
我通宵翻译Pandas官方文档,写了这一份Excel万字肝货操作!
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是黄同学
本文翻译自Pandas官方文档! 文末有惊喜,看到最后你不亏!
阅读须知
import pandas as pd
import numpy as np
数据结构
1. 通用术语翻译
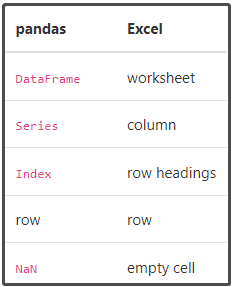
2. DataFrame
3. Series
4. Index
A1:Z1,而在 Pandas 中,您可以使用population.loc['Chicago']。5. 副本与就地操作
sorted_df = df.sort_values("col1")
df = df.sort_values("col1")
df.sort_values("col1", inplace=True)
数据输入和输出
1. 利用值构造一个数据框DataFrame
df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]})
df

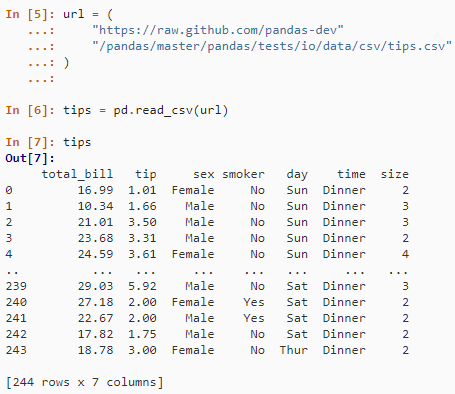
2. 读取外部数据
CSV
url = ("https://raw.github.com/pandas-dev/pandas/master/pandas/tests/io/data/csv/tips.csv")
tips = pd.read_csv(url)
tips
tips = pd.read_csv("tips.csv", sep="\t", header=None)
# 或者,read_table 是带有制表符分隔符的 read_csv 的别名
tips = pd.read_table("tips.csv", header=None)
Excel文件
tips.to_excel("./tips.xlsx")
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
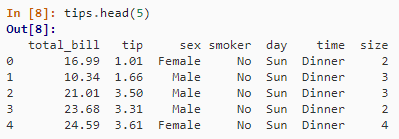
3. 限制输出
tips.head(5)
4. 导出数据
数据操作
1. 列操作
tips["total_bill"] = tips["total_bill"] - 2
tips["new_bill"] = tips["total_bill"] / 2
tips

2. 过滤
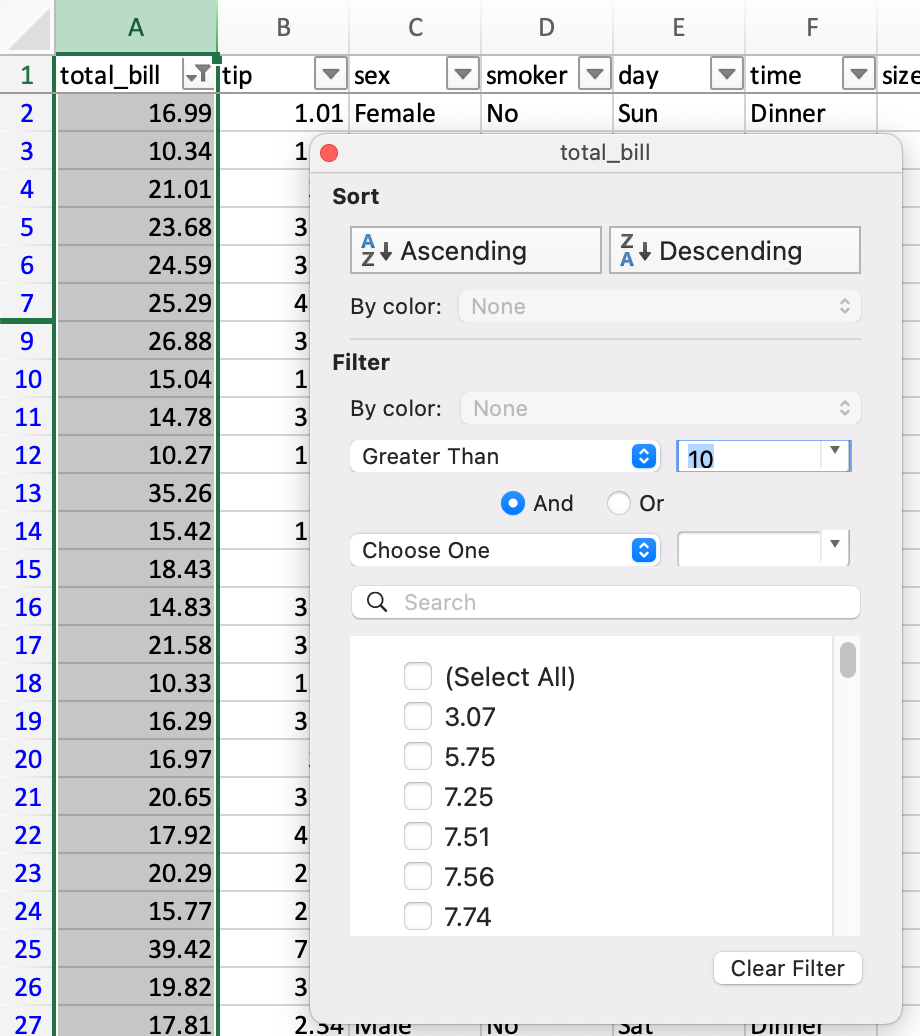
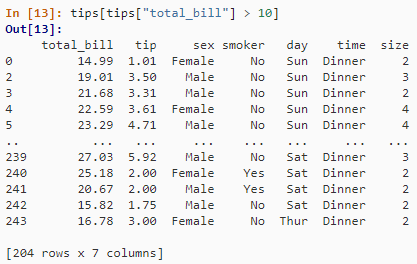
tips[tips["total_bill"] > 10]
is_dinner = tips["time"] == "Dinner"
is_dinner.value_counts()
tips[is_dinner]

3. If/then逻辑
=IF(A2 < 10, "low", "high")的公式,将其拖到新存储列中的所有单元格。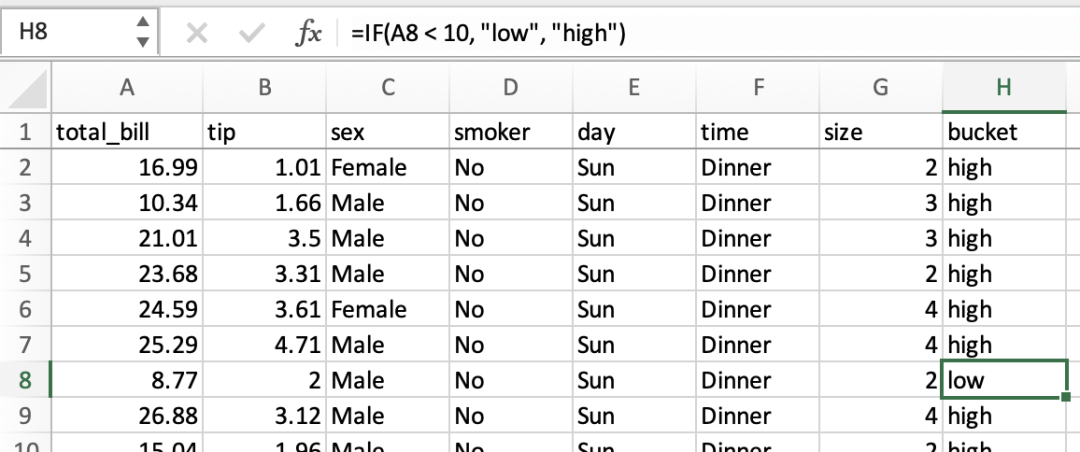
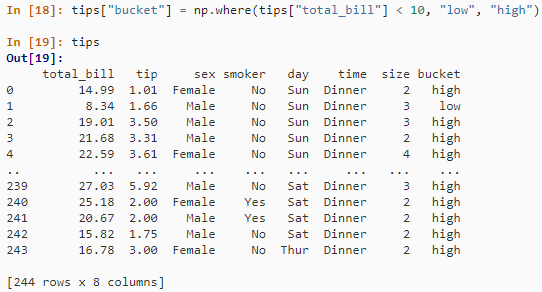
tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high")
tips
4. 日期功能
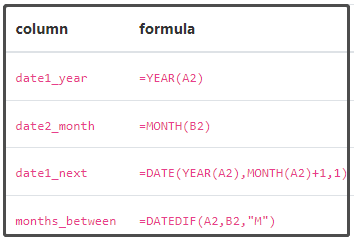
tips["date1"] = pd.Timestamp("2013-01-15")
tips["date2"] = pd.Timestamp("2015-02-15")
tips["date1_year"] = tips["date1"].dt.year
tips["date2_month"] = tips["date2"].dt.month
tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin()
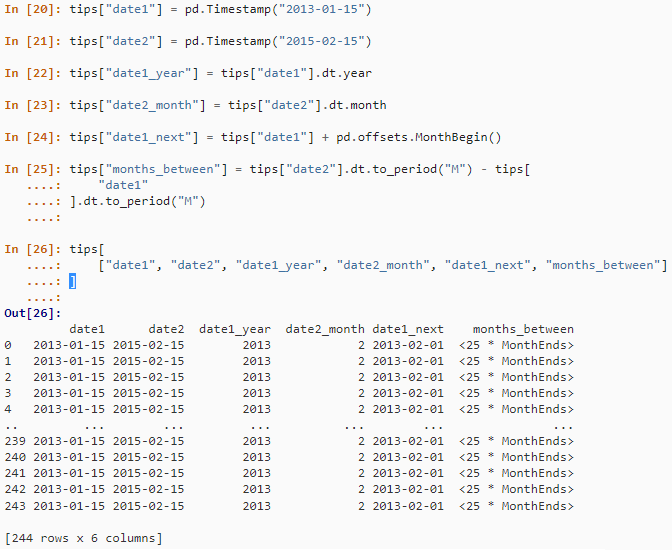
tips["months_between"] = tips["date2"].dt.to_period("M") - tips["date1"].dt.to_period("M")
tips[["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"]]
5. 列的选择
隐藏列; 删除列; 引用从一个工作表到另一个工作表的范围;
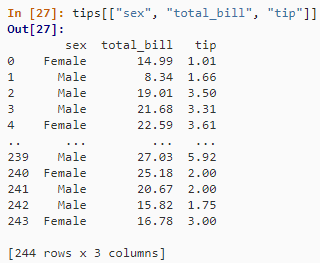
保留某些列
tips[["sex", "total_bill", "tip"]]
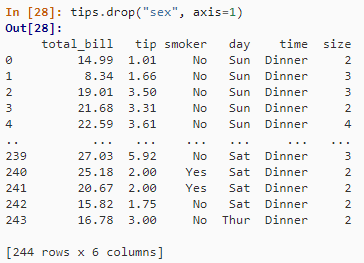
删除某些列
tips.drop("sex", axis=1)
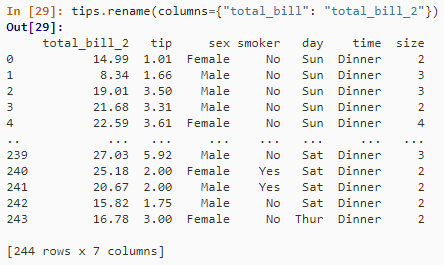
重命名列
tips.rename(columns={"total_bill": "total_bill_2"})
6. 按值排序
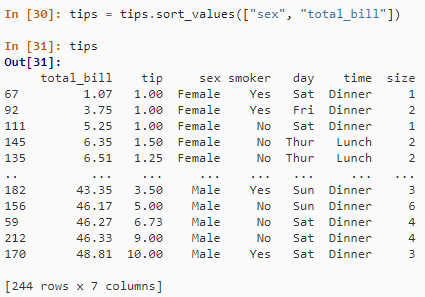
tips = tips.sort_values(["sex", "total_bill"])
tips
字符串处理
1. 查找字符串长度
=LEN(TRIM(A2))
tips["time"].str.len()
tips["time"].str.rstrip().str.len()

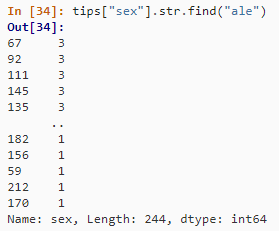
2. 查找子串的位置
tips["sex"].str.find("ale")
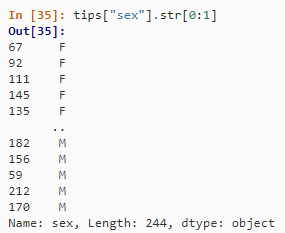
3. 按位置提取子串
=MID(A2,1,1)
tips["sex"].str[0:1]
4. 提取第n个单词
firstlast = pd.DataFrame({"String": ["John Smith", "Jane Cook"]})
firstlast["First_Name"] = firstlast["String"].str.split(" ", expand=True)[0]
firstlast["Last_Name"] = firstlast["String"].str.rsplit(" ", expand=True)[0]
firstlast

5. 大小写转换
firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]})
firstlast["upper"] = firstlast["string"].str.upper()
firstlast["lower"] = firstlast["string"].str.lower()
firstlast["title"] = firstlast["string"].str.title()
firstlast

合并
df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)})
df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)})

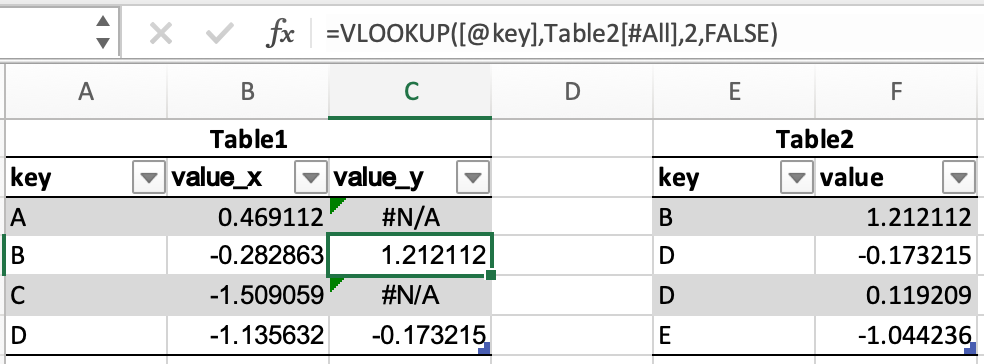
inner_join = df1.merge(df2, on=["key"], how="inner")
left_join = df1.merge(df2, on=["key"], how="left")
right_join = df1.merge(df2, on=["key"], how="right")
outer_join = df1.merge(df2, on=["key"], how="outer")

查找值不需要是查找表的第一列; 如果匹配多行,则每个匹配都会有一行,而不仅仅是第一行; 它将包括查找表中的所有列,而不仅仅是单个指定的列; 它支持更复杂的连接操作;
其他注意事项
1. 填充柄
df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))})
series = list(range(1, 5))
df.loc[2:5, "AAA"] = series
df

2. 删除重复项
df = pd.DataFrame({
"class": ["A", "A", "A", "B", "C", "D"],
"student_count": [42, 35, 42, 50, 47, 45],
"all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"]})
df.drop_duplicates()
df.drop_duplicates(["class", "student_count"])

3. 数据透视表
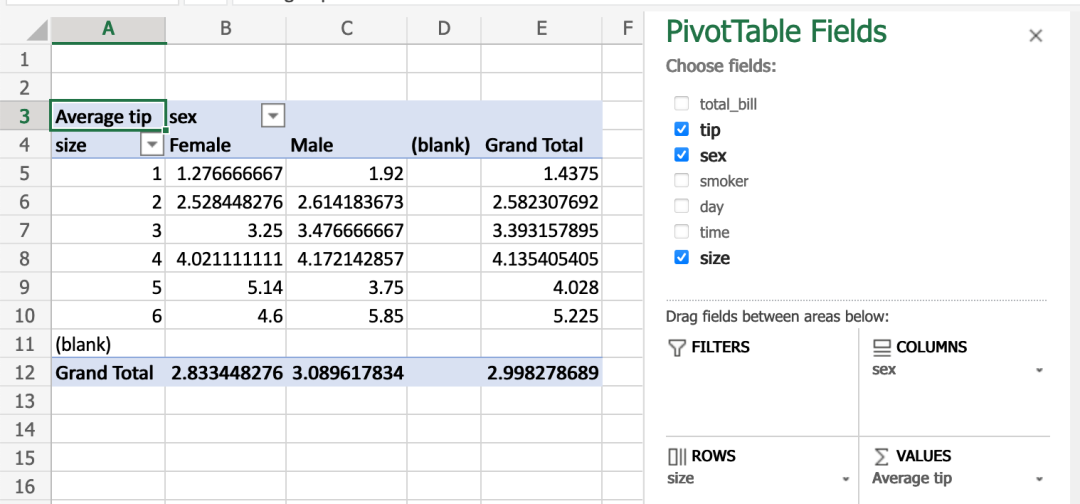
pd.pivot_table(
tips,
values="tip",
index=["size"],
columns=["sex"],
aggfunc=np.average)

4. 添加一行
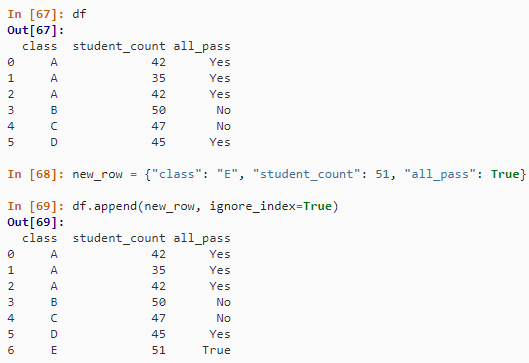
df
new_row = {"class": "E", "student_count": 51, "all_pass": True}
df.append(new_row, ignore_index=True)
5. 查找和替换
tips
tips == "Sun"
tips["day"].str.contains("S")
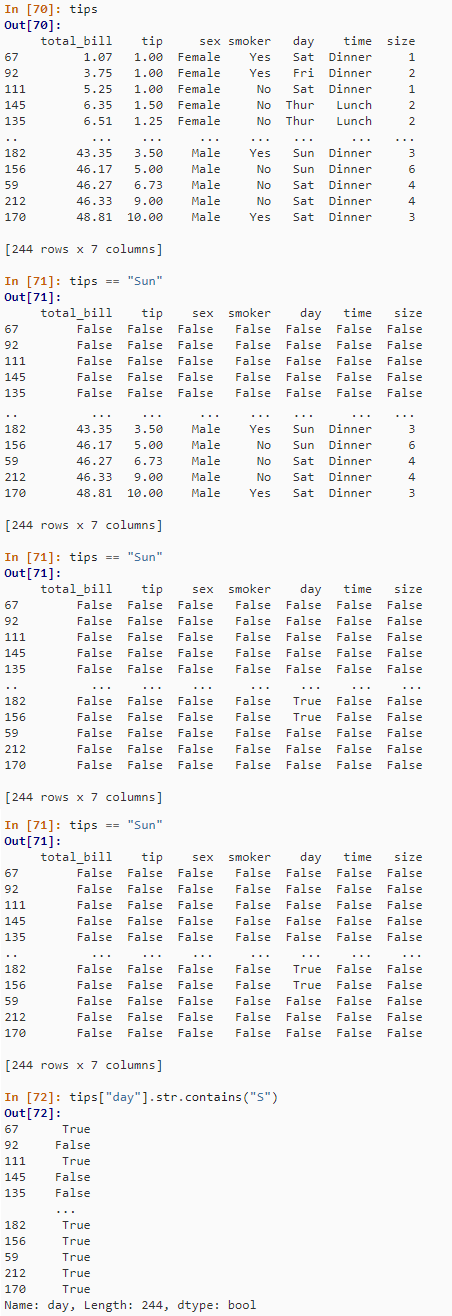
tips.replace("Thu", "Thursday")

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
评论