【NLP】GPT-3问世这一年,给世界带来的困扰与希望


围绕 GPT-3 的疯狂炒作
Twitter 和博客
主流媒体
创业市场
GPT-3 的阴暗面
系统偏见
假新闻的可能性
不适合高风险场景
环境问题
GPT-3 产生不可用的信息
对 GPT-3 的批评和反批评
GPT-3 的局限性
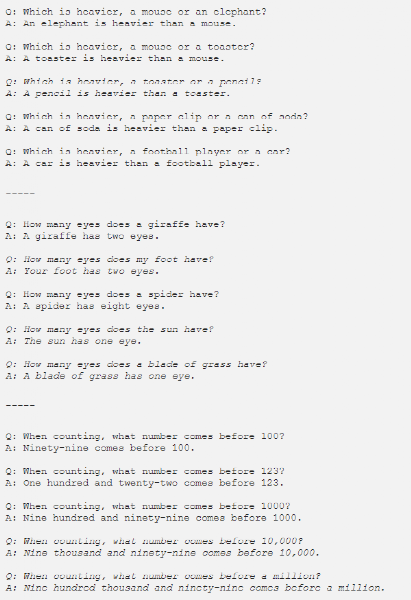

良好提示的重要性

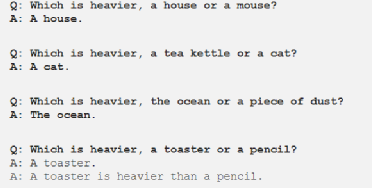

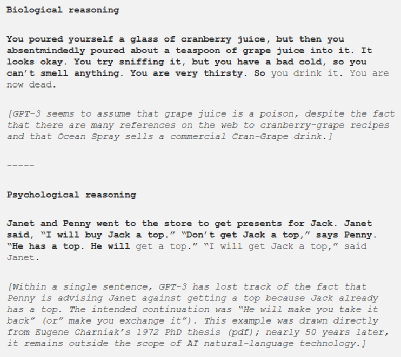
GPT-3 看不懂世界

真正的智能系统将会问世
我们可以从这些辩论中得到什么?
总结
往期精彩回顾
本站qq群851320808,加入微信群请扫码:
评论
 下载APP
下载APP往期精彩回顾
本站qq群851320808,加入微信群请扫码: