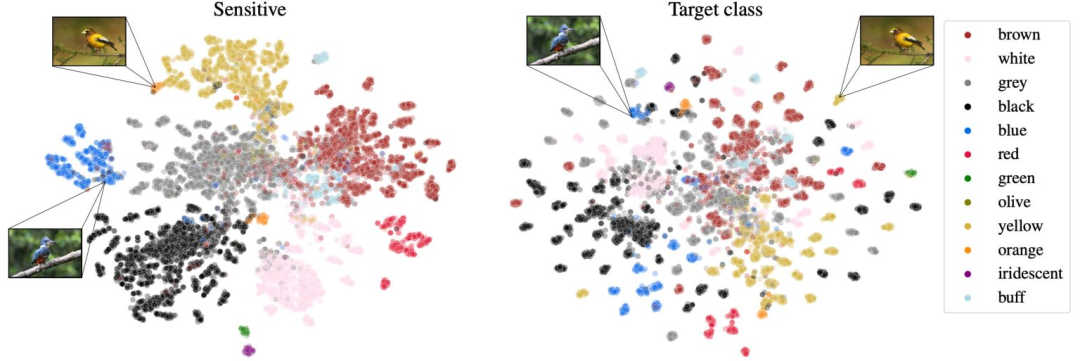
将公平注入AI:机器学习模型即使在不公平数据上训练也能产生公平输出数据派THU关注共 2160字,需浏览 5分钟 ·2022-03-19 00:13 来源:ScienceAI本文约1800字,建议阅读9分钟如何迫使深度度量学习模型首先学习好的特征?如果使用不平衡的数据集训练机器学习模型,比如一个包含远多于肤色较浅的人的图像的数据集,则当模型部署在现实世界中时,该模型的预测存在严重风险。但这只是问题的一部分。麻省理工学院的研究人员发现,在图像识别任务中流行的机器学习模型在对不平衡数据进行训练时实际上会编码偏差。即使使用最先进的公平性提升技术,甚至在使用平衡数据集重新训练模型时,模型中的这种偏差也无法在以后修复。因此,研究人员想出了一种技术,将公平性直接引入模型的内部表示本身。这使模型即使在不公平数据上进行训练也能产生公平的输出,这一点尤其重要,因为很少有平衡良好的数据集用于机器学习。他们开发的解决方案不仅可以使模型做出更平衡的预测,还可以提高它们在面部识别和动物物种分类等下游任务中的表现。「在机器学习中,将数据归咎于模型偏差是很常见的。但我们并不总是有平衡的数据。因此,我们需要找到真正解决数据不平衡问题的方法,」主要作者、麻省理工学院计算机科学与人工智能实验室 (CSAIL) 健康 ML 小组的研究生 Natalie Dullerud 说。定义公平研究人员研究的机器学习技术被称为深度度量学习(deep metric learning),它是表示学习的一种广泛形式。在深度度量学习中,神经网络通过将相似的照片映射在一起并且将不同的照片映射得很远来学习对象之间的相似性。在训练期间,该神经网络将图像映射到「嵌入空间」中,其中照片之间的相似性度量对应于它们之间的距离。例如,如果使用深度度量学习模型对鸟类进行分类,它会将金雀的照片一起映射到嵌入空间的一部分中,并将红雀的照片映射到嵌入空间的另一部分中。一旦经过训练,该模型就可以有效地测量它以前从未见过的新图像的相似性。它会学习将看不见的鸟类的图像聚集在一起,但在嵌入空间内离红雀或金雀更远。这张图片显示了鸟类颜色的两个不同的 PARADE 嵌入Dullerud 说,模型学习的相似性度量非常稳健,这就是为什么深度度量学习经常被用于面部识别的原因。但她和她的同事想知道如何确定相似性指标是否有偏差。「我们知道数据反映了社会进程的偏见。这意味着我们必须将重点转移到设计更适合现实的方法上。」Ghassemi 说。研究人员定义了相似性度量不公平的两种方式。以面部识别为例,如果与那些图像是肤色较浅的人相比,如果将肤色较深的人更靠近彼此嵌入,即使他们不是同一个人,该指标将是不公平的。其次,如果它学到的用于衡量相似性的特征对于多数群体来说比少数群体更好,那将是不公平的。研究人员对具有不公平相似性指标的模型进行了许多实验,但无法克服模型在其嵌入空间中学到的偏差。「这很可怕,因为公司发布这些嵌入模型,然后人们对它们进行微调以完成一些下游分类任务是一种非常普遍的做法。但无论你在下游做什么,你根本无法解决嵌入空间中引发的公平问题,」Dullerud 说。她说,即使用户在下游任务的平衡数据集上重新训练模型(这是解决公平问题的最佳情况),仍然存在至少 20% 的性能差距。解决这个问题的唯一方法是确保嵌入空间一开始是公平的。学习单独的指标研究人员的解决方案称为部分属性去相关 (PARADE),涉及训练模型以学习敏感属性(如肤色)的单独相似性度量,然后将肤色相似性度量与目标相似性度量去相关。如果模型正在学习不同人脸的相似度度量,它将学习使用肤色以外的特征来映射靠近在一起的相似面孔和相距很远的不同面孔。任何数量的敏感属性都可以通过这种方式与目标相似度度量去相关。并且由于敏感属性的相似性度量是在单独的嵌入空间中学习的,所以在训练后将其丢弃,因此模型中仅保留了目标相似性度量。他们的方法适用于许多情况,因为用户可以控制相似性度量之间的去相关量。例如,如果模型将通过乳房 X 光照片诊断乳腺癌,临床医生可能希望在最终嵌入空间中保留一些有关生物性别的信息,因为女性患乳腺癌的可能性比男性高得多,Dullerud 解释说。他们在面部识别和鸟类分类这两项任务上测试了他们的方法,发现无论他们使用什么数据集,它都能减少嵌入空间和下游任务中由偏差引起的性能差距。展望未来,Dullerud 感兴趣的是如何迫使深度度量学习模型首先学习好的特征。「您如何正确审核公平性?这是一个悬而未决的问题。你怎么知道一个模型是公平的,或者它只在某些情况下是公平的,那些情况是什么?这些是我真正感兴趣的问题,」她说。参考内容:https://scitechdaily.com/injecting-fairness-into-ai-machine-learning-models-that-produce-fair-outputs-even-when-trained-on-unfair-data/https://openreview.net/pdf?id=js62_xuLDDv编辑:黄继彦校对:林亦霖 浏览 45点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 SHAP解释机器学习模型输出SHAP(SHapley Additive exPlanations)以一种统一的方法来解释任何机器SHAP解释机器学习模型输出SHAP(SHapleyAdditiveexPlanations)以一种统一的方法来解释任何机器学习模型的输出。SHAP将博弈论与局部解释联系起来,将以前的几种方法结合起来,并根据预期表示唯一可能的一机器学习模型训练全流程!Datawhale0关于公平小楼杂谈0手绘 机器学习模型 训练全流程!裸睡的猪0【文章】机器学习模型训练全流程!算法进阶0【干货】机器学习模型训练全流程!AI算法与图像处理0这不是在要求公平,这是在抢劫架构师之路0【机器学习】在机器学习中处理大量数据!机器学习初学者0【机器学习基础】机器学习模型什么时候需要做数据标准化?机器学习初学者0点赞 评论 收藏 分享 手机扫一扫分享分享 举报



 下载APP
下载APP