
拿走不谢!Kafka官方文档中文版+Kafka面试题详解!(可复制)
你了解kafka吗?目前它在一线互联网公司以迅雷不及掩耳之势得到了广泛的应用。但究竟是什么呢?Kafka最初于2011年在LinkedIn开发,自那时起经历了很多改进。如今它是一个完整的平台,允许您冗余地存储荒谬的数据量,拥有一个具有巨大吞吐量(数百万/秒)的消息总线,并对同时通过它的数据使用实时流处理。
今天分享的这份资料,包括121页的Kafka官方中文文档和Kafka常见面试题,由于内容过多,在此只以截图展示部分内容,详细完整版的文档领取方式请见文末。

这份文档的价值
这份Kafka官方中文文档既适合小白入门也适合有一定基础的同学进阶提升。这份文档共分为9大部分:Kafka基础入门,APIS,Kafka配置,Kafka设计思想及实现,操作,安全,Kafka 连接器及Kafka streams。几乎涵盖了Kafka所有的知识点,一份文档在手,轻松学会Kafka!
第一部分:Kafka基础入门
这一部分是学习Kafka的准备阶段,Kafka的发展,使用案例,下载及历史版本,都在这一部分进行了详细的描述。

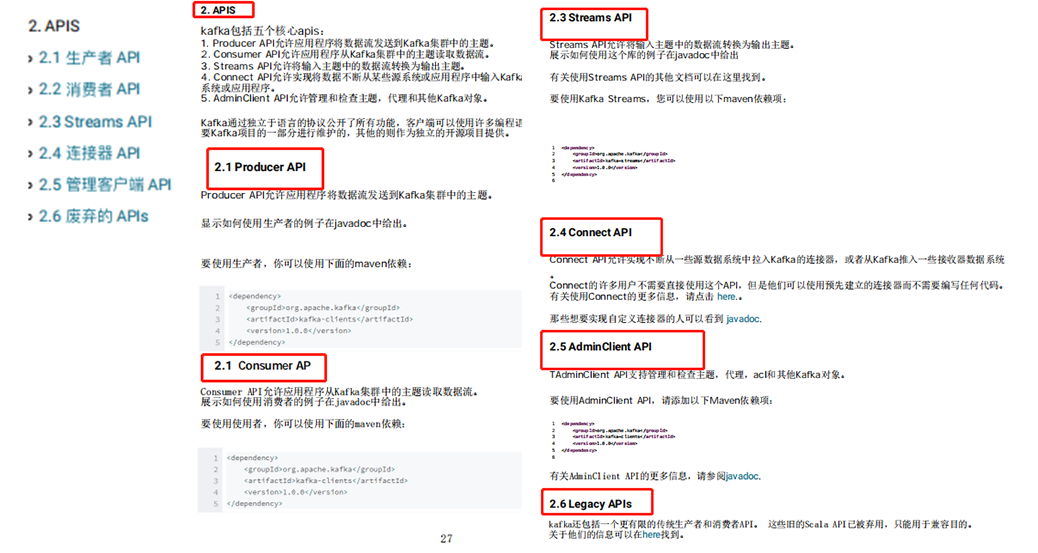
第二部分:APIS
kafka包括五个核心APIS,在这一部分中分别对其进行了详解。
1. Producer API允许应用程序将数据流发送到Kafka集群中的主题。
2. Consumer API允许应用程序从Kafka集群中的主题读取数据流。
3. Streams API允许将输入主题中的数据流转换为输出主题。
4. Connect API允许实现将数据不断从某些源系统或应用程序中输入Kafka的连接器,或从Kafka输入某些接收器系统或应用程序。
5. AdminClient API允许管理和检查主题,代理和其他Kafka对象。
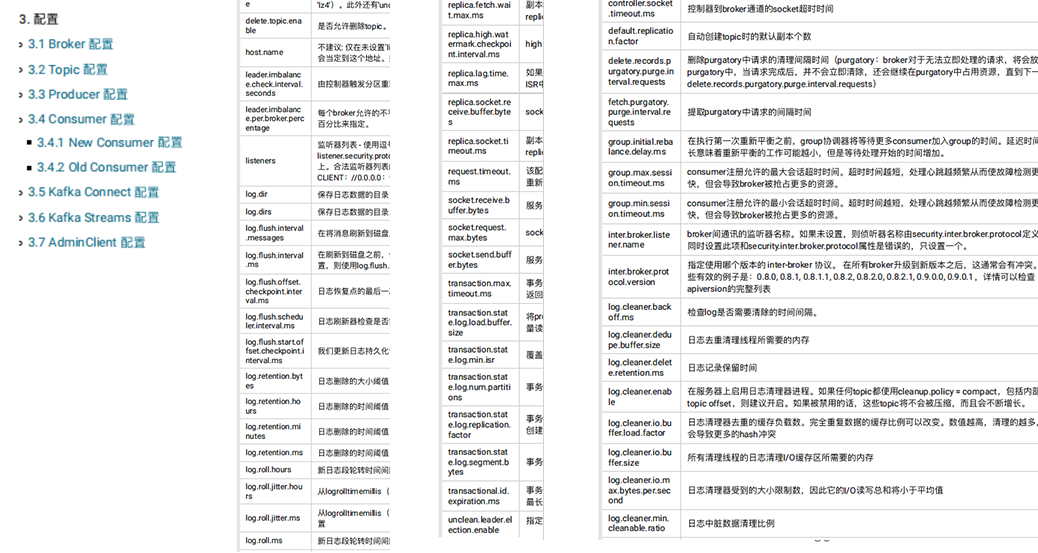
第三部分:配置
第四部分:设计思想
这一部分介绍了Kafka的设计思想以及一些重要概念解析:生产者,备份,消息分发策略,日志压缩······

第五部分:实现思路
第五部分承接第四部分的内容,对Kafka的实现思路进行了详尽介绍。

第六部分:Kafka操作
接下来就进入了实操阶段,基本原理,基础概念了解清楚之后正式开始上手,这一部分的内容会比较多,是基于LinkedIn使用Kafka作为生产系统的一些使用经验。基础配置,硬件操作系统及监控,zookeeper等内容都需要在本章掌握。

第七部分:Kafka安全
Kafka具有特性,通过单独使用或者⼀起使用这些特性,提高了Kafka集群的安全性。

第八部分:Kafka连接器
这一部分主要介绍了:Kafka Connect ——⼀款可扩展并且可靠地在 Apache Kafka 和其他系统之间进行数据传输的工具。
Kafka Connect 可以摄取数据库数据或者收集应用程序的 metrics 存储到 Kafka topics,使得数据可以用于低延迟的流处理。一个导出的 job 可以将来自 Kafkatopic 的数据传输到二级存储,用于系统查询或者批量进行离线分析。

第九部分:Kafka Streams
Kafka Streams 是一个用于处理和分析存储在 Kafka 系统中的数据的客户端库。它建立在重要的流处理概念上,如恰当地区分事件时间(event time)和处理时间(processing time),支持窗口操作(window),exactly-once 处理语义以及简单高效的应用程序状态管理。Kafka Streams 的入门门槛很低。我们可以在单节点环境上快速实现一个小规模的验证性的程序,只要程序能在多节点的集群环境成功运行即可部署到高负载的生产环境。Kafka Streams 通过利用Kafka 的并行模型实现对相同应用程序的多个实例的负载平衡,这对于用户来说是透明的。

此外,还为大家准备了一份Kafka面试题(基础+进阶+高级),共44个知识点!

如果有需要完整版的朋友可以识别下方二维码,回复关键词“Kafka”即可全部打包带走!
注意拼写正确!直接复制关键词领取更方便
(识别后绝对100%发放)
资料来源自网络,侵删歉!https://kafka.apachecn.org/