
AI 助力观众更好发现媒体内容
来源:MHV‘22
主讲人:Martin Prins
内容整理:陈梓煜
本文整理了 Martin Prins 介绍的关于媒体内容“蒸馏”的技术。为了让视频观众能够快速地寻找到感兴趣的视频内容,完善视频观看过程中快速定位到感兴趣的章节的体验,他们设计了一个媒体“蒸馏”平台,可以从视频内容分析出合适的封面、概括出准确的关键词、对长视频进行准确的片段划分。
目录
媒体“蒸馏”
媒体“蒸馏”的意义
应用 1-生成视频封面
应用 2-关键词提炼
应用 3-视频自动分段
总结
媒体“蒸馏”
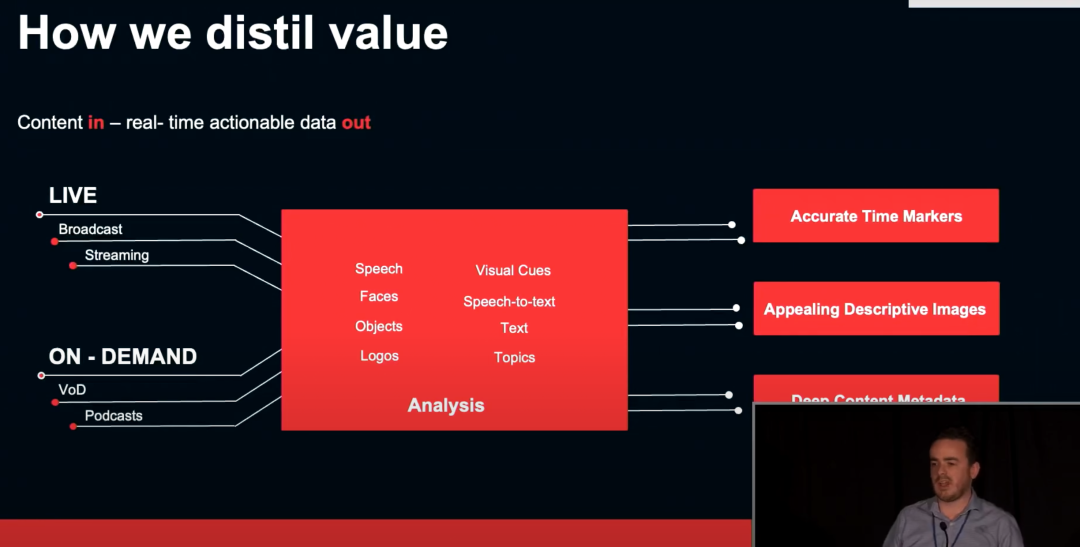
我们媒体“蒸馏”的目的是通过 AI 的手段提炼和理解视频内容来增强用户在视频平台的参与感。我们每周七天,每天 24 小时事实记录,每天都记录了 30000 小时来自 15 个国家的超过 30M 家庭拍摄的视频,这些视频都受惠于我们改善的视频观看体验。我们如何“蒸馏”媒体内容呢?我们建立了一个媒体数据实时进出的平台,在平台中实现了多种深度学习和机器学习技术来分析实时的广播或流媒体数据,通过 AI 分析媒体内容中的各种信息,例如语言、人脸、物体、话题等等,有了这些分析模型,我们可以从媒体实时的媒体数据中得到各种媒体信息,例如准确的时间戳、有吸引力的视频封面、关于内容的深度媒体数据。这些可以帮助我们设置准确的视频开场和谢幕时间,生成准确的描述封面,生成精准的视频关键词。
媒体“蒸馏”的意义
我们注意到不同年龄用户的观看习惯差异非常大,部分观众喜欢看长视频,而其他观众则喜欢看短视频,观众对直播视频和普通视频的喜好也各不相同,而我们关注的关键点是用户怎么发现他们喜欢看的视频。我们注意到年轻人对系统内置的推荐和个性化的推荐并不敏感,只有四分之一的情况会依赖系统本身的推荐或选择,而随着年龄的增长,越年长的人群越偏向于依赖流媒体播放器自带的推荐信息或搜索的信息。这对业界提出了一定挑战,流媒体供应商应该保证其网页上的推荐内容足够吸引人,足够吸引观众的兴趣,这离不开精准度视频内容匹配和精美的视频封面图片,同时还要确保用户在输入信息进行搜索时能尽可能快速找到自己想看的视频。
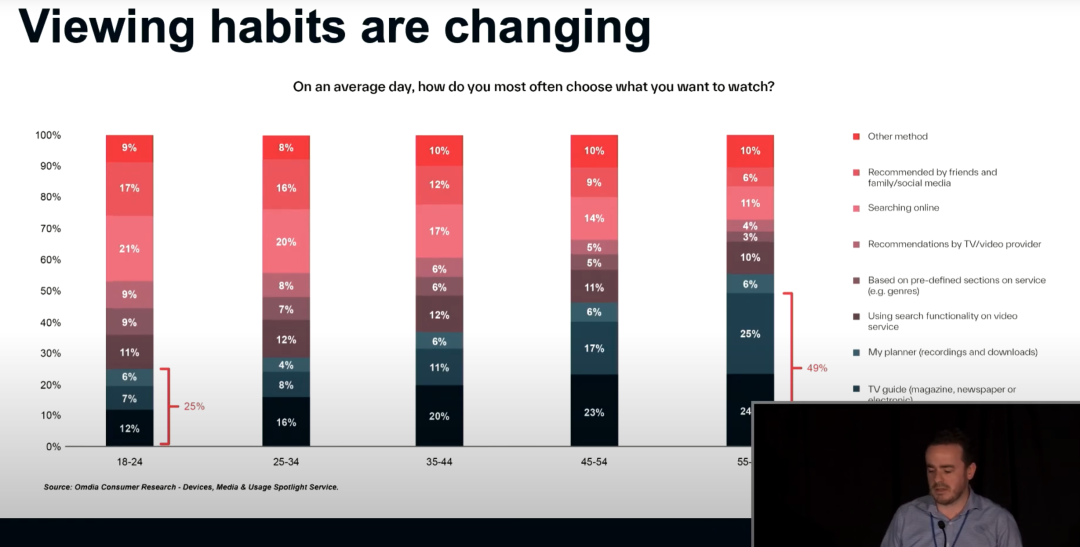
目前观众面临着一些挑战,例如非常普通的视频封面图像,这会导致观众需要很长时间才能找到适合自己的视频内容,限制了观看的自由度。部分观众可能会遇到输入关键词后无法找到想看的内容的情况,这与系统的内容推荐能力和关键词精炼能力非常相关。与此同时,用户还会面临不合理的 UI 设计带来的挑战,例如没有更好地利用时间戳将视频分段,不利于观众快速地滑动到感兴趣的部分。
应用 1-生成视频封面
为了避免视频的封面无法展示视频中的关键信息,我们使用算法提炼出实时博客的关键信息。我们的算法流程下图所示。在得到流媒体视频数据后,我们首先检测视频的主题部分,也就是检测视频正片内容的开场时间和结束时间,然后使用各种 AI 算法在这个时间区间中识别和划分视频图像的人脸,寻找节目中关键人物的人脸,我们还会检测图像中的文本、和频道的 logo,然后对检测到的部分进行裁剪,去除商业敏感的信息和视频中出现的字幕,并对提炼的图像打分,选取评分较高的图像作为视频的封面。
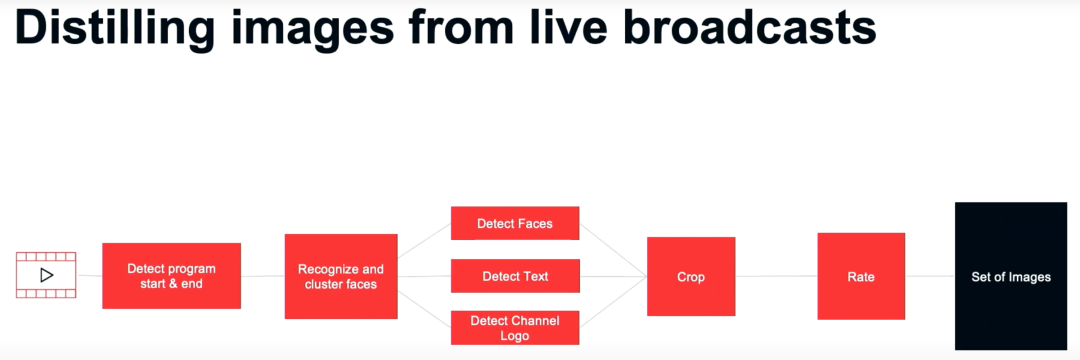
这里给出了选取视频封面的例子,我们选取包含视频主角的视频帧,去除对话的字幕并对照片进行一定的裁剪,可以得到吸引人的封面照片。在实际应用中,我们在电视网络上全自动地分发 3000 张封面图片,图片的信息对没有简介的视频的分发效果非常成功。

应用 2-关键词提炼
第二个有趣的应用是视频中涉及到的话题以及关键词的准确提炼。通常情况,直接上传的视频对用户以及视频分发系统而言是一个黑箱,我们需要提炼出视频中的关键信息以便更好地做推荐和分发。目前,直播视频例如新闻直播或体育直播,视频画面中往往包含非常多可以提炼的信息,这会对内容的关键词提炼带来困难。
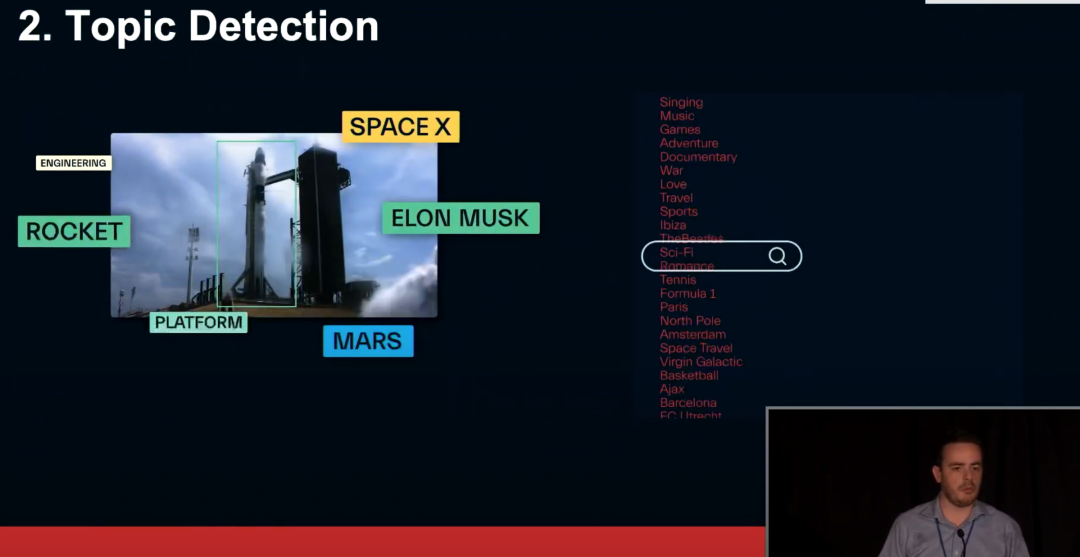
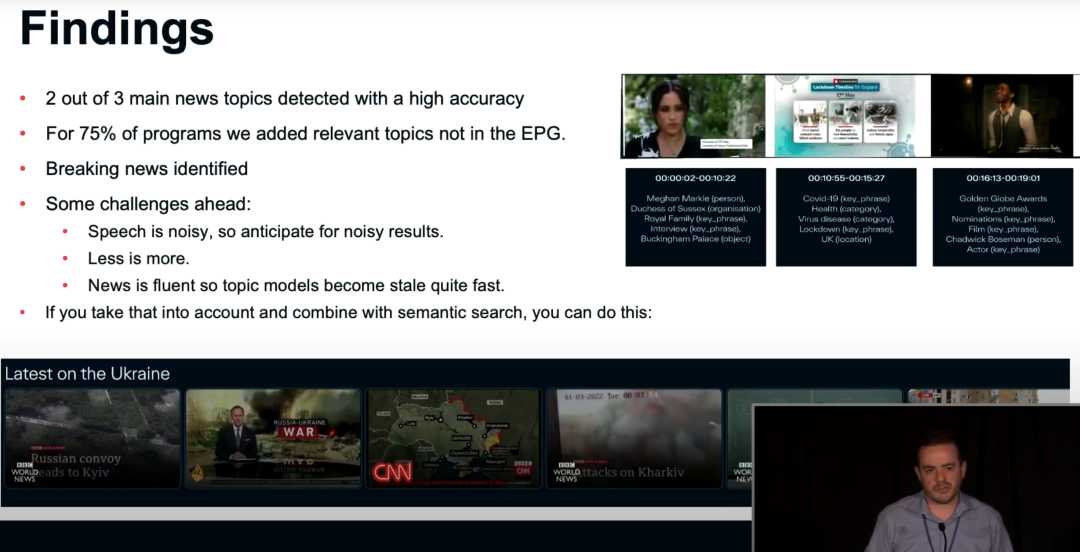
我们在进行关键词提炼时,总结了一些有趣的发现。新闻的三个主要话题中,我们的方法能以非常高的准确率识别出两个,对于 75% 的项目我们还额外预测了相关的话题,这些话题没有在 EPG 中被介绍。与此同时,我们还支持热点新闻的识别和发现。目前阶段,我们还有一些没有解决的问题:如果视频的音频噪音嘈杂,算法需要能抵抗喧闹的环境声音。我们通常可以从视频中分析出许多关键信息,但是关键信息多不意味着好,我们需要少量但是足够精准的预测。新闻的话题内容是随时变动的,所以我们的模型会收敛的很快,不能随着快速变化的新闻内容而变化。
应用 3-视频自动分段
第三个有价值的应用是视频内容的自动分段,一段视频中可能包含非常多的内容,每部分内容都有各自起始和结束的时间位置,对这些时间节点进行合理的预测,并且在 UI 界面显示出来可以帮助观众更快速定位到感兴趣的内容。通常情况下、新闻频道、体育频道、多样化的脱口秀、访谈节目中经常会包含多个不同的话题,为这些视频划分章节可以满足观众在长视频中观看短时片段的需求。
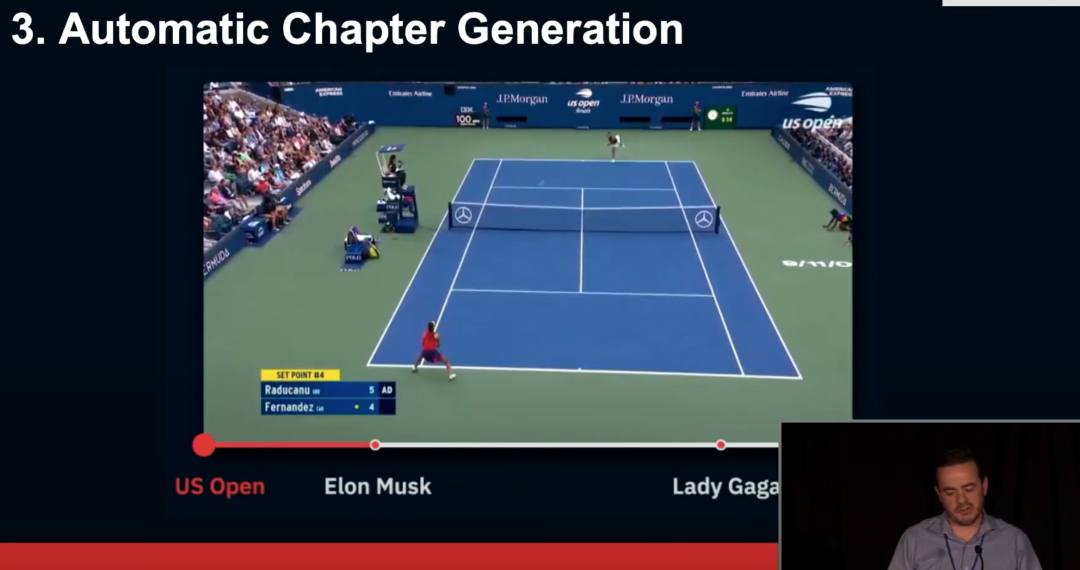
我们总结了实现这一应用时的发现。我们观察到 AI 算法模型在处理视频分段问题时效果良好,但是不存在一个通用的可以解决所有问题的模型。除此之外还有一些技术上的挑战,例如如何准确生成每章对应的子标题,如果视频中没有明显的话题切换,我们应如何划分章节?如果两个话题内容高度相似,我们又该如何划分章节。还有一些值得注意的问题,例如我们的 UI 应采用何种模式,我们划分的方式是否符合制作者的预期等等。

总结
在海量的网络视频中,观众们经常会面临各种选择,我们制作了一个有助于媒体内容提炼的平台,帮助用户快速寻找到合适的视频内容提供更好的视频选择体验。目前,我们设计的 UI 界面并不能总是满足用户的需求。我们还可以通过 AI 技术进一步完善各个应用的细节,需要帮助用户更快地找到合适的内容。
附上演讲视频: