
Elasticsearch架构选型指南——不止是搜索引擎,还有......
最近被咨询到“ETC 卡口数据的存储以及车流量分析、车路线分析业务场景是否适合 Elasticsearch 去做”的问题。
这个问题涉及 Elasticsearch 架构选型的问题,而追根究底是:Elasticsearch 适合的业务场景的问题。
记得我在做内部技术分享的时候,讲解 Elasticsearch 应用场景,就铺了3 页 PPT:搜索服务场景、日志实时分析场景、商业智能 BI 场景。我拿着初稿找同事讨论,我心想:“没毛病啊?!Elastic 官方、阿里云、腾讯云、金山云、京东云、百度云等介绍 Elasticsearch 都是这么说的。”
同事一句话点醒了我:“是不是应该加上 Elasticsearch 不适合做什么?”,“我大呼:搜戴斯乃(原来如此)”。
1、Elasticsearch 不适合做什么?
1.1 不支持事务
不支持:ACID(在写入或更新数据的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability))。
如果要有强一致场景,如:银行业务,还得采购 Oracle 等大型商业数据库。
据我不完整了解:银行使用 Elasticsearch 一般和系统日志统一规范、存储和检索、自动化运维相关,而非存储核心金融交易数据。
1.2 多表关联有限
因为习惯了:Mysql 多表通过外键关联检索,不免会将 Mysql 思维平移到 Elasticsearch。
常见的实战多表关联问题如下:“
一般大in的场景有好的解决方案么?
比如:连锁 一个人管理了1000家门店 要去查自己管辖的商品。 比如:企微 一个人维护了 1000个员工 要去查自己管辖的员工。”
Elasticsearch 多表关联的解决方案一般概括如下:
宽表:适合增加冗余存储、空间换时间场景。 nested 类型:适合子文档偶尔更新、查询频繁场景。 Join 父子文档类型:适合子文档频繁更新频繁场景。
正如官方文档所说:
“In particular, joins should be avoided. nested can make queries several times slower and parent-child relations can make queries hundreds of times slower. ”
官方在数据建模部分强调:“应该避免关联。嵌套可以使查询速度慢几倍,父子关系可以使查询速度慢数百倍。因此,若能使用宽表,可以明显加速。”
1.3 不支持准实时
refresh_interval 刷新频率决定近实时而非准实时。
腾讯云黄华老师的分享《腾讯Elasticsearch海量规模背后的内核优化剖析》中强调:
“ES 是一个实时的分布式搜索分析引擎,目前很多用户对 ES 的印象还是准实时,实际上在6.8版本之后官方文档已经将 near real-time 改为了 real-time”。
我们直接看一下6.8版本——7.6版本官方文档的说法,的确如黄老师所说:
"Elasticsearch provides real-time search and analytics for all types of data."
ES 在写入完毕刷新之前,是可以通过 getById 的方式实时获取文档的,只是在刷新之前 FST 还没有构建,还不能提供搜索的能力。
但是,7.7版本——7.13版本(截止:2021-06-17最新版本)又改成:“Elasticsearch provides near real-time search and analytics for all types of data. ”
再一次改回原来的说法,说明:官方文档严谨性拿捏的很到位!
近实时而非准实时说法没毛病。
7.13 版本官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/elasticsearch-intro.html#elasticsearch-intro
1.4 高阶功能收费
比如:机器学习、Kerberos 安全认证、JDBC 客户端、ODBC客户端、Graph 探索、威胁猎捕等高阶功能。
这是主流开源上市公司的收费模式,MongoDB、Confluent、Elastic 皆是如此。
开源版、基础版、黄金版、白金版、企业版的区别和差异,查看地址(要做到必知必会):
https://www.elastic.co/cn/subscriptions
2、Elasticsearch 认知升级
2.1 Elasticsearch 早已不仅是搜索引擎了
以 Elasticsearch 起家,发展到:集成 Elasticsearch、Logstash、Beats、Kibana 四位一体的“全家桶”。
Elasticsearch:搜索和分析引擎。 Logstash:数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。 Beats:一系列轻量型的单一功能数据采集器(包含:Metricbeat、Filebeat等100多种)。 Kibana :使用图形和图表对Elasticsearch数据进行可视化和探索分析。
2.2 Elasticsearch 早已不单单局限搜索场景
Elasticsearch 发展战略也在随势而变。
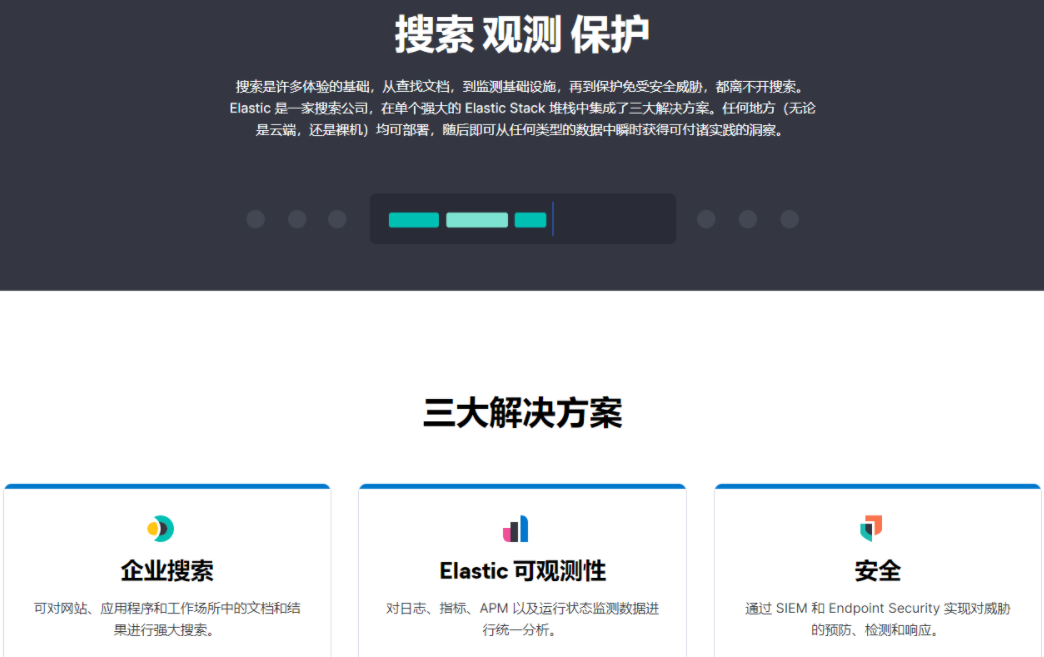
“3 + 1战略”——是指在Elastic Stack 基础上在Elastic 企业搜索、Elastic 全观察、Elastic 安全三个核心业务场景发力。
Elastic 已经由原来的 Elasticsearch 检索工具转变为 Elastic Stack 解决方案提供商。
https://www.elastic.co/cn/products/
3、Elasticsearch 业务场景
还是建议过一下官方文档关于 “ What is Elasticsearch ? ”的介绍。
需要强调的点如下:
slogon 加了分析:由原来的“You know, for search” 改成 “You know, for search (and analysis)”。
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。
Elasticsearch 为所有类型的数据提供高效存储和索引、近乎实时的搜索和分析。
所有都指哪些?主要指:结构化文本、非结构化文本、数值数据、地理空间数据等。
Elasticsearch 的分布式特性、横向扩展能力可以应对数据、查询量的增长。
Elasticsearch 提供了在各种用例中处理数据的速度和灵活性,尽管并非所有问题都是搜索问题。
官方明确点出的几种场景总结如下:
(1)支持各类应用、网站等的全文搜索。
(2)存储和分析日志、指标和安全事件数据。
(3)使用机器学习实时自动建模数据的行为。
(4)使用 Elasticsearch 作为存储引擎自动化业务工作流。
(5)使用 Elasticsearch 作为地理信息系统 (GIS) 管理、集成和分析空间信息。
我也不免俗,将开头提及的:搜索服务场景、日志实时分析 场景、商业智能 BI 场景以截图的形式提供给大家,更直观一些。
以下三页 PPT 截图是基于腾讯云的分享结合了:官方文档、各大云厂商介绍结合我的理解进行了整合梳理。
3.1 场景1:搜索服务
3.1.1 典型场景
仪表盘搜索 电子商务 手机应用搜索 地理位置搜索
3.1.2 主要特性
高性能:高并发、低延迟的搜索体验 强相关:自定义打分、排序机制 高可用:机房、机架感知,异地容灾
3.1.3 相关公司
腾讯健康码、腾讯文档全文检索、携程、拼多多、蘑菇街、滴滴、今日头条、贝壳找房…….

3.2 场景2:日志实时分析
3.2.1 典型场景
业务日志:用户行为日志、应用日志 状态日志:慢查询、异常探测 系统日志:debug、info、warn、error、fatal
3.2.2 主要特性
实时性:从日志产生到可访问,秒级 全文搜索:基于倒排索引,支持灵活的搜索分析 交互式分析:万亿级日志,搜索秒级响应
3.2.3 相关公司
日志易等

3.3 场景3:商业智能BI
3.3.1 典型场景
电子商务、移动应用、广告媒体等业务都需要借助数据分析和数据挖掘来辅助商业决策,而规模庞大的业务数据对数据的统计分析造成了很大的挑战。
3.3.2 主要特性
ES 拥有结构化查询的能力,支持复杂的过滤和聚合统计功能。 帮助客户对海量数据进行高效地个性化统计分析、发现问题与机会、辅助商业决策,让数据产生真正的价值。
3.3.3 相关公司
睿思BI 等。

4、小结
我的座右铭之一:“自由不是你想干什么就干什么,而是你不想干什么就有能力不干什么!”。可见:不想干什么较想干什么更为牛逼。
而选型 Elasticsearch 的时候也要注意:它不能干什么或者它不擅长需要优先考虑,而将它擅长的、能干什么的方面发挥到极致是我们架构选型及后续实战方面要多考虑的因素。
你在架构选型方面还考虑哪些因素?欢迎留言交流分享实战心得。
推荐:
中国最大的 Elastic 非官方公众号
点击查看“阅读原文”,和全球近 1100 位+ Elastic 爱好者(含中国 50%+ Elastic 认证工工程师)每日精进 ELK 技能!