
Python 情人节告白特技:隐藏在聊天记录里的珍贵礼物

明天又双叒叕是一年一度的恋爱节了!
又是一波绝好的机会!恩爱秀起来!
购物车清空!礼物送起来!朋友圈晒起来!

等等!什么?!
你还没准备好礼物么?
但其实你不知道要送啥?
原来又双叒叕要到
全民不知道送什么礼物的系列日子了…

哎呦 你们这些
磨人的小(lao)妖(you)精(tiao)!
Python倒是觉得你还可以抢救一下!

说到词云应该不陌生,不知道的童靴往下看
词云,就是把网络文本中出现频率较高的
"关键词"予以视觉上的突出
浏览者只要一眼扫过文本就可以领略其主旨

瞧 这是不是一个有声音、有画面的小爱心~
今天 我们采集情侣们之间的聊天日常
用此制作一份只属于你们的小浪漫!
一、导出自己和对象的数据~
微信的备份功能并不能直接给你导出文本格式,它导出来其实是一种叫sqlite的数据库。如果说用网上流传的方法提取文本数据,iOS则需要下载itunes备份整机,安卓则需要本机的root权限,无论是哪种都非常麻烦,在这里给大家介绍一种不需要整机备份和本机root权限,只导出和对象的聊天数据的方法。
那就是使用安卓模拟器导出,这样既能ios/安卓通用,又能够避免对本机造成不良影响,首先需要用电脑版的微信备份你和你对象的聊天记录。以windows系统为例:
1. 下载夜神模拟器
2. 在夜神模拟器中下载微信
3. 使用windows客户端版的微信进行备份,如图左下角
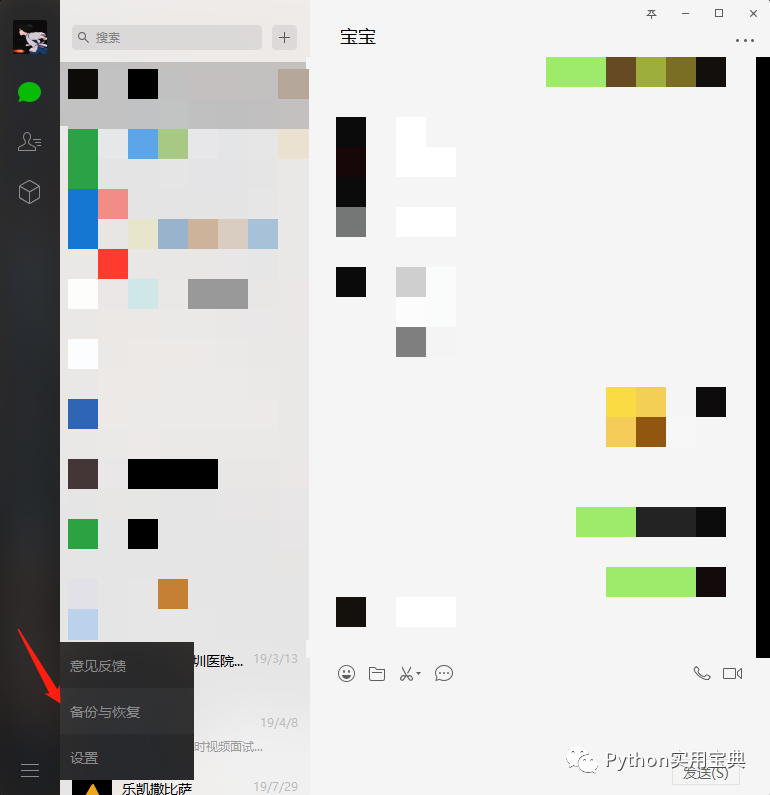
4. 点击备份聊天记录至电脑
5. 手机端选择备份的对象
点击进入下方的选择聊天记录,然后选择和你对象的记录


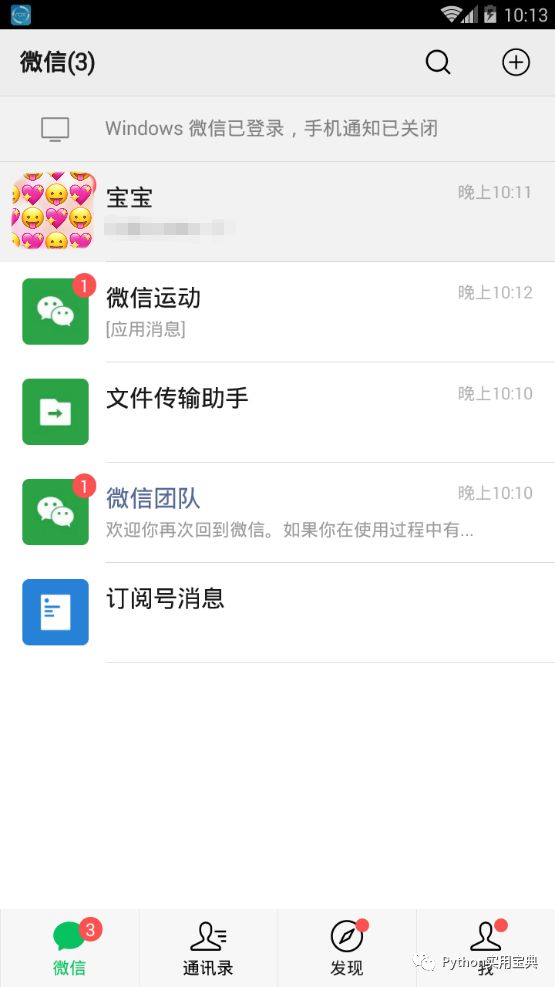
6. 导出完毕后打开模拟器,登录模拟器的微信
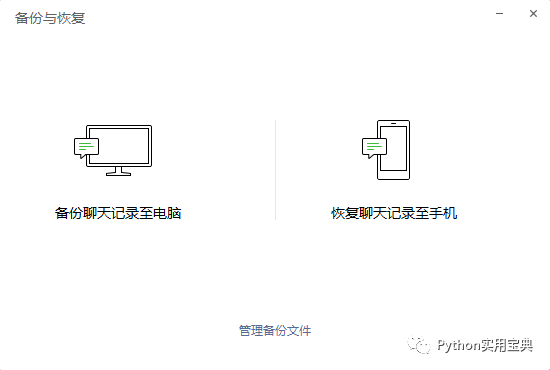
7. 登录成功后返回电脑版微信登录,打开备份与恢复,选择恢复聊天记录到手机
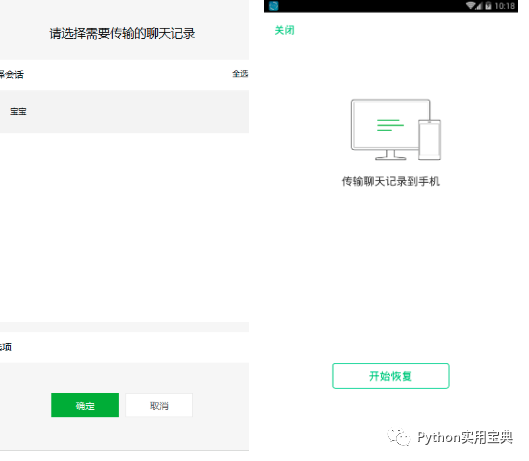
选择恢复记录至手机
8. 勾选我们刚刚导出的聊天记录,并在手机上点击开始恢复
9. 打开夜神模拟器的root权限
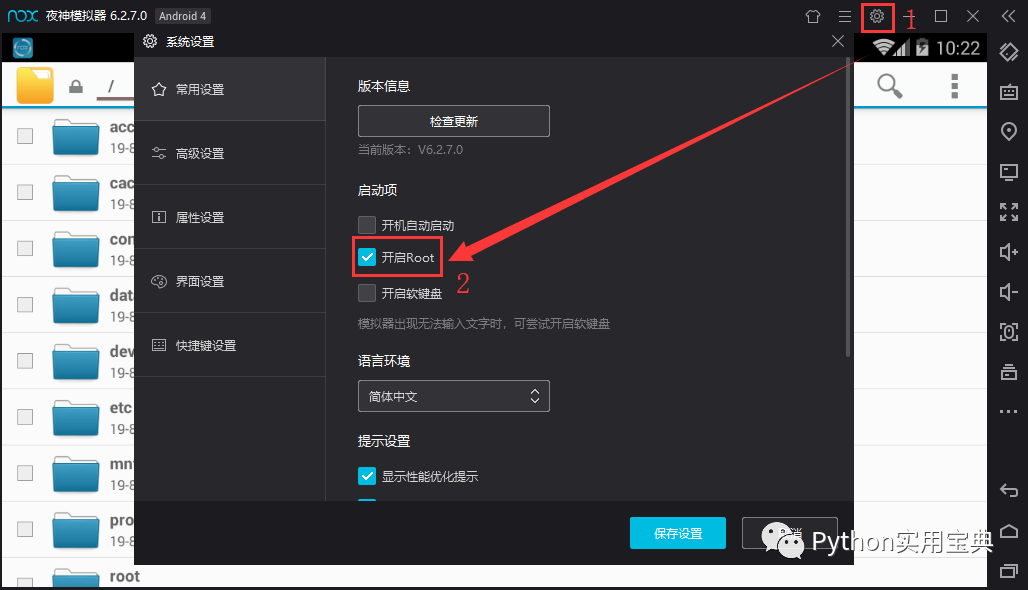
10. 用模拟器的浏览器百度搜索RE文件管理器,下载(图一)安装后打开,会弹出对话框让你给予root权限,选择永久给予,打开RE文件管理器(图二),进入以下文件夹(图三), 这是应用存放数据的地方。
/data/data/com.tencent.mm/MicroMsg
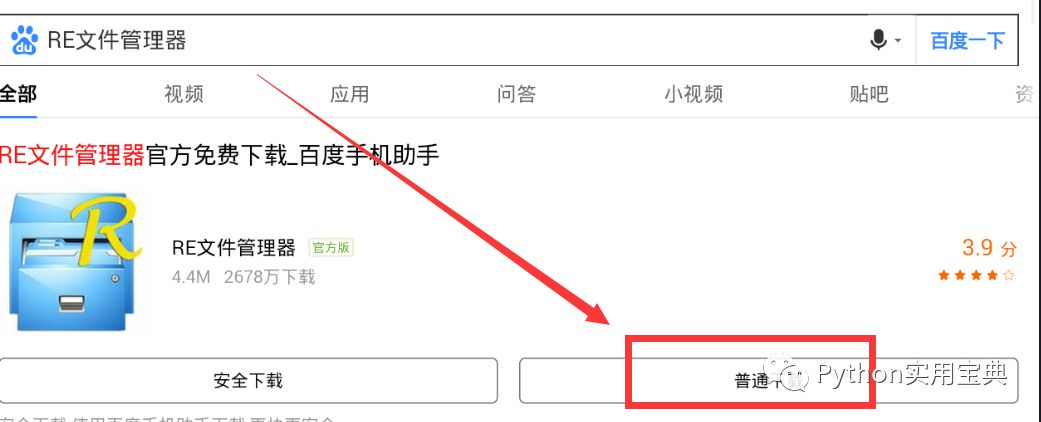
图一
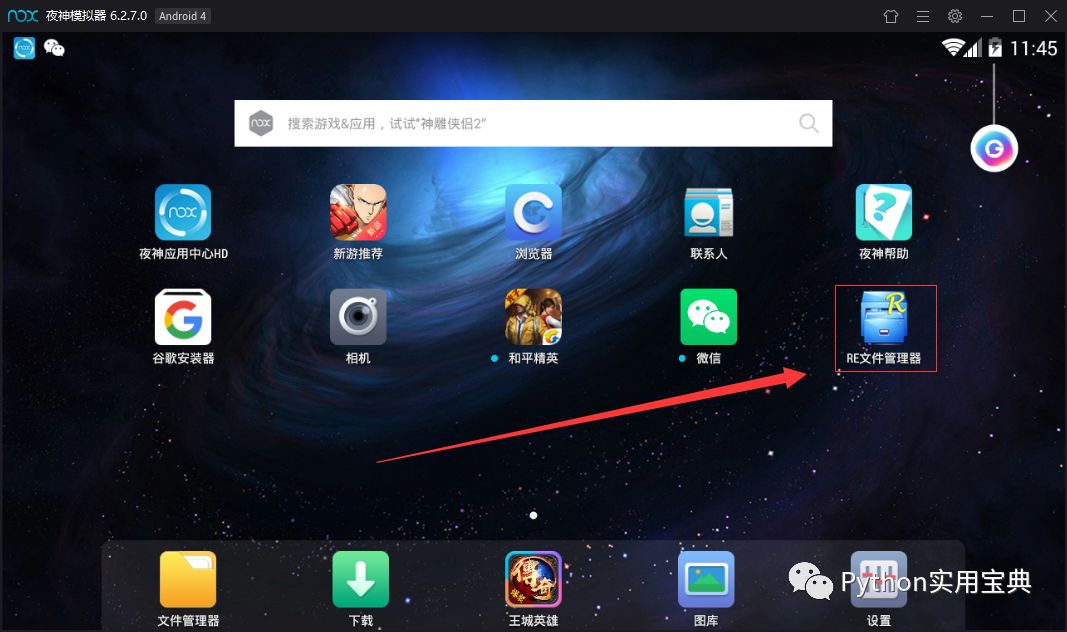
图二
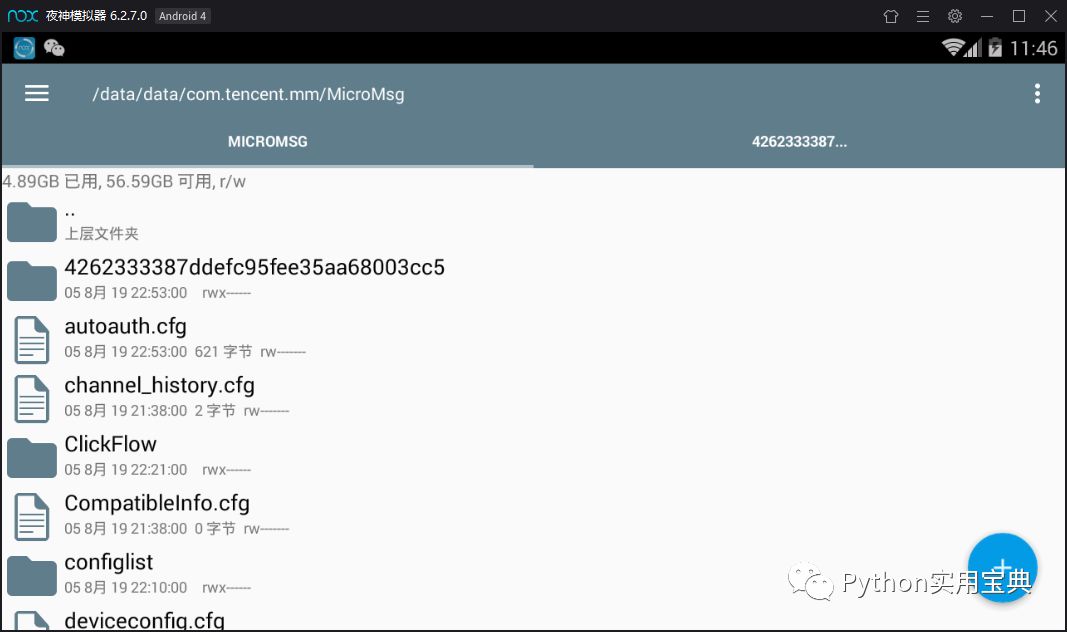
然后进入一个由数字和字母组合而成的文件夹,如上 图三 的
4262333387ddefc95fee35aa68003cc5
11. 找到该文件夹下的EnMicroMsg.db文件,将其复制到夜神模拟器的共享文件夹(图四)。
共享文件夹的位置为 /mnt/shell/emulated/0/others ( 图五 )。
现在访问windows的 C:\Users\你的用户名\Nox_share\OtherShare 获取该数据库文件( EnMicroMsg.db )。
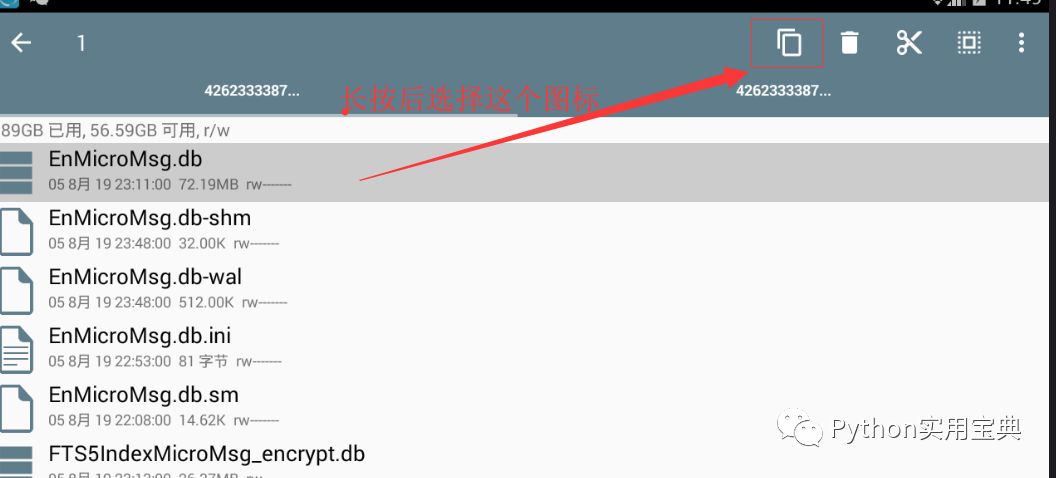
图四
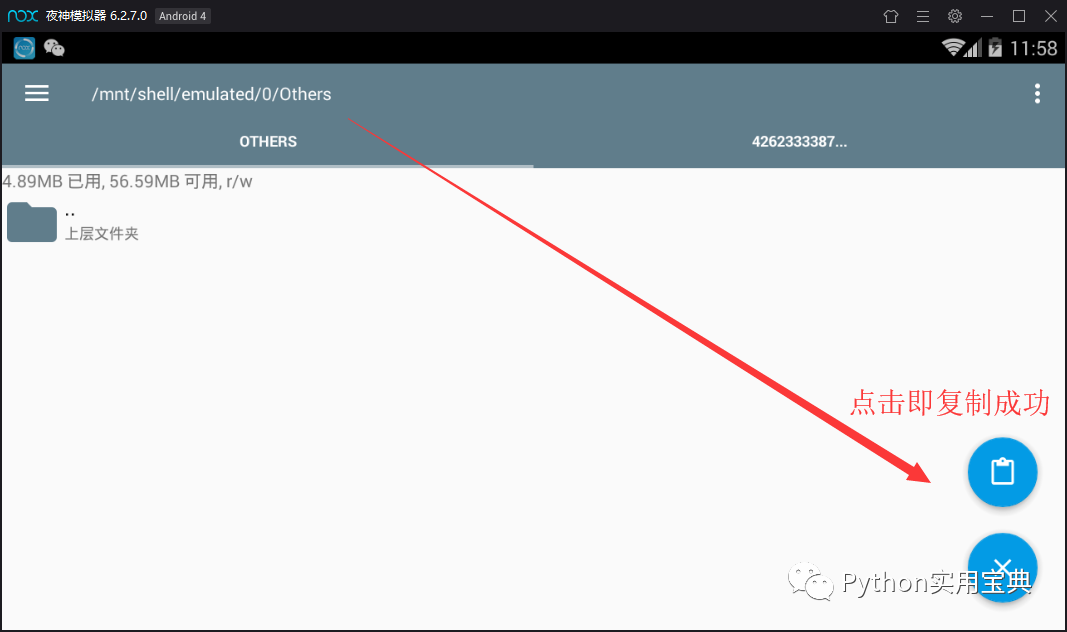
图五
12. 导出该数据库后,使用一款叫 sqlcipher 的软件读取数据
(链接: https://pan.baidu.com/s/1Im3n02yseo-4IxeDY9srqQ 提取码: ka4z)
在这之前,我们还需要知道该数据库的密码,根据前人的经验,该密码的公式如下
字符串 IMEI (手机序列号) UIN(用户信息号)
将该字符串进行MD5计算后的前七位便是该数据库的密码
如 "355757010761231 857456862" 实际上中间没有空格,然后放入MD5计算取前面七位数字,后续会详细介绍
哇,真是“简单易懂”啊,没关系,接下来告诉大家IMEI和UIN怎么获得。
首先是IMEI,在模拟器右上角的系统设置 —— 属性设置里就可以找得到啦,如图所示。
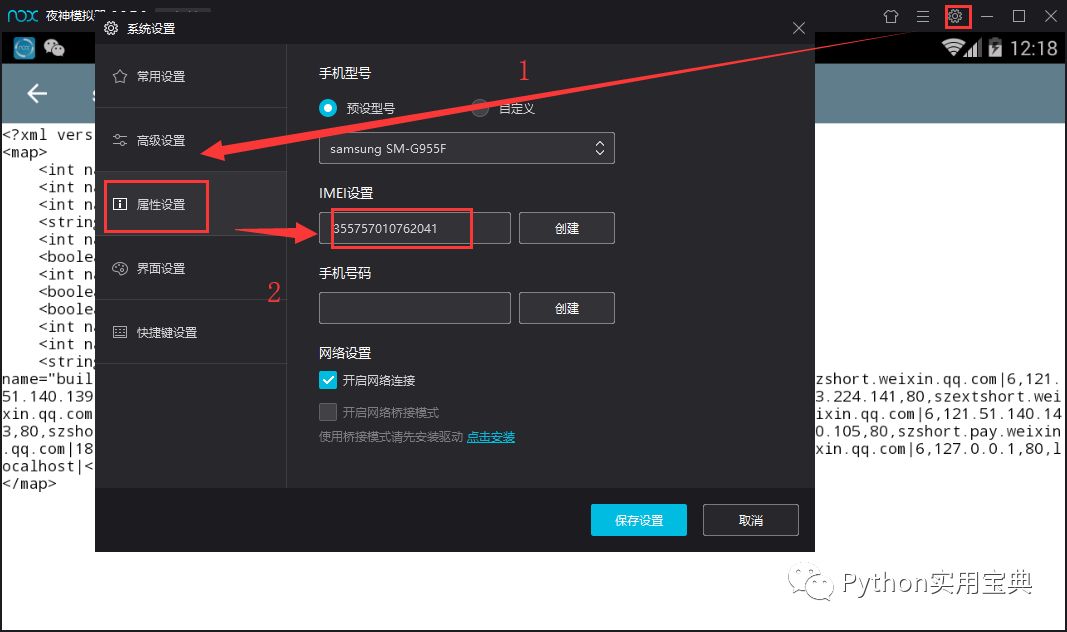
现在我们获得了IMEI号,那UIN号呢?
同样地,用RE文件管理器打开这个文件
/data/data/com.tencent.mm/shared_prefs/system_config_prefs.xml
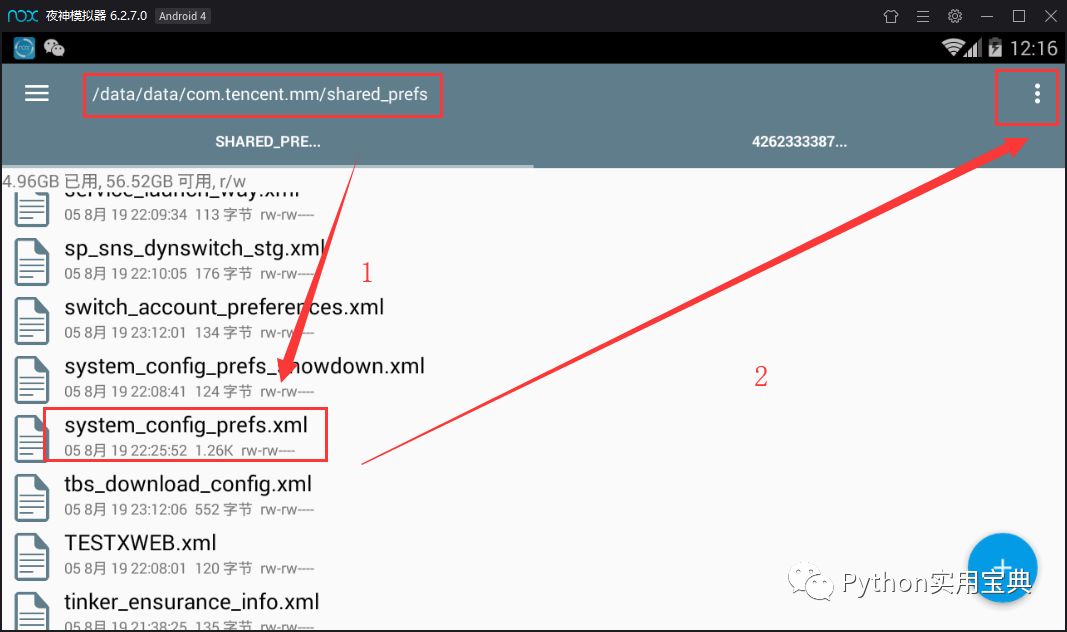
长按改文件,点击右上角的三个点—选择打开方式—文本浏览器,找到default_uin,后面的数字就是了 !
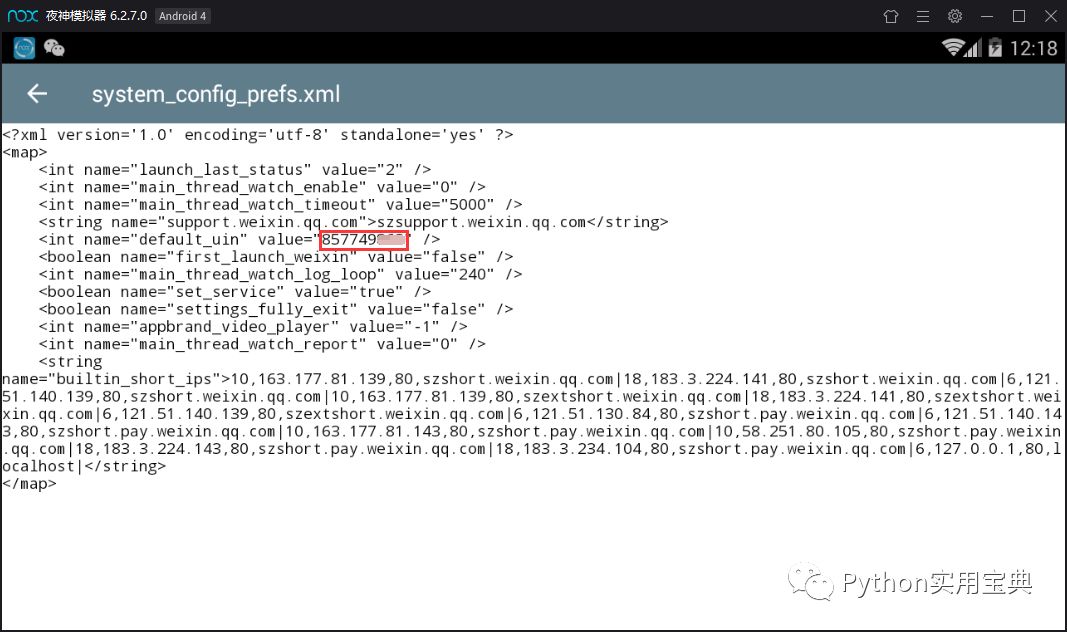
得到这两串数字后,就可以开始计算密码啦,如果我的IMEI是355757010762041,Uin是857749862,那么合起来就是355757010762041857749862,将这串数字放入免费MD5在线计算:
https://md5calculator.chromefans.org/?langid=zh-cn
得到的数字的前七位就是我们的密码了,像这一串就是 6782538.
如果uin是负的话,可以试试uin拼接手机IMEI码(就是和正的相反,进行拼接),取MD5的32位小写密文前7个字符。再不行就重装模拟器。
然后我们就可以进入我们的核心环节:使用 sqlcipher 导出聊天文本数据!
sqlcipher
点击 File - open database - 选择我们刚刚的数据库文件,会弹出框框让你输入密码,我们输入刚刚得到的七位密码,就可以进入到数据库了,选择message表格,这就是你与你的对象的聊天记录!
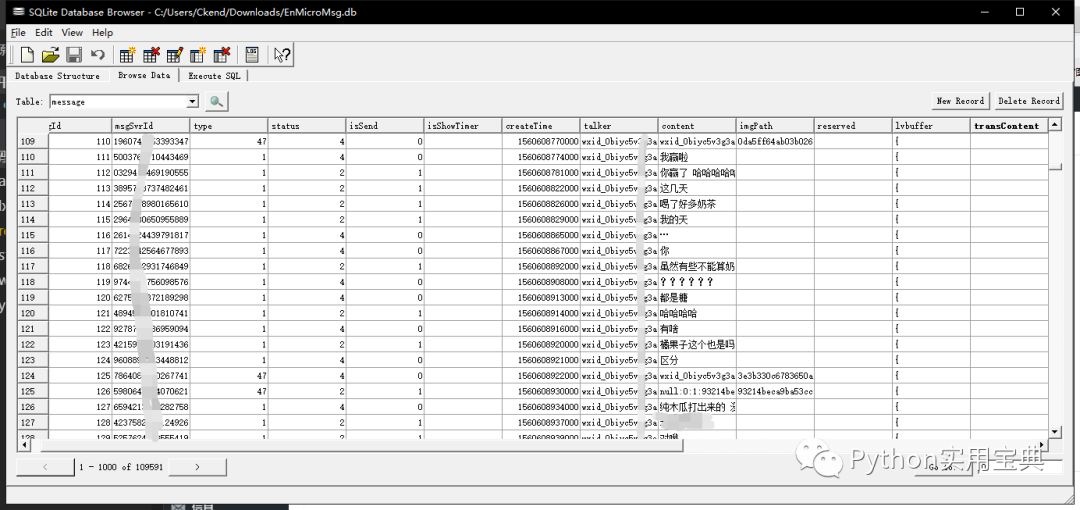
我们可以将它导出成csv文件:File - export - table as csv.
接下来,我们将使用Python代码,将里面真正的聊天内容:content信息提取出来,如下所示。虽然这个软件也允许select,但是它select后不允许导出,非常不好用,因此还不如我们自己写一个:
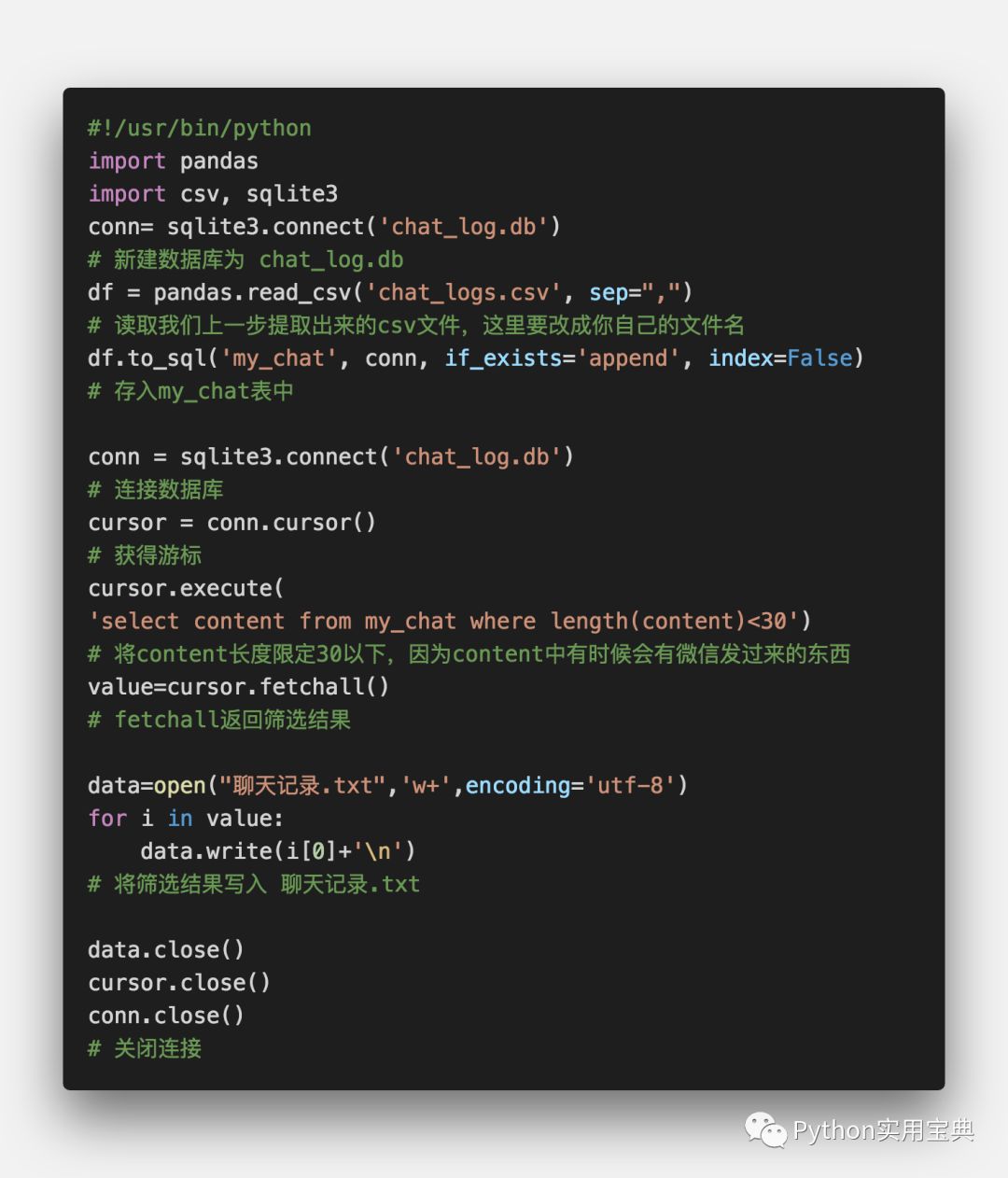
将该文件命名为extract.py,windows打开CMD / macOS系统打开Terminal 进入到该文件夹下,执行命令:
python extract.py记得把生成csv文件的编码格式转换成utf-8哦,不然可能会运行不下去:
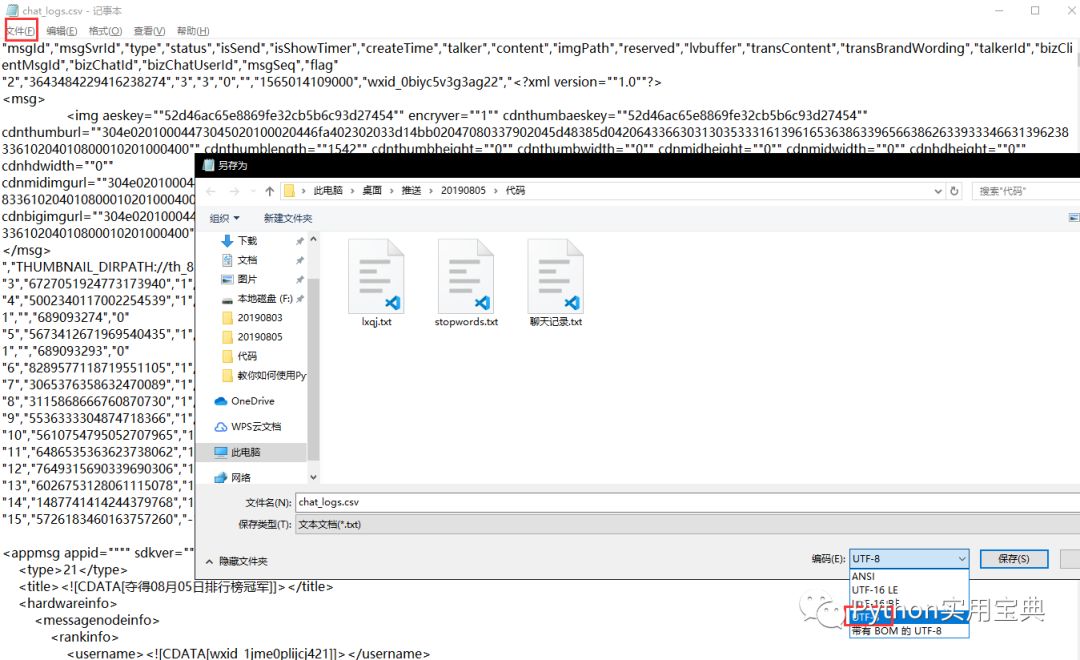
用记事本打开—文件—另存为—编码改为UTF-8即可
当然你还可以用正则表达式去除以下内容
微信发送的数据:wxid.*
表情:\[.*\]
不过我觉得这些也是必要的聊天信息之一,留着也无妨,因此在这里就不加入进去啦,有需要的同学可以百度搜索python 正则表达式,学习正则表达式的使用。
最后得到的文本格式就是一行一句聊天内容,处理后我们就准备好进入下一个环节了!那就是令人激动的!生成词云!!
二、根据第一步得到的聊天数据生成词云
1. 导入我们的聊天记录,并对每一行进行分词
聊天记录是一行一行的句子,我们需要使用分词工具把这一行行句子分解成由词语组成的数组,这时候我们就需要用到结巴分词了。
分词后我们还需要去除词语里一些语气词、标点符号等等(停用词),然后还要自定义一些词典,比如说你们之间恩恩爱爱的话,一般结巴分词是无法识别出来的,需要你自行定义,比如说:小傻瓜别感冒了,一般分词结果是:
小/傻瓜/别/感冒/了
如果你把“小傻瓜”加入到自定义词典里(我们下面的例子里是mywords.txt),则分词结果则会是:
小傻瓜/别/感冒/了
下面对我们的聊天记录进行分词:
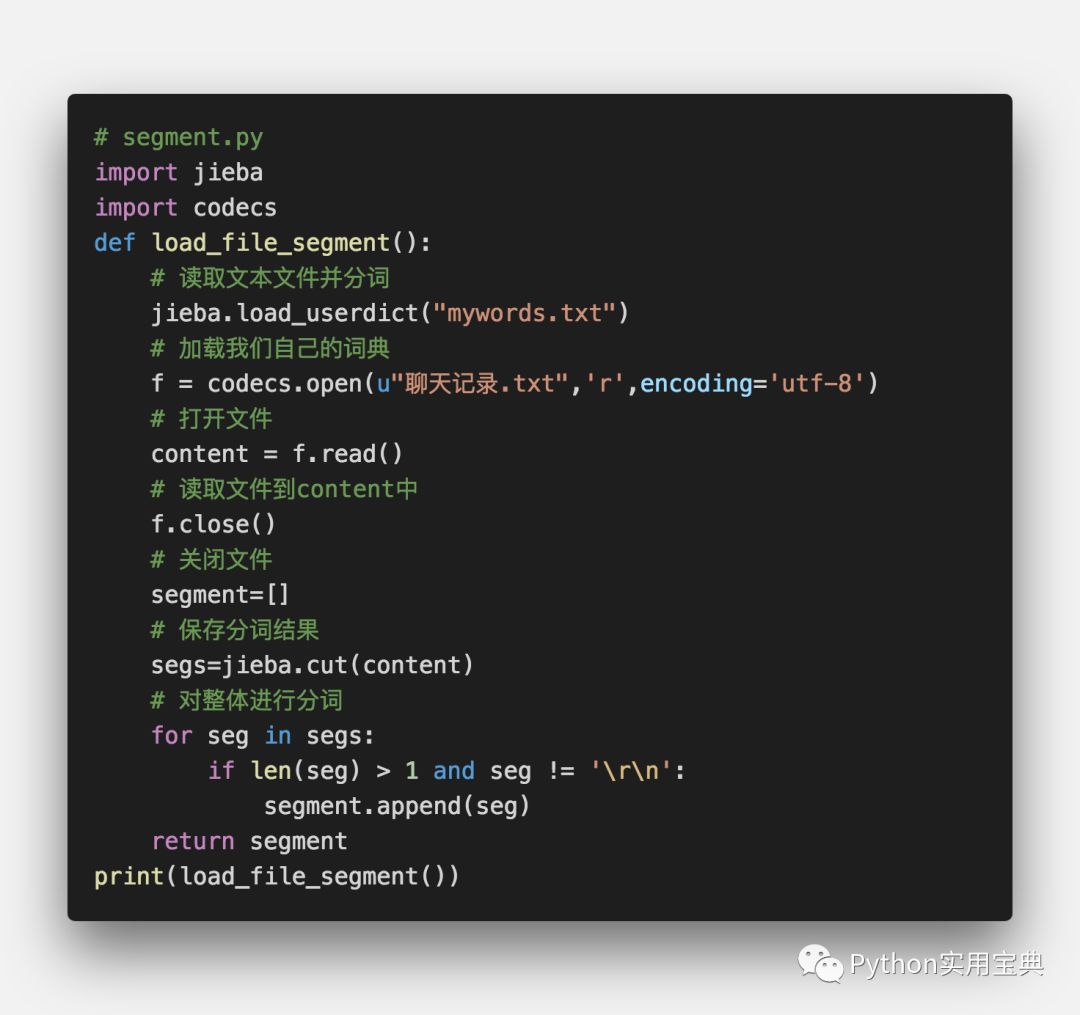
在这个函数里,我们使用了codecs打开我们的聊天记录文件,然后进行结巴分词,最终返回一个包含所有词语的数组。记得运行前要安装jieba分词包,默认你已经安装了python3,如果没有请查阅这个文档:
https://www.liaoxuefeng.com/wiki/1016959663602400/1016959856222624
windows打开CMD / macOS系统打开Terminal 输入:
pip install jieba安装完成后,在编辑器中输入我们刚刚的python代码,我将其命名为segment.py,切记在同个目录下放置 聊天记录.txt 及 自定义词表 mywords.txt, 然后在CMD/Terminal中输入命令运行:
python segment.py你就可以看见你们的聊天记录分词后的效果啦
2. 计算分词后的词语对应的频数
为了方便计算,我们需要引入一个叫pandas的包,然后为了计算每个词的个数,我们还要引入一个叫numpy的包,cmd/terminal中输入以下命令安装pandas和numpy:
pip install pandas==0.25.1
pip install numpy详细的解析我都写在下方的注释里啦,大家可以自行阅读并实践。不过需要注意的是,里面的load_file_segment()是我们第一步里的函数,如果你不知道如何把这两个步骤合在一起,没关系,最后我们会提供一份完整的代码.
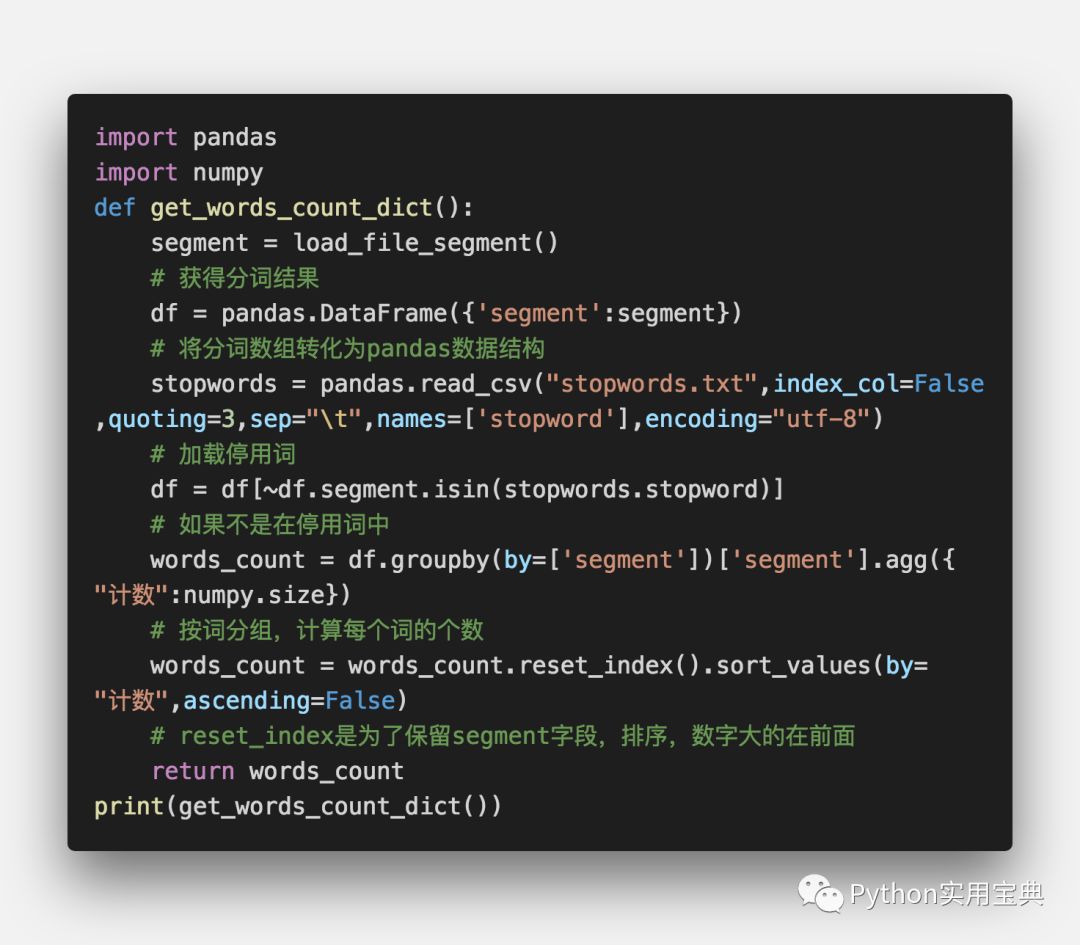
同第一步一样,运行这份代码你就可以看到每个词语及其对应的频数。需要注意的是,这里有个加载停用词的操作,你需要把停用词表放在当前文件夹下,这里提供一份停用词表下载
stopwords.txt: https://pythondict.com/wp-content/uploads/2019/08/2019080607572893.txt
三、生成词云
终于到了最后一部分啦!你是不是开心而又满怀激动的心情呢(滑稽,在这一步开始之前,我们需要先安装需要使用的包,我们需要用到的包有:
pip install matplot
pip install scipy==1.2.1
pip install wordcloud打开CMD/Terminal 输入以上命令即可安装,加上之前两个步骤的包,有:
pip install jieba
pip install codecs
pip install pandas==0.25.1
pip install numpy如果你在安装这些包的时候出现了什么问题,请记得在我们下方评论区提出,我们会一一解答的哦。
运行目录的文件结构如下:
聊天记录.txt
mywords.txt(如果你没有自定义的词的话可以为空)
stopwords.txt
wordCloud.py
semhei.tff
ai.jpg (可以为任意的图片,你喜欢就行)
完整代码,wordCloud.py 如下,附有详细的解析:
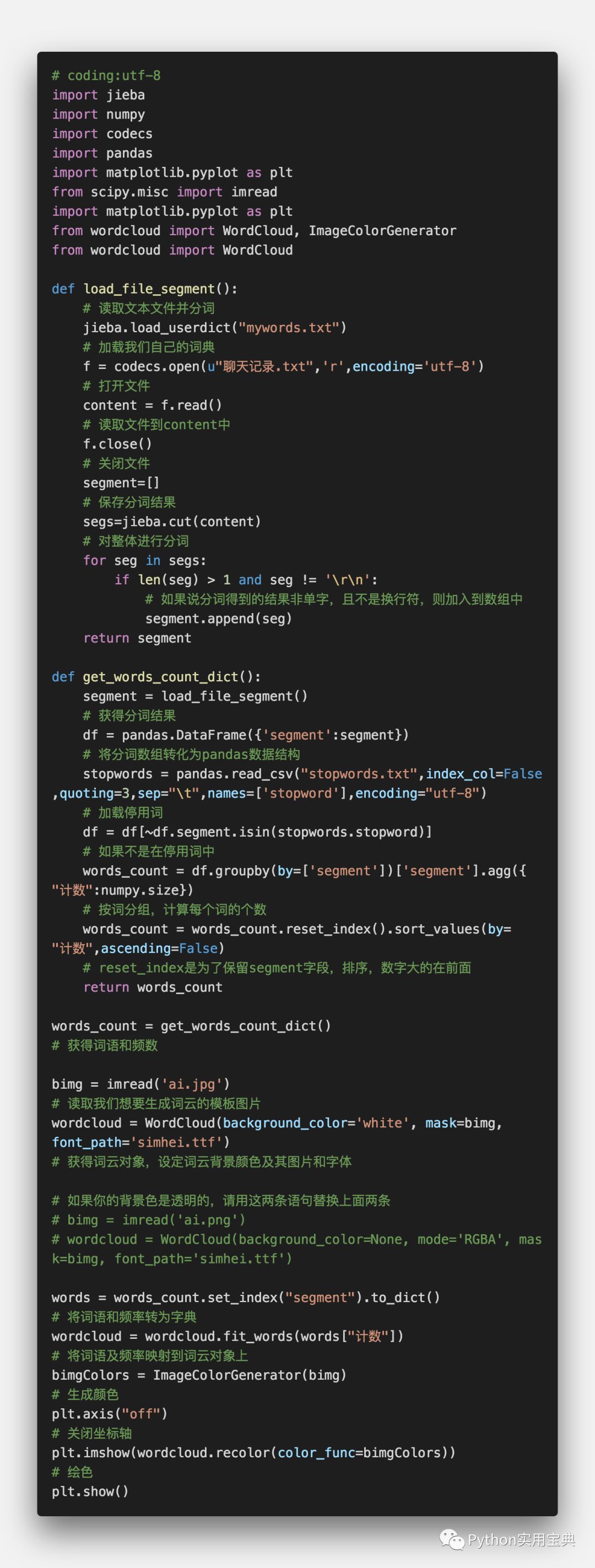
值得注意的是这里面的bimg和wordcloud对象的生成,我们知道png格式背景一般是透明的,因此如果你的图像是png格式的话,其生成词云的时候背景色应该设为None,然后mode应该设为RGBA。
我们还可以控制词云字体的大小和数目的多少,使用下面这两个参数:
max_font_size=60, max_words=3000
调用方式如下所示:
wordcloud = WordCloud(background_color='white', mask=bimg, max_font_size=x, max_words=y, font_path='simhei.ttf')运行前,确保安装了所有的包,并且当前目录下有我们所需要的所有文件哦
下面就可以用我们的聊天记录,画心型词云啦!!!:
CMD/Terminal 进入代码所在文件夹,运行:python wordcloud.py
得到的图像如下:


