
微服务架构下请求调用失败了怎么办?
点击上方“JavaEdge”,关注公众号

微服务带来的不安因素

相比单体架构,微服务架构下的服务调用从同一机器内的本地调用变成不同机器间远程调用,由此也带来如下不确定因素:
调用的执行是服务提供者,即使服务消费者本身正常,服务提供者也可能因CPU、网络I/O、磁盘、内存、网卡等各种原因调用失败,还可能因本身程序执行问题比如GC暂停导致失败
调用发生在两台机器间,所以要经过网络传输,而网络不可控,丢包、延迟或抖动都可能导致调用失败。
所以针对服务调用失败需特殊处理。
超时
微服务下的一次用户调用可能会被拆成多系统间服务调用,任一次服务调用若发生问题都可能导致用户调用最终失败。
一个系统的问题会影响所有调用这个系统所提供服务的服务消费者,导致服务雪崩。
所以针对服务调用都要设置超时时间,避免所依赖服务一直未返回结果,将服务消费者阻死。
超时时间的设定

太短,可能有些服务调用还未及时执行完成就被丢弃
太长,可能导致服务消费者被拖死
需按服务提供者线上真实的服务水平,取99.9%或99.99%的调用都在多少ms内返回为准。
重试
虽设超时时间可及时止损,但服务调用结果毕竟失败。大部分情况调用失败都因网络问题或个别服务提供者节点有问题,若能换个节点再次访问说不定就成功。
假如一次服务调用失败概率1%,那连续两次服务调用失败概率0.01%,失败率降低到原来1%。所以经常还要设置一个服务调用超时后的重试次数。
假如某服务调用超时时间设为100ms,重试次数设为1,当服务调用超过100ms后,服务消费者就会立即发起第二次服务调用,而不会再等待第一次调用返回结果。
双发
假如一次调用不成功概率1%,那连续两次调用都不成功的概率就是0.01%,一个简单的提高服务调用成功率的办法就是每次服务消费者要发起服务调用的时候,都同时发起两次服务调用,可
提高调用的成功率
两次服务调用,哪个先返回就采用哪次返回结果,平均响应时间也要比一次调用更快
这就是双发。
但这样一次调用会给后端服务两倍压力,要消耗的资源也加倍,所以“鲁莽”双发不可取。
更为聪明的双发,即
“备份请求”(Backup Requests)
服务消费者发起一次服务调用后,在给定的时间内如果没有返回请求结果,那么服务消费者就立刻发起另一次服务调用。
注意该设定时间通常要比超时时间短得多,比如超时时间取P999,那么备份请求时间取的可能是P99或P90,因为若在P99或者P90时间内调用还没有返回结果,那么大概率可以认为这次请求属于慢请求,再次发起调用理论上返回要更快。
在实际线上服务运行时,P999由于长尾请求时间较长的缘故,可能要远远大于P99和P90。
比如一个服务的P999是1s,而P99只有200ms、P90只有50ms,这样的话,如果备份请求时间取的是P90,那么第二次请求等待的时间只有50ms。
备份请求要设置一个最大重试比例,以避免在服务端出现问题时,大部分请求响应时间都会超过P90,导致请求量几乎翻倍,给服务提供者造成更大的压力。
可设置成15%
尽量体现备份请求的优势
不会给服务提供者额外增加太大的压力
熔断
前面手段在服务提供者偶发异常时很有效,但若服务提供者故障,短时间内无法恢复,都不能提高服务调用成功率,还会因重试给服务提供者带来更大的压力而加剧故障。
就需服务消费者能够探测到服务提供者发生故障,短时间内停止请求,给服务提供者故障恢复时间,待服务提供者恢复后,再继续请求。
原理
把客户端的每次服务调用用断路器封装,通过断路器监控每次服务调用。
若某段时间内,服务调用失败次数达到一定阈值,断路器就会被触发,后续服务调用直接返回,不会再向服务提供者发起请求。
熔断后,一旦服务提供者恢复

服务调用如何恢复

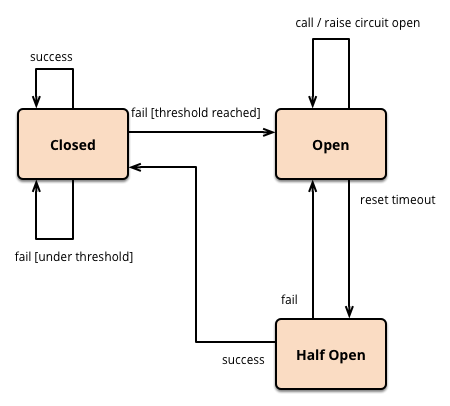
Hystrix的断路器包含三种状态:关闭、打开、半打开
Closed态
正常情况下的断路器处关闭状态,偶发的调用失败也不影响
Open态
当服务调用失败次数达到阈值,断路器就会处开启状态,后续服务调用直接返回,不会向服务提供者发起请求
Half Open态
当断路器开启,每隔一段时间,会进入半打开态,这时会向服务提供者发起探测调用,以确定服务提供者是否恢复正常。
若调用成功,断路器就关闭
若失败,断路器继续保持开启态,并等待下个周期重新进入半打开态。
Hystrix会把每次服务调用都用HystrixCommand封装,实时记录每次服务调用状态,包括成功、失败、超时还是被线程拒绝。
当一段时间内服务调用的失败率高于阈值,Hystrix的断路器就会进入进入打开态,新的服务调用直接返回,不会向服务提供者发起调用。
再等待设定时间间隔后,Hystrix的断路器又会进入半打,新的服务调用又可重新发给服务提供者。若一段时间内服务调用失败率依然高于阈值,断路器会重新进入打开态,否则,重置为关闭态。
决定断路器是否打开失败率阈值通过如下参数:
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage()断路器何时进入半打开态时间间隔通过如下参数:
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds()断路器关键在于
统计一段时间内服务调用的失败率
滑动窗口算法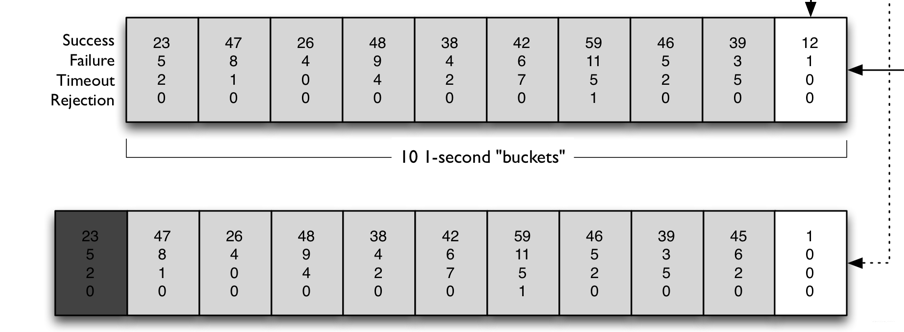
默认情况下,滑动窗口包含10个桶,每个桶时间宽度1s,每桶记录这1s所有服务调用成功、失败、超时的及被线程拒绝的次数。当新1s到来,滑动窗口就往前滑动,丢弃最旧桶,把最新桶包进来。
任意时刻,Hystrix都会取滑动窗口内所有服务调用的失败率作为断路器开关状态的判断依据,这10个桶内记录的所有失败的、超时的、被线程拒绝的调用次数之和除以总的调用次数就是滑动窗口内所有服务的调用的失败率。
总结
对非幂等,即同一服务调用重复多次返回结果不同的,不可重试,比如大部分上行请求都是非幂等。
双发是在重试基础上进行一定优化,减少超时等待时间,对于长尾请求场景很有效。采用双发后,服务调用的P999能大幅减少,是提高服务调用成功率的有效手段。
熔断能很好解决依赖服务故障引起的连锁反应,对于线上存在大规模服务调用尤其是对非关键路径的调用,即使调用失败也对最终结果影响不大的情况下,更应引入熔断。
参考
https://martinfowler.com/bliki/CircuitBreaker.html
https://github.com/Netflix/Hystrix/wiki/How-To-Use
往期推荐

目前交流群已有 800+人,旨在促进技术交流,可关注公众号添加笔者微信邀请进群
喜欢文章,点个“在看、点赞、分享”素质三连支持一下~