收藏!用Python一键批量将任意结构的CSV文件导入MySQL数据库.
共 3854字,需浏览 8分钟
· 2020-02-05
Python有很多库可以对CSV文件和Excel文件进行自动化和规模化处理。但是,使用数据库可以将计算机完成任务的能力提升成千上万倍!
那么问题来了,如果有很多个文件需要导入数据库,一个一个操作效率太低了,有没有批量处理的方法?
★本文就来分享一下,如何通过 Python 将任意结构的CSV文件导入MySQL数据库。不管你的CSV文件存在哪里,也不管你的CSV文件有几个字段。用下面的代码,都可以实现一键批量导入!
”
数据源:本文以贵州茅台(600519)、古井贡酒(000596)、口子窖(603589)三个上市公司的资金流向历史交易数据为例(起止日期:2001-8-27至2020-1-23,相关数据可以从网易财经下载)。同时手动新建了test1.csv和test2.csv两个测试CSV文件,用来测试程序的通用性。数据结构见下图:
 资金流向历史交易数据.png
资金流向历史交易数据.png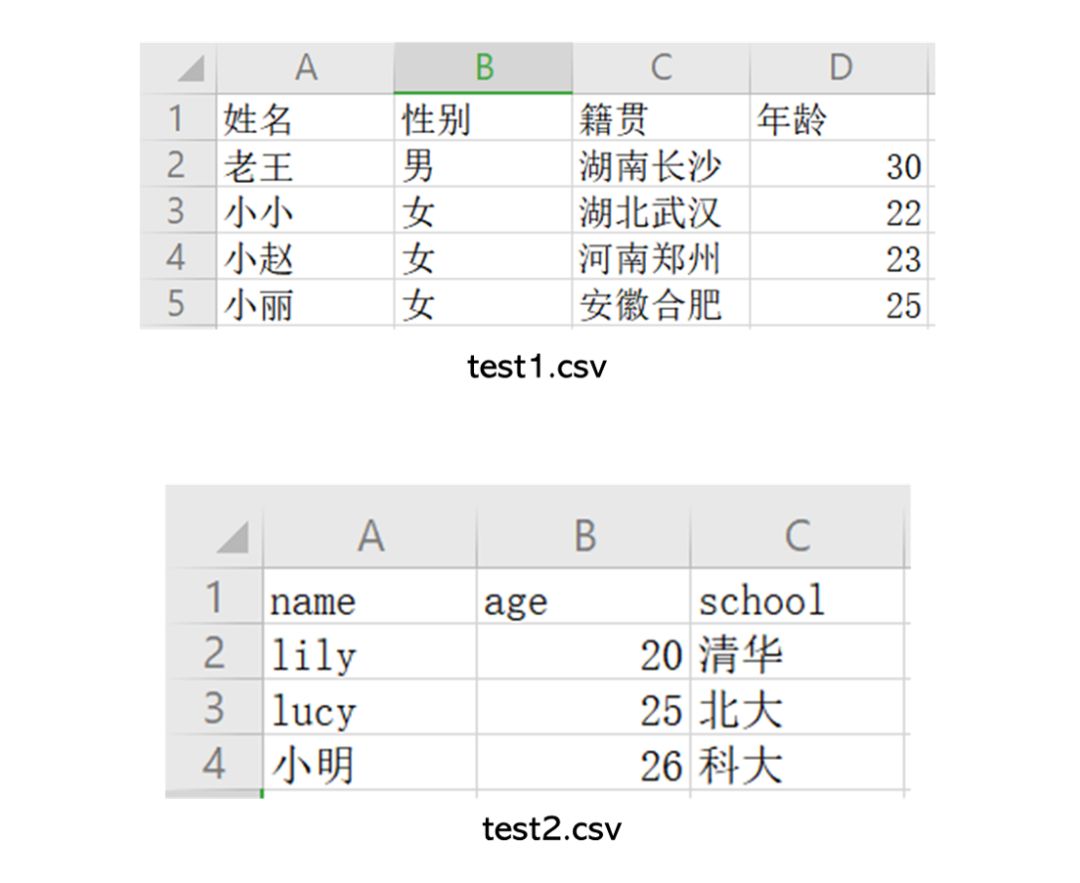
先来看看程序运行效果图:
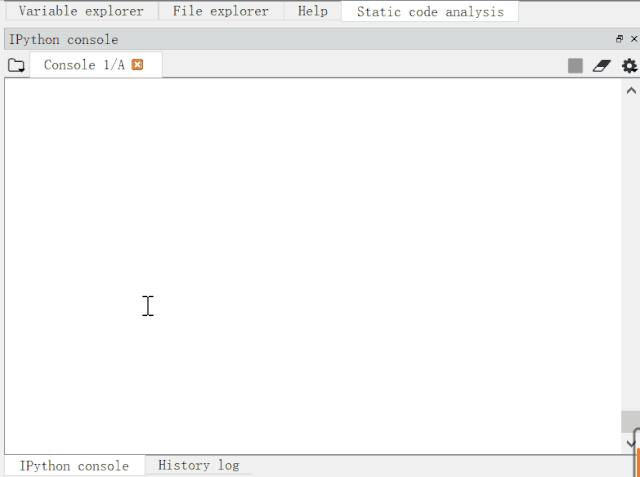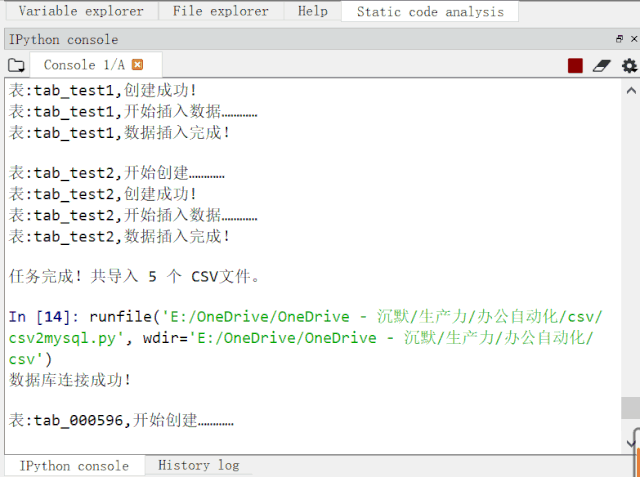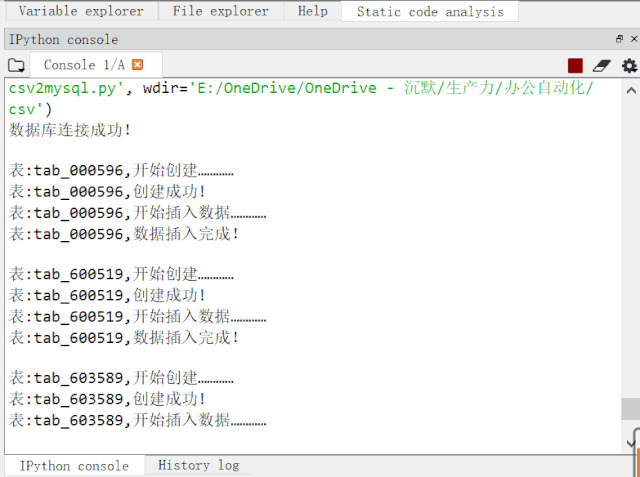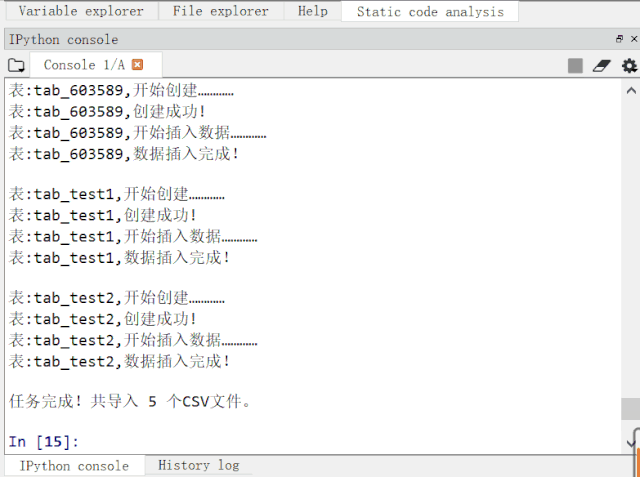 运行动图演示.gif
运行动图演示.gif我们再来查询下贵州茅台(600519)的所有数据:
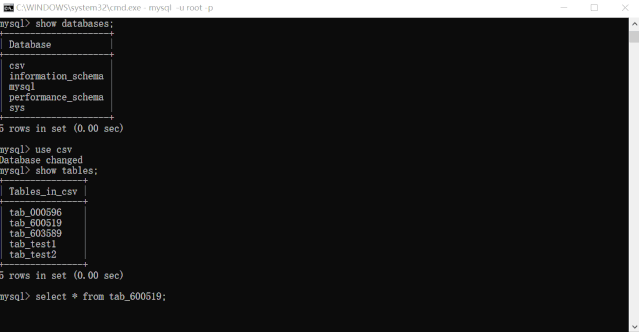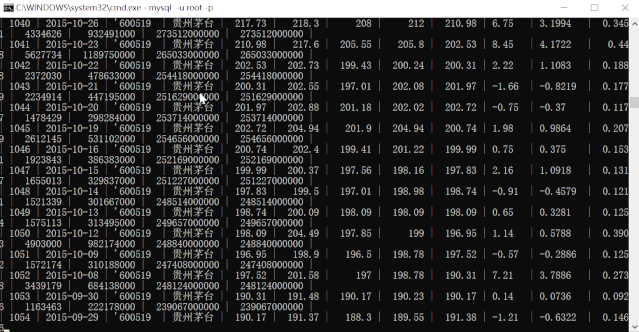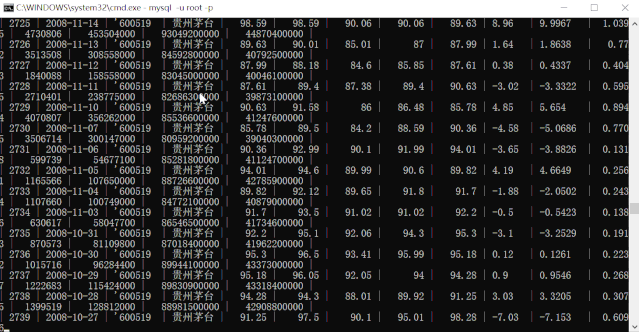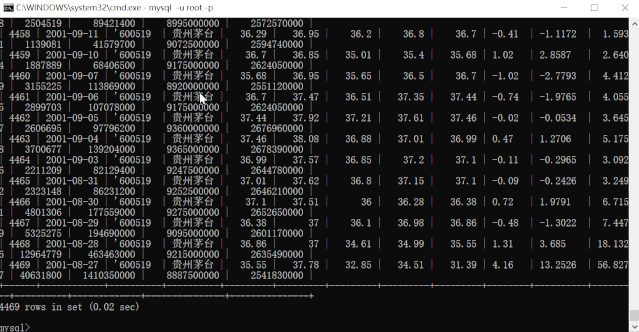
可见,5 个 CSV 文件,结构不安全相同,共 1W+ 数据,导入 MySQL 数据库也就是几秒种的事情。比手动导入效率高太多了!
如果你有成千上万个 CSV 文件,用这个程序也就是一键操作,剩下的耐心等待就行。
下面就来分析下该程序的实现逻辑吧。
1. 连接 MySQL 数据库
操作之前,你的必须完成安装并启动 MySQL 服务。如果还没有安装 MySQL,可以参考我的文章:7步完成MySQL配置,极简教程,还不来试试?
然后用 Python 连接 MySQL 数据库:
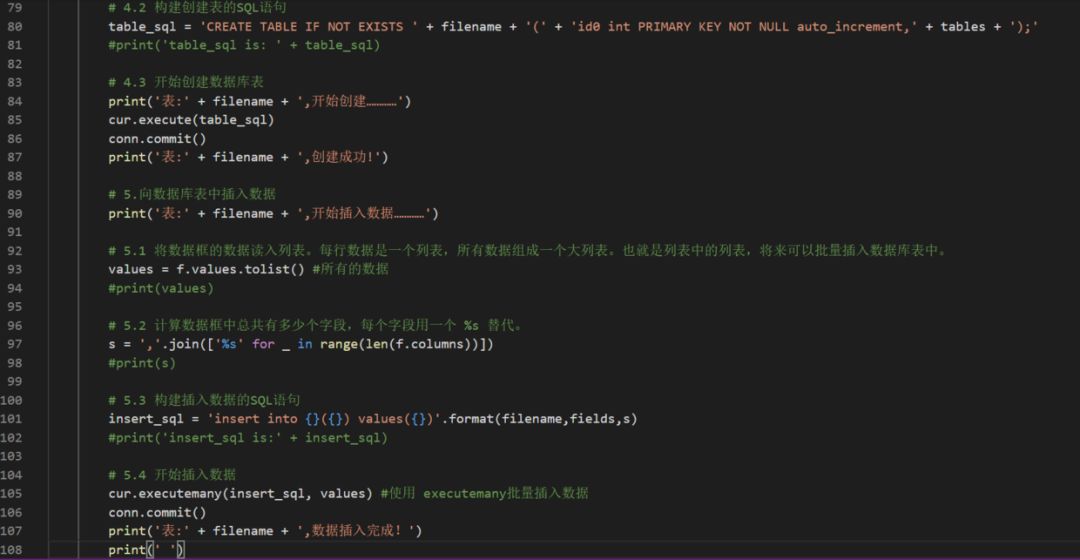
# 1. 连接 Mysql 数据库try:conn = pymysql.connect(host='localhost', user='root', password='123456', db='csv', charset='utf8')cur = conn.cursor()print('数据库连接成功!')print(' ')except:print('数据库连接失败!')
我事先已经新建了一个csv数据库,用来存储本文涉及的数据。
2. 读取任意文件夹下的CSV文件
这个程序不限制CSV文件的位置,需要用到os模块,通过下面的代码来实现:
path = os.getcwd()files = os.listdir(path)for file in files:if file.split('.')[-1] in ['csv']:
具体操作方式可以参考我的文章:让你的程序学会自己戴'口罩'!让你的程序更聪明?本文介绍了获取任意路径下文件名称的 2 种方法。
3. 计算 SQL 语句片段
本文涉及的 SQL 语句片段主要有两个,一是创建表的 SQL 语句片段,另一个是插入数据的 SQL 语句片段。
3.1 计算创建表的 SQL 语句片段
我们需要让程序计算出这样一个创建表的 SQL 语句:CREATE TABLE IF NOT EXISTS tab_600519(id0 int PRIMARY KEY NOT NULL auto_increment,日期 VARCHAR(255),股票代码 VARCHAR(255),名称 VARCHAR(255),收盘价 FLOAT,最高价 FLOAT,最低价 FLOAT,开盘价 FLOAT,前收盘 FLOAT,涨跌额 VARCHAR(255),涨跌幅 VARCHAR(255),换手率 FLOAT,成交量 INT,成交金额 FLOAT,总市值 FLOAT,流通市值 FLOAT);
(1)计算表名称
我们根据 CSV 文件的名称来计算出类似tab_表名称的数据库表名称,可以通过以下代码实现:
filename = file.split('.')[0]filename = 'tab_' + filename
将计算出的数据库表名称赋值给filename,供程序调用。
(2)计算字段及字段类型
这是难点!也是整个程序的关键所在。
① 获取 CSV 文件的表头
f = pd.read_csv(file, encoding='gbk')columns = f.columns.tolist()
我们用 pandas 的 read_csv 将 CSV 文件的所有内容读取到数据库 f中。数据框是pandas的数据存储结构,保留了表格的数据存储方式。
然后将数据框 f 的表头读入 columns中。
② 转换字段类型
由于 CSV 文件的字段类型与 MySQL 的字段类型不同,因此我们需要遍历 columns中的字段及其类型,修改成 MySQL 能识别的字段类型。
types = f.ftypesfield = []table = []for item in columns:if 'int' in types[item]:char = item + ' INT'elif 'float' in types[item]:char = item +' FLOAT'elif 'object' in types[item]:char = item +' VARCHAR(255)'elif 'datetime' in types[item]:char = item + ' DATETIME'else:char = item + ' VARCHAR(255)'table.append(char)field.append(item)tables = ','.join(table)fields = ','.join(field)
通过上述计算:
tables = 日期 VARCHAR(255),股票代码 VARCHAR(255),名称 VARCHAR(255),收盘价 FLOAT,最高价 FLOAT,最低价 FLOAT,开盘价 FLOAT,前收盘 FLOAT,涨跌额 VARCHAR(255),涨跌幅 VARCHAR(255),换手率 FLOAT,成交量 INT,成交金额 FLOAT,总市值 FLOAT,流通市值 FLOAT
fields = 日期,股票代码,名称,收盘价,最高价,最低价,开盘价,前收盘,涨跌额,涨跌幅,换手率,成交量,成交金额,总市值,流通市值
(3)创建表完整 SQL 语句组装
创建表的 SQL 语句就可以这样组装了:table_sql = 'CREATE TABLE IF NOT EXISTS ' + filename + '(' + 'id0 int PRIMARY KEY NOT NULL auto_increment,' + tables + ');'
filenam和tables是变量,是通过 CSV 文件名称和文件结构计算出来的,这样就实现了自动化!
另外,id0 int PRIMARY KEY NOT NULL auto_increment 是创建的一个自增主键,之所以取名为 id0 而不取名 id ,是为了避免与 CSV 文件本来就有的 id 字段冲突。
创建表的 SQL 语句已组装完成,执行它就行。
3.2 计算插入数据的 SQL 语句片段
我们需要让程序计算出这样一个插入数据的 SQL 语句:insert into tab_603589(日期,股票代码,名称,收盘价,最高价,最低价,开盘价,前收盘,涨跌额,涨跌幅,换手率,成交量,成交金额,总市值,流通市值) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
filename和fields已经计算完成,现在只要计算 %s的个数和数据列表即可。
(1)计算%s的个数
根据数据框表头的长度计算出%s字符串,用逗号分隔。
s = ','.join(['%s' for _ in range(len(f.columns))])
通过计算:s = %s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s
(2)计算数据列表
通过values = f.values.tolist(),将数据框的数据读入列表。
每行数据是一个列表,所有数据组成一个大列表。也就是列表中的列表,将来可以批量插入数据库表中。
(3)插入数据完整 SQL 语句组装
创建表的 SQL 语句就可以这样组装了:insert_sql = 'insert into {}({}) values({})'.format(filename,fields,s)
执行插入数据命令:
insert_sql = 'insert into {}({}) values({})'.format(filename,fields,s)cur.executemany(insert_sql, values)conn.commit()
这里使用executemany()来插入数据,executemany()就是将列表中的元素一个个取出来,然后一条条的执行,也就是说它能同时执行多条语句。执行同样多的语句可比execute()快很多。
下面贴一下源代码片段,有需要的朋友可以去微信公众号后台下载: