本文讨论Redis如何简化微服务中设计模式的实现:例如有界上下文,异步消息传递,基于编排的sagas,事件源,CQRS,遥测等。Martin Fowler,Chris Richardson以及其他思想领袖早已解决与微服务架构和定义的相关特性的权衡,成功指导实施。包括的原则又:隔离、自主团队授权、拥抱最终一致性以及基础设施的自动化。虽然遵循这些原则可以避免早期采用者和DIY者所遭受的痛苦,但将它们合并到体系结构中的复杂性扩大了对最佳实践和设计模式的需求,尤其是随着实现扩展到数百个微服务时。我们的第一个挑战是从逻辑上将业务划分为多个微子域,以便每个人都可以由一个授权的小型自治团队提供支持。每个子域的范围应受其团队管理其支持的微服务生命周期的能力的约束-从开始到后期制作。这种从临时项目到自主域所有权的转变激发了对微服务设计各个方面的责任感,并赋予了敏捷的决策能力-从而缩短了产品上市时间。在我们的模型体系结构的上下文中,让我们从付款处理域开始,开始组织设计过程,该域包括欺诈检测,付款,结算等。由于这个范围对于一个小型团队来说可能太复杂了,因此,我们选择将其所有权范围缩小到欺诈检测子域。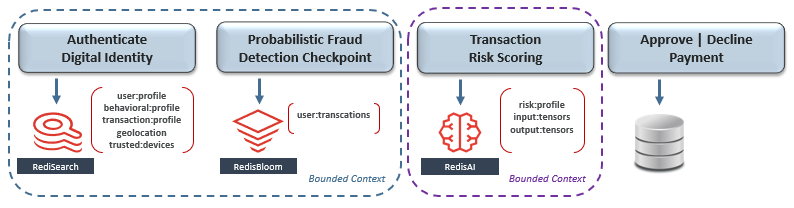
欺诈检测由工作流的前三个微服务组成-包括数字身份,统计分析和基于AI的交易风险评分。由于他们的范围可能仍然太小而无法管理,因此让我们将欺诈检测进一步分为两个子域-最终看起来更易于管理。尽管每个微服务都需要自己的最佳数据模型来处理其独特的数据访问模式和SLA,但使用Redis就不必需要评估、内置、管理三个不同的数据库。实际上,使用Redis Enterprise,他们可以在单个多租户群集中部署所有三个Redis数据库,而无需考虑其发布周期。 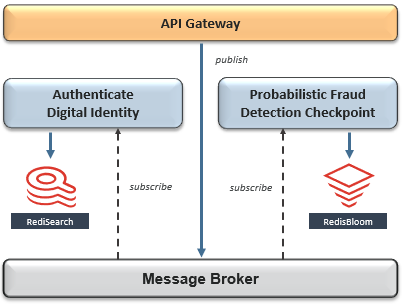
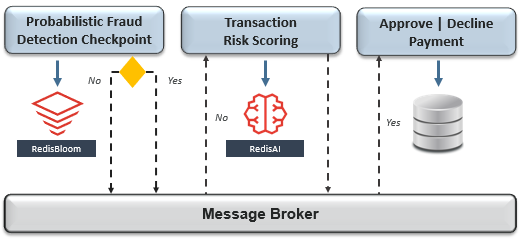
回想一下,我们的付款处理工作流程由多个微服务组成,这些微服务组织到单独的有界上下文中,并由Redis(NoSQL数据库)支持。在这种情况下,推荐的处理分布式事务的模式是基于编排的Saga,它执行一系列隔离的本地事务,并发布事件,从而促进工作流阶段之间的过渡。值得注意的是,在基于编排的Saga中,没有中央协调器,这避免了将参与的微服务的发布周期耦合在一起。但是,它并不总是正确的解决方案。在某些情况下,强一致性是绝对必要的,例如帐户转帐。在这种情况下,基于编排的Saga可能会更适合,或者在同一有限上下文中依靠微服务之间的2PC。既然我们已经设计了跨越多个有界上下文的事务,那么我们的下一个挑战是减轻微服务的数据库和消息代理之间的不一致风险,即使两者都使用Redis。回想一下,在前两种设计模式中,每个微服务都在本地提交到其数据库,然后发布了一个事件。如果使用双写模式的某些变体来实现此目的,则通信可能会丢失并且分布式事务可能会变得孤立(尤其是在云环境中)。
现在,我们已经减轻了主数据库和辅助数据平台之间不一致的风险,我们的下一个挑战是衡量整个体系结构及其支持的业务交易中微服务的运行状况,即可观察性。观测是充满了数以百计的分布式系统中的一个必须具备的孤立和最终一致的部件。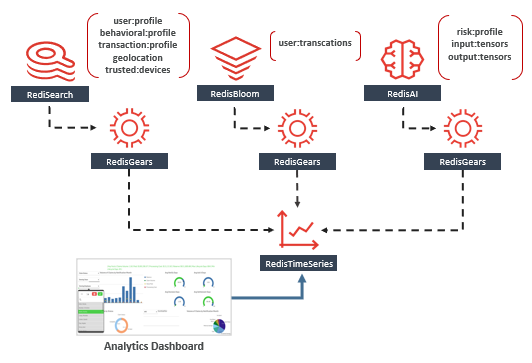
现在,RedisTimeSeries中提供了指标,我们可以跨多个维度实时查询它们-业务KPI,应用程序SLA / SLO,基础架构利用率等。使用RedisInsight可视化基础架构级别的指标。以及使用用于Grafana的Redis数据源可视化业务级别指标。既然我们已经对度量标准数据实施了遥测,那么我们的下一个挑战是启用可观察性的其余支柱-日志记录和可追溯性。与指标不同,时间序列数据模型将无法使日志的固有属性受益,因为它们无法汇总或缩减采样。相反,它们需要一个不可变且按时间排序的数据结构,该结构可用于按事件发生的顺序审核,恢复或重放事件链。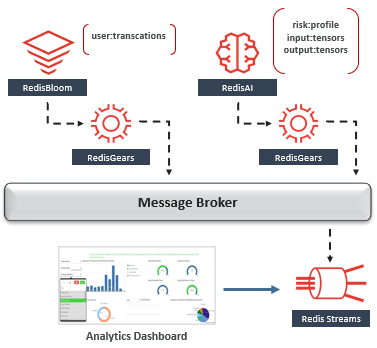
通常使用消息代理和事件存储来实现事件源。回想一下,我们已经实现了使用RedisGears捕获更改数据事件并将其存储在Redis Streams中的模式,Redis Streams是一个不可变的按时间顺序排列的日志数据结构。因此,Redis可用作数据库,消息代理和事件存储。现在,我们已经在Redis Streams中捕获了更改数据事件,我们可以使用可观察性的不同过滤器(微服务ID,事务关联ID等)以本地方式可视化它们。设计模式:命令查询责任隔离(CQRS)->性能
请注意,当我们定义与欺诈相关的有界上下文时,我们省去了付款处理工作流程的最后阶段。这是因为其授权的自治团队选择了非Redis数据库来支持其微服务。
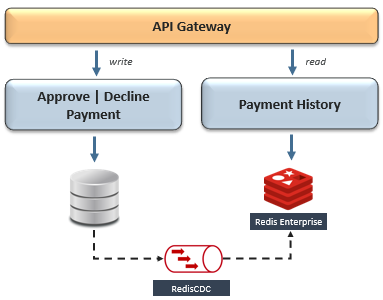
推荐的模式是CQRS,它将数据集的写(命令)和读(查询)责任分开。通过使用单独的数据库来实现CQRS,可以优化数据结构或数据模型,以适应隔离区两侧的数据访问模式及其各自的SLA。由于我们的目标是优化性能,因此数据复制的方向通常会从基于磁盘的数据库(例如MongoDB,Cassandra,RDBMS等)导入Redis。在这种情况下,我们可以通过使用可以与Command和Query数据库集成的Change Data Capture(CDC)框架来简化CQRS的实现。CDC框架通常使用事务日志拖尾或轮询发布者模式来扫描Command数据库上的更改数据事件,并将它们作为转换后的有效负载复制到Query数据库。请注意,这与在缓存旁模式中使用Redis有何不同,因为它不会在微服务级别耦合数据库—保持隔离。既然我们已经解决了在Redis不在记录系统中时优化性能的问题,那么我们的下一个挑战是处理微服务之间的共享数据,这些服务由不同的受限上下文或微服务体系结构之外的数据库分隔。在这种情况下,以下是一些适用的模式,其中Redis简化了实现:
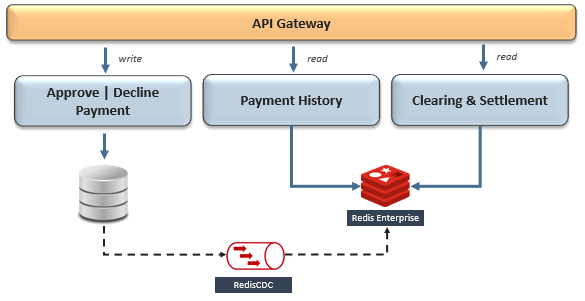
这是要抓住的地方-尽管这些模式解决了一些有限上下文之间的共享数据,但它们都无法在全球范围内扩展。搜索公众号互联网架构师复“2T”,送你一份惊喜礼包。
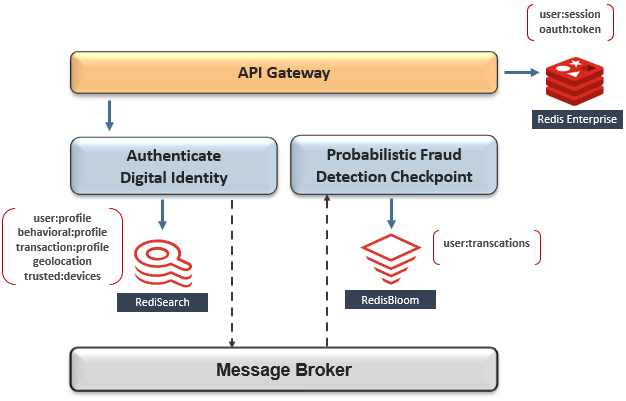
Redis Enterprise是关键任务会话数据,身份验证令牌和临时数据存储的事实上的标准,具有亚毫秒级的规模性能,并具有Active-Active跨集群复制和多可用性区域部署的99.999%SLA。

 下载APP
下载APP