
图解图库Janusgraph系列-一文知晓图数据底层存储结构
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
作者丨匠心Java
来源丨匠心Java
一:存储模式
1、图内容
本文以下所有内容基于:JanusGraph基于属性图来进行构造图数据:
属性图: 属性图是由 顶点(Vertex),边(Edge),属性(Property)组成的有向图
Vertex可以包含Properties;Edge也可以包含Properties;
2、存储方法
图存储的方式常用的有两种:邻接列表 和 邻接矩阵
JanusGraph采用邻接列表进行图数据的存储,如下图所示:(此处将图中节点抽象为 只有节点,没有属性)
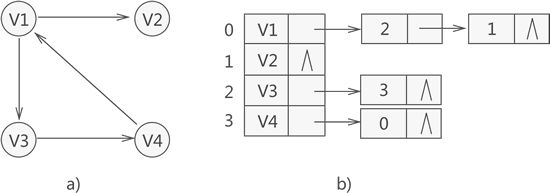
在Janusgraph中一个顶点的邻接列表包含该节点对应的属性和关联的边,下述会详细说明 Janusgraph中邻接列表是如何实现的;
3、图切割方式
图的切割方式分为两种:按节点切割(Vertex Cut)和按边切割(Edge Cut)
Vertex Cut:根据点进行切割,每个边只存储一次,只要是节点对应的边便会多一份该节点的存储
Edge Cut:根据边进行切割,以节点为中心,边会存储两次,源节点的邻接列表存储一次,目标节点的邻接列表存储一次
在Janusgraph中既存在Edge Cut,也存在Vertex Cut的情况;
在默认的情况下使用边切割,而针对热点节点可以通过配置makeVertexLabel('product').partition()来将节点类型为product类型的节点进行Vertex Cut;
也就是说,在没有上述makeVertexLabel('product').partition()配置的话,JanusGraph所有的图数据都是以Edge Cut的方式来进行切割存储的;
具体可以查看文章:《JanusGraph-分区》中自定义分区部分中关于图切割部分的介绍;
我们例子来说明一下:
如下图:张三用户节点通过手机号关联出来李四用户节点
张三 和 李四 代表Vertex;指向的name、age、gender代表张三的属性
edgeA 和edgeB 代表Edge;也可以包含边的属性,例如下图中边包含属性create_time
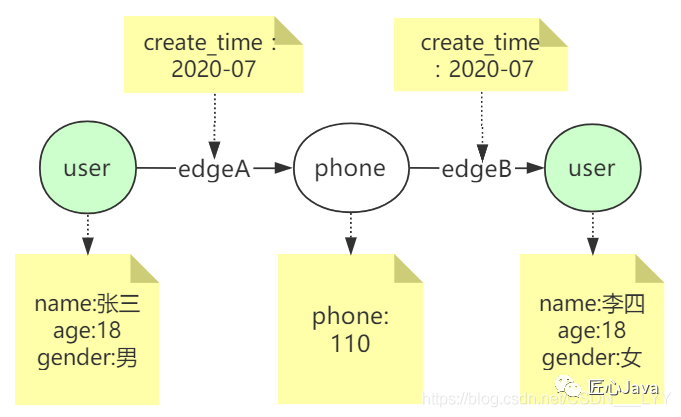
按边切割后:
| 节点 | ||||
|---|---|---|---|---|
| 张三 | name(property) | age(property) | gender(property) | edgeA(edge) |
| phone | phone(property) | edgeA(edge) | edgeB(edge) | |
| 李四 | name(property) | age(property) | gender(property) | edgeB(edge) |
上述可以看到,按照边切割后每一条边会存储两次!
二:BigTable模型
在JanusGraph的存储中, JanusGraph将图形的邻接列表的表示存储在支持Bigtable数据模型的任何存储后端中
BigTable模型如下图:
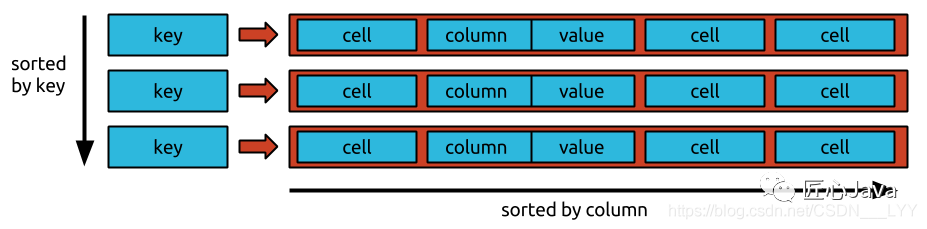
在Bigtable数据模型中,每个表是行的集合,由一个key唯一标识。
每行由任意(可以很大数量但是必须有限数量)数量的cell组成;cell由column和value组成,column唯一标识某一个cell。
上述图中,有两部分需要排序的支持:sorted by key 和 sorted by column:
sorted by key:标识存储后端存储的数据时按照key的大小进行排序存储的
sorted by column:这是JanusGraph对Bigtable数据模型有一个额外要求,存储edge(边)的单元格必须按column排序,并且列范围指定的单元格子集必须是有效可检索的;这句话详细解答在下述文章中有体现
在Bigtable模型中的行称为“宽行”,因为它们支持大量cell,并且不必像关系数据库中那样预先定义这些cell的column。
在关系型数据库中我们必须先定义好表的schema,才可以存储数据,如果存储过程中想要改变表结构,则所有的数据都要对变化的列做出变化。但是Bigtable模型存储中就不必如此,每个行的column不同,我们可以随时仅对某一行进行变化,也不许预先定义行的schema,只需要定义图的schema即可。
此外,特定的Bigtable实现可以使行按其键的顺序排序。JanusGraph可以利用这样的键序来有效地划分图形,从而为非常大的图形提供更好的加载和遍历性能。
JanusGraph是如何基于BigTable数据模型针对于自身的图数据特性进行设计的呢?
下面我们看下JanusGraph的逻辑存储结构
三:存储逻辑结构
JanusGraph基于使用BigTable模型的存储后端 实现了自己的存储的逻辑结构
ps:为了更好的理解,下面部分知识点会基于HBase存储后端进行进一步的解释!
1、整体结构
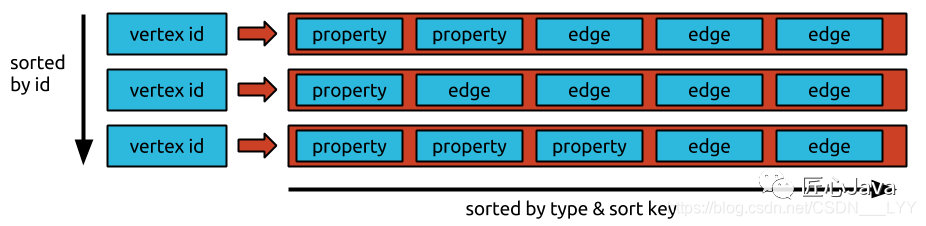
在JanusGraph中,以节点为中心,按切边的方式存储数据的。比如在Hbase中节点的ID作为HBase的Rowkey,节点上的每一个属性和每一条边,作为该Rowkey行的一个个独立的Cell。即每一个属性、每一条边,都是一个个独立的KCV结构(Key-Column-Value)
上图中,我们可以发现图的存储整体分为三部分:vertex id、property、edge:
vertex id: 对应节点的唯一id,如果底层存储使用的是Hbase则代表着当前行的Rowkey,唯一代表某一个节点
property: 代表节点的属性
edge: 代表节点的对应的边
排序方式分为三种:sorted by id、sorted by type、sorted by sort key:
sorted by id: 依据vertex id在存储后端进行顺序存储
sorted by type:此处的个人理解为针对于property 和 edge的类型进行排序,保证同种类型的属性或者边连续存储在一块便于遍历查找; // TODO 深层次理解
sorted by sort key: sort key是边组成以的一部分,主要作用是,在同种类型的edge下,针对于sort key进行排序存储,提升针对于指定sort key的检索速度;下面
edge结构部分有详细介绍
2、Vertex id 的结构
此处的Vertex id唯一标识图中的某一个节点;节点vertex id的组成结构我们在源码类IDManager的一段注释中可以发现:
/* --- JanusGraphElement id bit format ---* [ 0 | count | partition | ID padding (if any) ]*/
这是在Janusgraph在生成所有的id时统一的格式包含vertex id\edge id\property id的时候,这个顺序也 就是标识我们再使用gremlin查询出节点时,节点上标识的vertex id;
这个id值的顺序不同于hbase真实存储Rowkey的顺序!!!!!!!
在对vertex id进行序列化存储时,位置有所调整为:[ partition | 0 | count | ID padding (if any) ] 如下图:

从图中可以看出:
Vertex ID共包含一个字节、8位、64个bit
Vertex ID由partition id、count、ID padding三部分组成
最高位5个bit是partition id。partition是JanusGraph抽象出的一个概念。当Storage Backend是HBase时,JanusGraph会根据partition数量,自动计算并配置各个HBase Region的split key,从而将各个partition均匀映射到HBase的多个Region中。然后通过均匀分配partition id最终实现数据均匀打散到Storage Backend的多台机器中
中间的count部分是流水号,其中最高位比特固定为0;出去最高位默认的0,count的最大值为2的(64-5-1-3)=55次幂大小:3 6028 7970 1896 3968,总共可以生成30000兆个id,完全满足节点的生成
最后几个bit是ID padding, 表示Vertex的类型。具体的位数长度根据不同的Vertex类型而不同。最常用的普通Vertex,其值为'000'
为什么在序列化存储vertex id时,需要调整顺序序列化作为RowKey存储到Hbase呢?
我们通过下面的3个问题来回答:
为什么JausGraph分配的逻辑区间值,可以影响hbase物理存储呢?可以将分区相同的数据存放的更近呢?
在上述描述中,hbase使用vertex id作为rowkey,hbase根据rowkey顺序排序存储;每个
hbase region存储是一段连续的Rowkey行;
在
janusgraph的vertex id的设计中,可以发现将分区值放到了64位的前5位存储! 在存储数据到hbase时,对rowkey进行排序,因为partition id在前5位,所以同一个分区的vertex id对应的rowkey值相差较小,所以会存储在一块;
如何快速的查询到不同类型的节点呢?换个说法如何快速的确定当前的行就是我们需要的节点类型的行呢?
在JanusGraph的vertex id中包含的 ID padding就代表当前的节点类型(注意此处的类型!=lable)。000标识为普通节点,在id的组成部分中,我们经过前面的分析,最前面是partition id,只有把 ID padding放在最后几个字节便于查找了;
为什么查询出的节点显示的vertex id要把0|count放在最前面、partiton和id padding放在后面呢?
这里我们猜测一下:count占用55位数据! 试想如果把count不放在最前面,那么id的最小值比2的55次幂还大,显示不友好!如果把0|count放在最前面呢?就会有两个效果:
0在有符号表示中标识当前id始终为正整数!
count是趋势递增的,所以id值也是从小到大趋势递增的,所以节点id的最小值在2的8次幂周边大小;比把count放在后面显示的id值友好多了~~~
vertex id是如何保证全局唯一性的呢?
主要是基于数据库 + 号段模式进行分布式id的生成;
体现在图中就是partition id + count 来保证分布式全局唯一性; 针对不同的partition都有自己的0-2的55次幂的范围的id;每次要生成vertex id时,首先获取一个partition,获取对应partition对应的一组还未使用的id,用来做count;
janusgraph在底层存储中存储了对应的partition使用了多少id,从而保证了再生成新的分布式vertex id时,不会重复生成!
ps :JanusGraph中分布式唯一vertex id、edge id、property id的生成分析,请看《图解JanusGraph系列-分布式唯一id的生成机制》
3、edge 和 property的结构
在上述的JanusGraph的整体结构中,property和edge都是作为cell存储在底层存储中;其中cell又分为column和value两部分,下图展示了这两部分的逻辑结构:
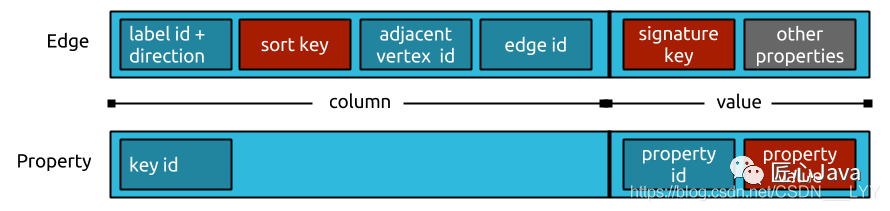
下面我们详细分析一下 property 和 edge对应的逻辑结构;
3.1 edge的结构
Edge的Column组成部分:
label id:边类型代表的id,在创建图schema的时候janusgraph自动生成的label id,不同于边生成的唯一全局id
direction:图的方向,out:0、in:1
sort key:可以指定边的属性为sort key,可多个;在同种类型的edge下,针对于sort key进行排序存储,提升针对于指定sort key的检索速度;
该key中使用的关系类型必须是属性非唯一键或非唯一单向边标签;
存储的为配置属性的value值,可多个(只存property value是因为,已经在schema的配置中保存有当前Sort key对应的属性key了,所以没有必要再存一份)
adjacent vertex id:target节点的节点id,其实存储的是目标节点id和源节点id的差值,这也可以减少存储空间的使用
edge id:边的全局唯一id
Edge的value组成部分:
signature key:边的签名key
该key中使用的关系类型必须是属性非唯一键或非唯一单向边标签;
存储压缩后的配置属性的value值,可多个(只存property value是因为,已经在schema的配置中保存有当前signature key对应的属性key了,所以没有必要再存一份)
主要作用提升edge的属性的检索速度,将常用检索的属性设置为signature key,提升查找速度
other properties:边的其他属性
注意!不包含配置的sort key和signature key属性值,因为他们已经在对应的位置存储过了,不需要多次存储!
此处的属性,要插入属性key label id和属性value来标识是什么属性,属性值是什么;
此处的property的序列化结构不同于下述所说的vertex节点的property结构,edge中other properties这部分存储的属性只包含:proeprty key label id + property value;不包含property全局唯一id!
详细解释及思考:
在进行详细分析前,请大家思考几个问题,如下:
基于上述的edge逻辑结构,JanusGraph是如何构造邻接列表的 或者 是如何获取源节点的邻接节点的?
上述的Edge逻辑结构中的,每部分的排列的顺序的含义是什么?
1、基于上述的edge逻辑结构,JanusGraph是如何构造邻接列表的 或者 是如何获取源节点的邻接节点的?
从上述的整体结构部分中,我们可以知道,vertexId行后跟着当前的节点关联的所有的edge;
而在上述的edge的逻辑结构中,有一个adjacent vertex id字段,通过这个字段就可以获取到target节点的vertex id,就相当于指向了target节点,整理一下:
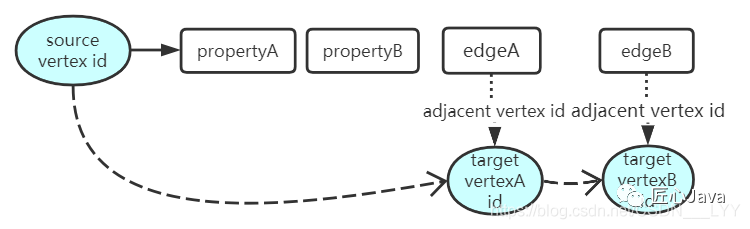
如上图,通过上述的条件,就可以构造一个VertexA指向VertexB 和 VertexC的邻接链表;
其实,JanusGraph可以理解为构造的是双向邻接列表, 依据上图,我们知道vertexA 和 vertexB 和 vertexC存在边关系;当我们构造vertexB的邻接列表时,会包含指向vertexA的节点,只是说在edge对应的逻辑结构中边的方向不同而已:
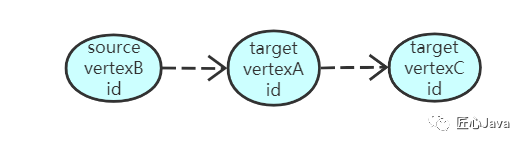
总结:JanusGraph通过vertex id行中包含所有关联的edge,edge逻辑结构中包含指向target节点的数据来组成双向邻接列表的结构;
2、上述的Edge逻辑结构中的,每部分的排列的顺序的含义是什么?
首先,在查询的时候为了提升查询速度,我们首先要过滤的是什么,针对于edge毋庸置疑是边的类型和边的方向;
所以,为了我们可以更快的拿到类型和方向,所以在edge的存储结构中,我们发现作者将类型和方向存放在了column中,并且是column的最前面部分;这样我们可以直接通过判断column的第一部分字节就可以对边类型和方向进行过滤!
ps:虽然我们在写Gremlin语句的时候,可能是语句写的是先过滤边的属性或者其他,但是JanusGraph会针对我们的gremlin语句进行优化为先过滤
边类型和方向
接下来,我们可能对边的属性进行过滤,我们怎样提升经常要过滤的属性的查询速度呢?我们将经常用于范围查询的属性配置为sort key,然后就可以在过滤完边类型和方向后快速的进行属性的范围过滤(此处快速的指过滤配置为sort key的属性);
3.2 property的结构
property的存储结构十分的简单,只包含key id、property id和value三部分:
key id:属性label对应的id,有创建schema时JanusGraph创建;不同于属性的唯一id
property id:属性的唯一id,唯一代表某一个属性
value:属性值
注意:属性的类型包含SINGLE、LIST和SET三种Cardinality;当属性被设置为LIST类型时,因为LIST允许当前的节点存在多个相同的属性kv对,仅通过key id也就是属性的label id是无法将相同的属性label区分出来的
所以在这种情况下,JanusGraph的property的存储结构有所变化, property id也将会被存储在column中,如下图:

四:index存储结构
1、Composite Index结构
图一(唯一索引Composite Index结构图):

图二(非唯一索引Composite Index结构图):

Rowkey由index label id 和properties value两大部分组成:
index label id:标识当前索引类型
properties value:索引中包含属性的所有属性值,可多个;存在压缩存储,如果超过16000个字节,则使用GZIP对property value进行压缩存储!
Column由第一个字节0 和 vertex id组成:
第一个字节0:无论是唯一索引,还是非唯一索引此部分都会存在;如图一
vertex id:非唯一索引才会在column中存在,用于分别多个相同索引值对应的不同节点;如图二
value由vertex id组成:
vertex id:针对于rowkey + column查询到的value是vertex id,然后通过vertex id查询对应的节点
2、Mixed Index结构
这里以ES作为第三方索引库为例,这里只介绍普通的范围查找的mixed index的构造:
ES的概念为:index 包含多个 type;每个type包含多个document id,每个document id包含多个field name 和对应的field value;
在Jausgraph中
index:包含两种,
janusgraph_edge和janusgraph_vertex两种
type:可自定义
document id:edge id或者 vertex id
field name:索引对应属性的label string
field value:属性对应的property value
基于倒排索引的查询顺序为,给定过一个property label 和 property value查询对应的Vertex id 或者 edge id,则查询满足要求的field name 和 field value,就可以获取到对应的document id即Vertex id 或者 edge id;
五:序列化数据案例
以序列化实例来看下上述所说的整体结构
测试节点数据:
{"label":"user","propertyMap":{"create_time":"2016-12-09 02:29:26","user_name":"张三","user_id":"test110"},"vertexId":4152}
测试边数据:
{"edgeId":17514510,"label":"user_login_phone_number","propertyMap":{"productid":"2"},"sourceId":4152,"targetId":40964120}
跟踪Janusgraph源码,获取其序列化信息,后端存储使用Hbase:
节点序列化后数据(不包含索引):
边序列化后数据(不包含索引):
节点的vertex id序列化后的数据为56 0 0 0 0 0 0 -128;一个节点对应的属性和边的Rowkey相同,依据qualifier也就是column来进行区分;
在边的序列化结果中,包含两部分:一部分是节点4152的kcv,一个是节点40964120的kcv;这地方也可以说明JanusGraph是采用的双向邻接链表进行图存储的
五:Schema的使用
从上述来看,我们可以知道,JanusGraph图的schema该怎样定义主要是由edge labels 、property keys 和vertex labels 组成(Each JanusGraph graph has a schema comprised of the edge labels, property keys, and vertex labels used therein)
JanusGraph的schema可以显式或隐式创建,推荐用户采用显式定义的方式。JanusGraph的schema是可以在使用过程中修改的,而且不会导致服务宕机,也不会拖慢查询速度。
比如一个简单的显示定义的销售图的scheme:
<propertyKey value="salesman_id" explain="销售人员id" index="" type="java.lang.String" /><propertyKey value="real_name" explain="姓名" index="" type="java.lang.String" /><propertyKey value="role" explain="角色" type="" /><propertyKey value="city_code" explain="所处城市代码" index="" type="" /><propertyKey value="create_time" explain="创建时间" index="" type="" /><edgeLabel value="saleman_service_for" explain="销售引导"><propertys><property value="create_time"/></propertys></edgeLabel><edgeLabel value="own_salaman_Idcard" explain="销售身份"><propertys><property value="create_time"/></propertys></edgeLabel><index elementType="vertex" indexType="compositeIndex" name="salesman_id_I" ><propertyKeys><propertyKey value="salesman_id" /></propertyKeys></index><vertexLabel value="salesman" explain="销售" ><propertys><property value="salesman_id" /><property value="real_name" /><property value="role" /><property value="city_code" /></propertys><edges><edge value="saleman_service_for" direction="out" /><edge value="own_salaman_Idcard" direction="out" /></edges></vertexLabel>
当然,我们也可以添加一些其他的可以组成schema的元素,上述三个是必须的,另外的比如索引(index)等,主要的结构还是:
JanusGraph Schema
|-----------Vertex Lables
|-----------Property Keys
|-----------Edge Labels
和关系型数据库不同,图数据的schema是定义一张图,而非定义一个vertex的。在Mysql中,我们通常将建立一张表定义为创建一个schema,而在JanusGraph中,一个Graph用于一个schema。
六:源码分析
源码分析已经push到github:https://github.com/YYDreamer/janusgraph
七:总结
JanusGraph采用Edge cut的方式进行图切割,并且按照双向邻接列表的形式进行图存储
JanusGraph每个节点都是对应的kcv结构;vertex id唯一标识节点;对应的行cell存储节点属性和对应的边
节点id的分布式唯一性采用数据库+号段模式进行生成;
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【
面试题】即可获取