
Redis 如何简化实现微服务的设计模式?
相关阅读:杭州程序员从互联网跳央企,晒一天工作和收入,网友:待一年就废
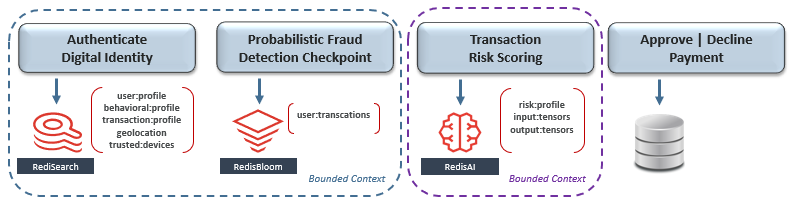
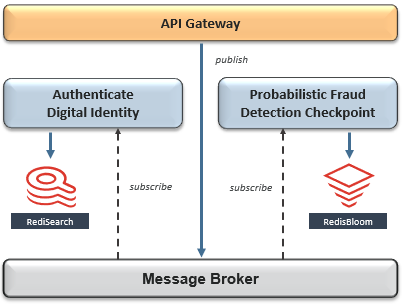
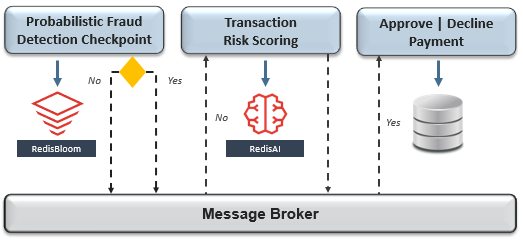
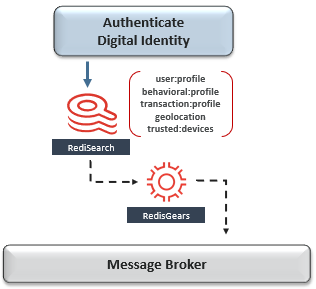

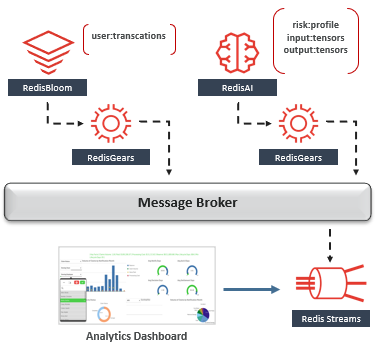
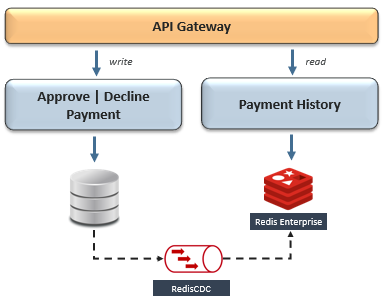
在这种情况下,以下是一些适用的模式,其中Redis简化了实现:

相关阅读:2T架构师学习资料干货分享
这是要抓住的地方-尽管这些模式解决了一些有限上下文之间的共享数据,但它们都无法在全球范围内扩展。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
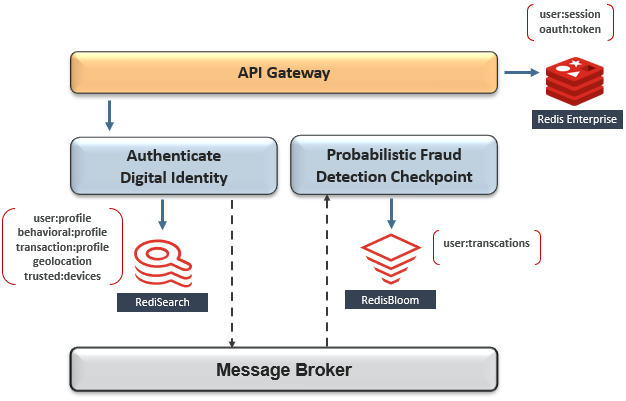
Redis Enterprise是关键任务会话数据,身份验证令牌和临时数据存储的事实上的标准,具有亚毫秒级的规模性能,并具有Active-Active跨集群复制和多可用性区域部署的99.999%SLA。
评论