
重新思考空洞卷积 | RegSeg超越DeepLab、BiSeNetv2让语义分割实时+高精度


语义分割的最新的一些研究通常采用ImageNet预训练Backbone,在其后面加上特殊的上下文模块,以快速增加感受野。虽然取得了一定的效果,但是Backbone也带来了大部分计算。最近的一些进展解决了这个问题,方法是快速降低Backbone的分辨率,同时拥有一个或多个具有更高分辨率的平行分支。
作者采用了不同的方法,设计了一个受ResNeXt启发的Block结构,使用2个具有不同的膨胀率的并行3x3卷积层,以扩大感受野,同时保留局部细节。通过在Backbone中重复这个Block结构,不需要在它后面附加任何特殊的上下文模块。
此外,作者提出了一种轻量级解码器,它能比一般的替代方案更好地恢复局部信息。为了证明方法的有效性,RegSeg模型在Cityscapes和CamVid数据集上取得了最先进的结果。使用混合精度的T4 GPU, RegSegCityscapes测试集上达到78.3 mIOU,速度达到在30FPS/秒,在CamVid测试集上达到80.9 mIOU,速度达到70FPS/秒的,两者都没有ImageNet预训练。
1简介
语义分割是对输入图像中的每个像素进行分类的任务。它的应用包括自动驾驶、自然场景理解和机器人技术。它也是全景分割方法的基础,该方法除了为每个像素分配一个类之外,还分离同一类的实例。
先前语义分割方面的进展通常采用ImageNet预训练Backbone,并添加上下文模块,该模块具有较大的平均池化(如PPM)或较大的膨胀率(如ASPP),以快速扩大感受野。它们利用ImageNet预训练的权值以实现在PASCAL VOC 2012等较小的数据集上更快的收敛和更高的精度,在这些数据集上,从头开始训练可能是不可能的。这种方法有两个潜在的问题。ImageNet Backbone通常在最后几个卷积层中有大量的通道,因为它们旨在将图像标记到ImageNet中1000个类中的一个。例如,ResNet18以512通道结束,ResNet50以2048通道结束。
Mobilenetv3的作者发现,将上一个卷积层的通道数量减半并不会降低语义分割的准确性,这暗示了ImageNet模型的通道冗余。其次,ImageNet模型被调优以获取分辨率约为224x224的输入图像,但语义分割的图像要大得多。例如,Cityscapes的图像分辨率为1024x2048, CamVid的图像分辨率为720x960。ImageNet模型缺乏对如此大的图像进行编码。
这两个问题启发作者设计一个专门用于语义分割的Backbone。作者通过引入一种称为“D Block”的新型膨胀结构,直接增加了Backbone中的感受野,并且可以让backbone中的通道数量降低。作者从ResNeXt块结构中获得灵感,该结构在传统的ResNet块中使用了组卷积来提高其准确性,同时保持了相似的复杂度。RegNet采用ResNeXt块,并在广泛的FLOP机制中提供更好的Baseline。
作者采用快速RegNetY-600MF进行语义分割,用“D Block”替换原来的“Y Block”。特别是,当进行组卷积时,“D Block”对一半组使用一个膨胀率,对另一半使用另一个膨胀率。通过在RegSeg Backbone中重复“D Block”,可以很容易地增加感受野而不丢失局部细节。RegSeg的Backbone使用高达14的膨胀率,由于它有足够的感受野,所以不添加任何上下文模块,如ASPP或PPM。
许多最近的工作,如Auto-DeepLab、Dilated SpineNet和DetectoRS都不太愿意在架构设计空间中包含具有大膨胀率的膨胀卷积,仍然依赖于诸如ASPP或PPM之类的上下文模块来增加感受野。作者从很小的膨胀率开始,并始终将一个分支的膨胀率设为“D Block”,以此来解决这个问题。作者希望这项工作可以激励未来的研究人员在模型中尝试更大的膨胀率。
作者还提出了一种轻量级的解码器,它可以有效地恢复在Backbone中丢失的局部细节。以前的解码器(如DeepLabv3+中的解码器)太慢,无法实时运行,而常见的轻量级解码器(如LRASPP)也没有那么有效。在相同的训练设置下,本文的解码器比LRASPP提高了1.0%。
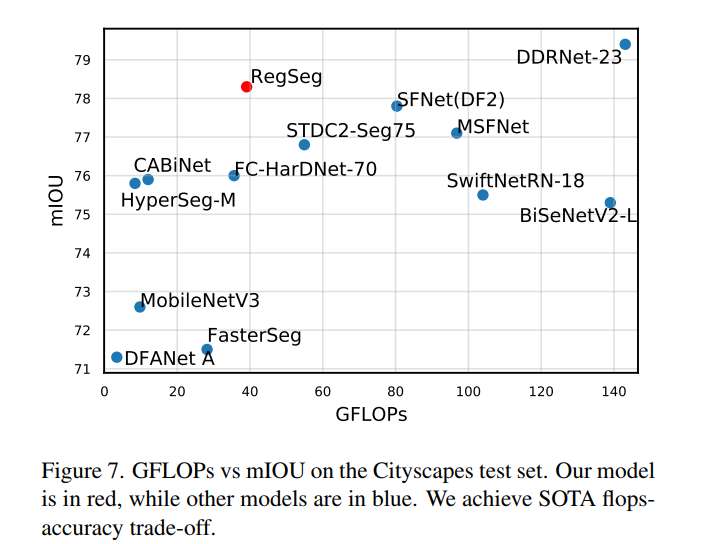
RegSeg是实时运行的。使用具有混合精度的T4 GPU, RegSeg在Cityscapes和CamVid中以30 FPS和70 FPS的速度运行。许多任务需要模型实时运行,比如自动驾驶或移动部署。实时模型比非实时模型更高效,而且当计算复杂度扩大到相同时,它们有潜力击败最先进的模型。例如,EfficientNet先前通过使用神经结构搜索发现的一个低计算模型,通过按比例放大,在ImageNet上获得了最先进的结果。
总而言之,本文的贡献如下:
提出了一种新的 dilated block 结构“D Block”,它可以在保持局部细节的同时轻松地增加Backbone的感受野。通过在RegSeg的Backbone中重复D Block,我们可以控制视场而无需额外的计算; 介绍了一种轻量级解码器,它的性能优于常见的方案; 进行了大量的实验来证明方法的有效性。RegSeg在Cityscapes测试集上实现了78.3 mIOU,同时达到30帧/秒,在CamVid测试集上实现了80.9 mIOU,速度70帧/秒,两者都没有经过ImageNet预训练。在Cityscapes测试集上,RegSeg比SFNet(DF2)的最佳结果高出0.5%。在相同的训练设置下,RegSeg在Cityscapes上的表现比DDRNet-23表现好0.5%。
2相关工作
2.1 网络设计
在ImageNet上训练的模型在一般任务的网络设计中起着重要的作用,它们的改进常常迁移到其他领域,如语义分割。
通过使用随机搜索进行了大量的实验和分析,RegNet对ResNeXt架构的许多改进。它们提供了各种模型,并且在可比的训练设置下,这些模型优于EfficientNet。Effecentnetv2是Effecentnet的改进版本,它通过使用常规的转换而不是在更高分辨率下的深度转换来提高训练速度。在本文中,从RegNet中汲取灵感,采用其块结构进行语义分割。
2.2 语义分割
Fully Convolutional Networks (FCNs)在分割任务上优于传统方法。DeepLabv3在ImageNet预训练的Backbone中使用空洞卷积,将输出stride减少到16或8,而不是通常的32,并通过提出Atrous空间金字塔池模块(ASPP)来增加感受野,该模块并行地应用了不同扩张率的卷积层分支。图2是一个空洞卷积的例子。
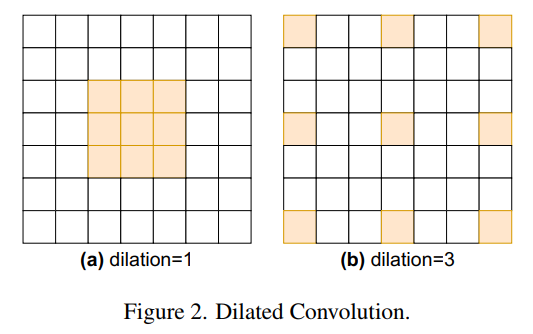
PSPNet提出了金字塔池化模块(Pyramid Pooling Module, PPM),它通过首先应用平均池化来应用不同输入分辨率的卷积层的并行分支。在本文中提出了与ASPP结构相似的 dilated block (“D Block”),并将其作为Backbone的主要构建块,而不是在末端附加一个。
DeepLabv3+是在DeepLabv3上的改进,通过添加一个简单的解码器,在输出stride为4处添加2个3 × 3 convs,以提高边界周围的分割质量。
HRNetV2在Backbone中保持不同分辨率的平行分支,最细的分支在输出stride为4。
2.3 实时语义分割
MobilenetV3使用轻量级解码器LRASPP来适应ImageNet模型进行语义分割。BiSeNetV1和BiSeNetV2在Backbone中有两个分支(空间路径和上下文路径),并在结束时合并它们以获得良好的准确性和性能,而不需要ImageNet预训练。SFNet提出了Flow Alignment Module (FAM)来向上采样低分辨率的特征比双线性插值更好。STDC通过删除空间路径和设计一个更好的Backbone来重新考虑BiSeNet体系结构。
HarDNet主要使用3×3卷积和1×1卷积减少GPU内存消耗。DDRNet-23使用两个分支,它们之间有多个双边融合,并附加一个新的上下文模块称为Deep Aggregation Pyramid Pooling Module(DAPPM)。DDRNet-23是目前最先进的实时Cityscapes 语义分割技术,本文也证明了在相同的训练设置下RegSeg优于DDRNet-23。
3本文方法
3.1 Field-of-View
作者感兴趣的是通过卷积获得的模型的Field-of-View(FOV),也被称为感受野。例如,两个3x3 convs的合成到5x5 conv,简单地说感受野是5x5。更一般地,卷积组成的感受野可以像FCN中描述的那样迭代计算。
假设到当前为止的conv的组成在kernel大小和stride上是相等的(kernel=3x3,stride=s),用一个 k'× k' 的conv和stride s'组成它。更新k和s:
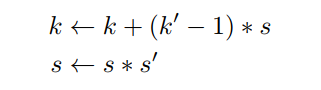
k是Field-of-View的最终值。
有两种方法可以有效地增加感受野。一种是在早期用stride为2或平均池化进行采样。另一种方法是使用空洞卷积,扩张率为r的卷积在感受野上等于kernel大小为2r+1的卷积。
然而,为了不在权值之间留下任何洞,需要,其中k和s是使用到当前为止的卷积函数的组成来计算的,如前一段所述。这作为r的上界,在实际中,选择的膨胀率比上界低得多。
感受野与输入图像大小之间的关系对模型的精度影响很大。例如,如果在ImageNet上使用ResNet架构,测试大小为224x224,并在全局平均池化之前查看特征图,模型需要至少224*2-1= 447的感受野,左上角像素才能看到整个图像。同样,对于图像大小为1024x2048的Cityscapes,模型需要输出的左上角像素的感受野为2047,才能看到输入图像的左下角像素,需要输出的感受野为4095,才能看到输入图像的右下角像素。
3.2 Dilated Block
Dilated Block(D Block)来源于RegNet的Y Block,也称为SE-ResNeXt Block。Y Block和新的D Block都利用了组卷积。假设输入通道=输出通道= w,这对于Y Block和新的D Block中的3 × 3卷积始终成立。组卷积有一个属性叫做组宽度g,g整除w。在前向传播期间,w个输入通道被分为w/g组,并最终重新拼接为w个通道。
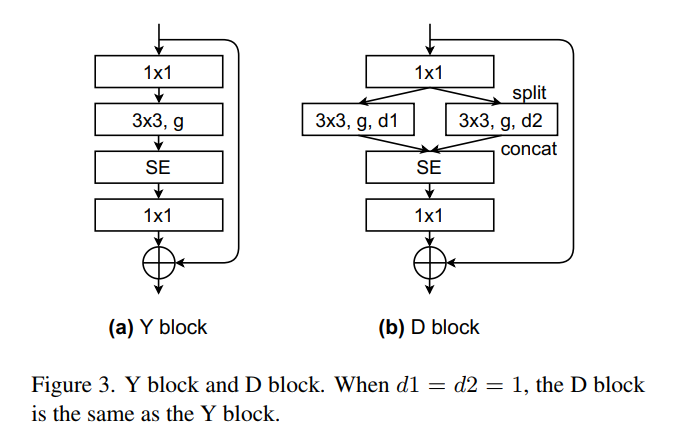
由于每组都有一个卷积,可以对不同的组应用不同的扩张率来提取多尺度特征。例如,可以对一半的组应用扩张率1,对另一半应用扩张率10。这是D Block的关键。图3a显示了Y Block。图3b显示了D Block。当d1=d2=1时,D Block与Y Block相等。在第4.4节中,实验了一些有4个不同膨胀率分支的D Block,但发现它们并不比有2个分支的D Block好。
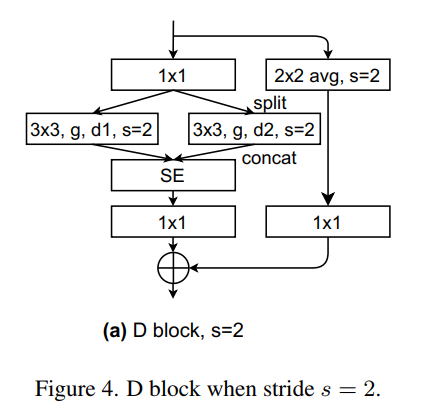
图4为步幅为2时的D Block。与ResNet D-variant类似,当Block的stride=2时,在shortcut分支上应用2×2平均池化。BatchNorm紧跟每个卷积之后。ReLU则是在第一个1 × 1卷积,3 × 3卷积,和求和之后。
深度学习框架支持组卷积,每个组卷积应用相同的扩张率。由于D Block对不同的组使用不同的扩张率,所以必须手动分割输入,应用conv,然后连接。这里使用(d1,d2)表示D Block的扩张率。

在表1中,显示了手动拆分和连接以及使用扩张会话影响了速度。因此,Y Block比D Block稍微快一些,尽管它们具有相同的FLOP复杂度和参数计数。当在实践中使用D block(1,1)时,不需要手动拆分和连接,因为两个分支使用相同的扩张率。
3.3 Backbone
Backbone是通过重复D Block构建的,样式类似于RegNet。Backbone以一个32的通道3×3卷积为起点,stride为2。在1/4分辨率有一个48通道的D Block,在1/8分辨率有3个128通道的D Block, 在1/16分辨率有13个256通道的D Block,在1/16分辨率结束位置有1个320通道的D Block。这里没有设置下采样倍数为32。
本文在分辨率为1/16时,总共提升了13个stride为1的block的扩张率:1 (1,1)、1(1,2)、4(1,4)、7 (1,14)。作为简写,这里将扩张率表示为(1,1) + (1,2) + 4∗(1,4)+7∗(1,14)。对于所有其他Block使用的扩张率为(1,1),等同于Y Block。
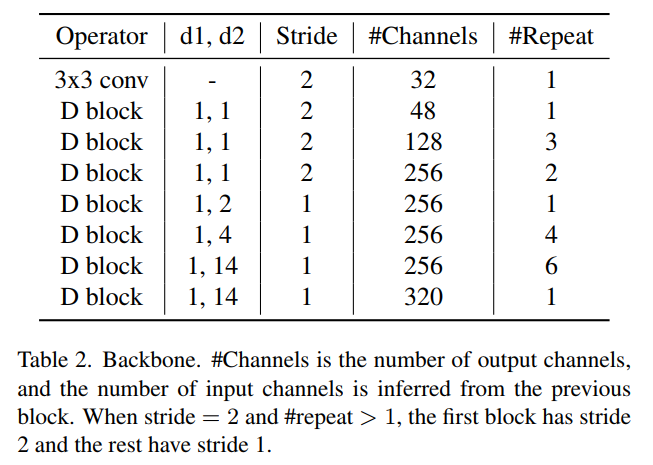
在一种类似于EfficientNetV2的格式中,在表2中显示了RegSeg的Backbone。为最后13个Block选择正确的扩张率是很重要的,在第4.4节中对扩张率进行了实验。
3.4 Decoder
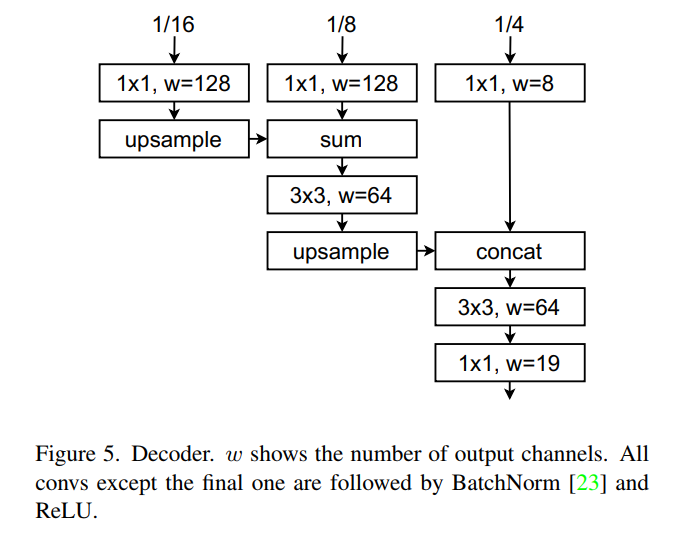
解码器的工作是恢复丢失在Backbone中的局部细节。与DeepLabv3+类似,使用[k × k,c]表示C个输出通道的k × k卷积。将backbone的最后1/4、1/8和1/16特征映射作为输入。将a[1x1, 128] conv应用于1/16、a[1x1, 128] conv应用于1/8、a[1x1, 8] conv应用于1/4。向上采样1/16,将它与1/8相加,然后再应用一个[3x3, 64]的卷积。再次向上采样,连接1/4,并在最终的[1x1,19]卷积之前应用一个[3x3,64]卷积。除了最后一个卷积之外,所有卷积后面都跟着BatchNorm和ReLU。解码器如图5所示。这个简单的解码器比许多现有的具有类似延迟的解码器性能更好。作者也实验了不同的解码器设计。
4实验
4.1 Backbone Ablation Studies

4.2 CamVid 数据集
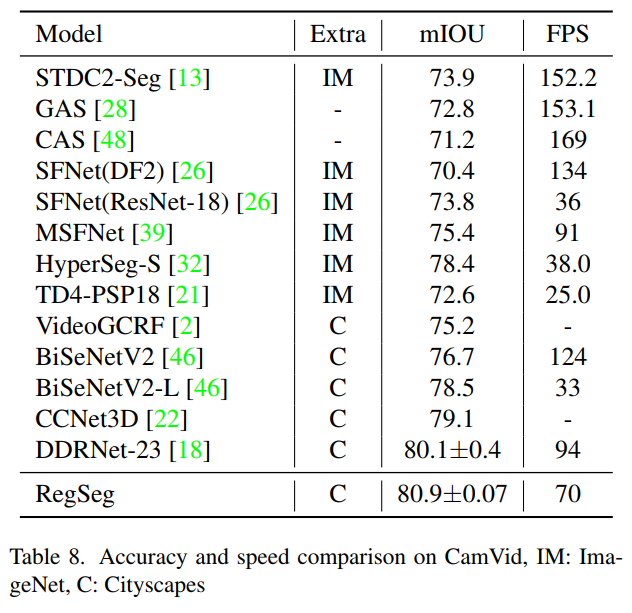
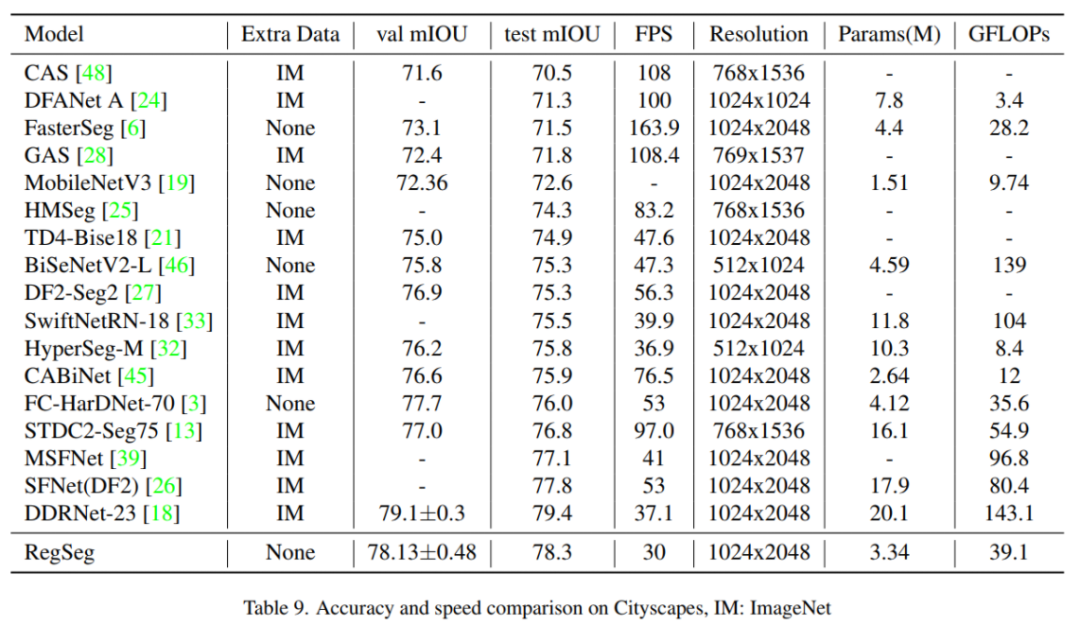
4.3 Cityscapes
5参考
[1].Rethink Dilated Convolution for Real-time Semantic Segmentation.
6推荐阅读

全新数据增强 | TransMix 超越Mix-up、Cut-mix方法让模型更加鲁棒、精度更高

全新池化方法AdaPool | 让ResNet、DenseNet、ResNeXt等在所有下游任务轻松涨点

NWD-Based Model | 小目标检测新范式,抛弃IoU-Based暴力涨点(登顶SOTA)
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
