
PyTorch1.12发布,又一个新增库:TorchArrow,对标Pandas!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期,PyTorch团队发布了PyTorch1.12新版本,PyTorch1.12版本首次支持CUDA11.6版本,具体安装指令如下: PyTorch1.12的主要更新内容总结如下:
PyTorch1.12的主要更新内容总结如下:
TorchArrow库
这是新发布的一个基于torch.Tensor的数据预处理库,对标的是流行的Pandas库。其中Columns和Pandas中的Series类一样,用来创建一个一维的序列: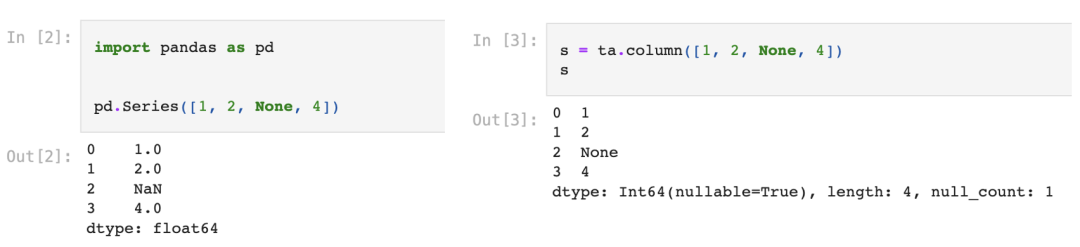 而Dataframes也对比Pandas中的DataFrames,用来创建二维的数据,即一系列等长的Columns:
而Dataframes也对比Pandas中的DataFrames,用来创建二维的数据,即一系列等长的Columns: 更多的内容可以见教程:https://github.com/pytorch/torcharrow/blob/main/tutorial/tutorial.ipynb
更多的内容可以见教程:https://github.com/pytorch/torcharrow/blob/main/tutorial/tutorial.ipynb
Module的Functional API
这个feature(目前是beta阶段)可以让我们基于函数式的方式来执行PyTorch的Module计算,它的灵活之处是我们可以自定义外部的参数来替换Module中本身的参数来执行计算,这个在元学习中比较实用。具体示例如下所示:
import torch
from torch import nn
from torch.nn.utils.stateless import functional_call
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 3)
self.bn = nn.BatchNorm1d(3)
self.fc2 = nn.Linear(3, 3)
def forward(self, x):
return self.fc2(self.bn(self.fc1(x)))
m = MyModule()
# Define parameter / buffer values to use during module computation.
my_weight = torch.randn(3, 3, requires_grad=True)
my_bias = torch.tensor([1., 2., 3.], requires_grad=True)
params_and_buffers = {
'fc1.weight': my_weight,
'fc1.bias': my_bias,
# Custom buffer values can be used too.
'bn.running_mean': torch.randn(3),
}
# Apply module computation to the input with the specified parameters / buffers.
inp = torch.randn(5, 3)
output = functional_call(m, params_and_buffers, inp)
支持Complex32和Complex Convolution
目前,PyTorch 原生支持复数、复数、复数、复数模块和许多复杂运算,包括线性代数和快速傅里叶变换 (FFT) 算子。许多库,包括 torchaudio 和 ESPNet,已经在 PyTorch 中使用了复数,并且 PyTorch 1.12 进一步扩展了复杂的功能,包括复杂的卷积和实验性的 complex32(“复半数”)数据类型,可以实现半精度 FFT 运算。由于 CUDA 11.3 包中的错误,如果您使用复数,我们建议使用车轮中的 CUDA 11.6 包。
Forward-mode Automatic Differentiation
前向模式 AD 允许在前向计算中直接计算方向导数(或等效地,雅可比向量积)。PyTorch 1.12 显着提高了前向模式 AD 的opertiaon覆盖率。有关更多信息,请参阅教程:https://pytorch.org/tutorials/intermediate/forward_ad_usage.html#forward-mode-automatic-differentiation-beta。我们在深度学习中常采用reverse-mode AD来计算梯度,即我们常说的BP算法。
TorchData优化
TorchData 的DataPipe完全向后兼容现有的DataLoader,涉及多处理和分布式环境中的shuffle和动态分片。DataLoader2也进入prototype阶段,它预备是为适配DataPipe。
性能提升:nvFuser
nvFuser是用于PyTorch的深度学习编译器。在 PyTorch 1.12 中,Torchscript 将其默认 fuser(用于 Volta 和更高版本的 CUDA 加速器)更新为 nvFuser,它支持更广泛的操作,并且比以前用于 CUDA 设备的 fuser 更快。即将发布的一篇博文将详细介绍 nvFuser,并展示它如何加速各种网络的训练。
TorchVision升级到V0.13
全面升级到Multi-weight support API,支持多个权重:
from torchvision.models import *
# Old weights with accuracy 76.130%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# New weights with accuracy 80.858%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# Best available weights (currently alias for IMAGENET1K_V2)
# Note that these weights may change across versions
resnet50(weights=ResNet50_Weights.DEFAULT)
# Strings are also supported
resnet50(weights="IMAGENET1K_V2")
# No weights - random initialization
resnet50(weights=None)
模型新增Swin Transformer和EfficienetNetV2:
import torch
from torchvision.models import *
image = torch.rand(1, 3, 224, 224)
model = swin_t(weights="DEFAULT").eval()
prediction = model(image)
image = torch.rand(1, 3, 384, 384)
model = efficientnet_v2_s(weights="DEFAULT").eval()
prediction = model(image)
物体检测模型RetinaNet,Faster RCNN和Mask RCNN进行优化,性能大幅度提升:
更多内容见:https://pytorch.org/blog/pytorch-1.12-new-library-releases/,https://pytorch.org/blog/pytorch-1.12-new-library-releases/
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
