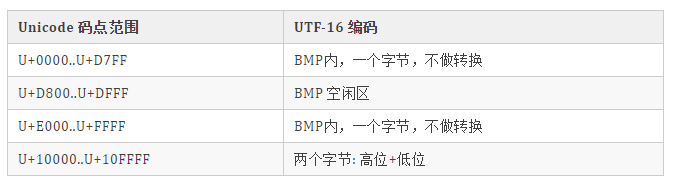
BMP 中直接对应,无须做任何转换; 增补平面 SP 中,则需要做相应的计算。其实由上图中的表也可看出,码点就是从上到下,从左到右排列过去的,所以只需做个简单的除法,拿到除数和余数即可确定行与列。 拿到一个码点,先减去 10000,再除以 400(=1024)就是所在行了,余数就是所在列了,再加上行与列所在的起始值,就得到了代理对了。
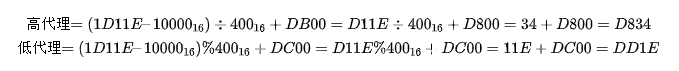
评论