
【数据竞赛】风控实操案例 | 基于Xgboost与Catboost实现非法集资企业识别
import osos.chdir('/home/datafountain/work/')
# !unzip pictures.zip数据集版权说明:本实践使用竞赛数据集,请勿用于商业用途。
00
概述
特征编码
Macro-F1 Score与Micro-F1 Score
(上述知识点均可在DF官网【社区】板块查看)
本教程以2020CCF大赛非法集资企业识别为例,演示了风控赛题建模的完整流程,利用Xgboost、Catboost等机器学习方法训练一个预测模型,该模型可学习企业的相关信息,以预测企业是否存在非法集资风险。数据集包括大量的企业相关信息,如何从中提取有效的特征并进行风险预测是风控任务中的关键问题。
类别与编码的对应关系如下表所示:
类别名 | 正常 | 风险 | ||
教程 | 0 | 1 | ||
该数据集包含约25000家企业数据,其中约15000家企业带标注数据作为训练集,剩余数据作为测试集。数据由企业基本信息、企业年报、企业纳税情况等组成,数据包括数值型、字符型、日期型等众多数据类型(已脱敏),部分字段内容在部分企业中有缺失,其中第一列id为企业唯一标识。
数据可以从官网【数据集】下载,下载后解压替换data目录。
Python3.7环境下测试了本教程代码。需要的第三方模块和版本包括:
catboost==0.24
jieba==0.42.1
lightgbm==2.3.1
numpy==1.16.4
scikit-learn==0.21.2
tqdm==4.32.1
xgboost==0.90
pandas==0.24.2
toad==0.0.61
本教程包括以下内容:数据探索、特征提取、特征筛选、模型融合,通过分析企业各类信息统计表,紧紧围绕非法集资不同的风险类型,提取出可解释特征。差异性是融合提升的关键,通过特征差异(不同表的特征结合)、模型差异(catboost模型与xgboost模型)、参数差异三个角度构造差异性的模型,进行加权投票融合,提升模型的稳定性与泛化能力。
# 使用pip命令安装指定版本工具包# !pip install jieba tqdm scikit-learn catboost!pip install catboost -i https://pypi.doubanio.com/simple/
# !pip install toad==0.0.61#统一导入工具包import pandas as pdimport numpy as npfrom sklearn.model_selection import StratifiedKFoldfrom catboost import CatBoostClassifierfrom sklearn.preprocessing import LabelEncoderimport gcimport osfrom sklearn.metrics import precision_score, recall_score, f1_scoreimport xgboost as xgbimport warningswarnings.filterwarnings("ignore")import jiebaimport matplotlib.pyplot as plt%matplotlib inline
# Debug参数DEBUG = True # Debug模式可快速跑通代码,非Debug模式可得到更好的结果Iterations=20 if DEBUG else 5000
01
数据分析
对赛题任务进行剖析,并进行初步的数据的探索,包含标签分布、缺失值等。
!mkdir datasets/ submit/ temp/!mkdir datasets/data datasets/pretrained!unzip -o ../datasets/test.zip -d datasets/data!unzip -o ../datasets/train.zip -d datasets/datacp ../datasets/cn_stopwords.txt /home/datafountain/work/datasets/pretrained/
赛题目标为企业非法集资风险的预测,目前监控和识别非法集资的行为,主要依靠人工收集相关信息实现,依赖历史经验对大量的财务报表进行数字逻辑分析以及统计分析,准确率和效率均较低,利用机器学习等方法训练出一个预测模型,通过学习企业的相关信息来预测企业是否存在非法集资风险,有重要的应用价值。
企业非法集资涉及投资理财、P2P网贷、房地产、教育、私募股权等多种形态,具有非法性、利诱性、公开性和社会性等特点,具体表现为基本风险(企业状态、企业类型、经营范围)、行为风险(产品个数、招聘信息、知识产权)、舆情风险(负面新闻次数)、遵从风险(投诉举报、涉案次数)四种类型,风险的界定对后续的特征工程有重要的指导意义。比赛题前期指标为AUC,后采用分类任务的精确率 P(precision)、召回率 R(recall)和 F1-score三个指标作为模型性能的评判标准,具体权值未知。
# 读取数据base = pd.read_csv('./datasets/data/train/base_info.csv')label = pd.read_csv('./datasets/data/train/entprise_info.csv')entprise_evaluate = pd.read_csv('./datasets/data/test/entprise_evaluate.csv')train = label.merge(base, on='id', how='left')test = entprise_evaluate.merge(base, on='id', how='left')target = train.labeltarget.value_counts().plot.bar()
print(target.value_counts(normalize=True))import toadtoad.detect(train)
toad.detect(test)# 删除缺失率较高的列base = base.drop(columns=['congro','exenum','forreccap','forregcap','midpreindcode','parnum','protype','ptbusscope'])
02
特征工程
特征决定了模型的上限,特征工程主要包括三部分,特征编码、可解释性特征提取、其他特征。
对于不同类别特征,我所用到的编码方式主要有三种,Label-Encode、Target-encode、Freq-encode,主要的思路为如下图:
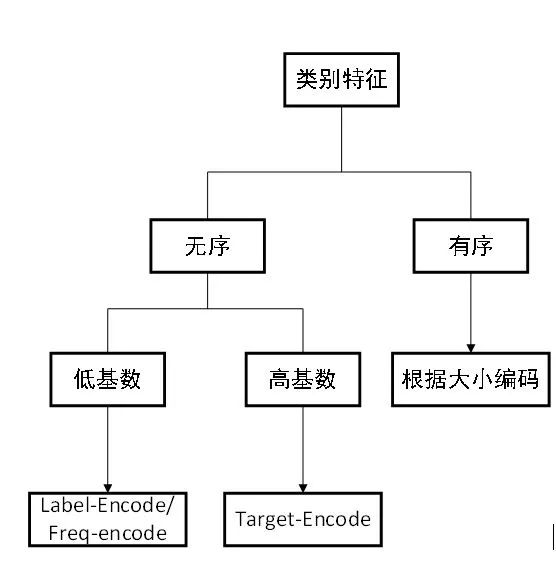
对于有序的类别特征,根据大小顺序进行整数编码,例如对基础信息表中的,对于无序的类别特征,根据其类别基数大小,低基数采用Label-Encode或者Freq-Encode,并且将频率较小的类别统一编码,增强低频类别的表答能力,提高模型的稳定性;高基数采用target-Encode,使得编码后的数字可以代表不同类别下的风险概率,有明确的意义与大小关系,同时采用5折交叉的方式编码(与后续训练集划分一致),减小过拟合,增加特征的稳定性。
# 目标编码函数def kfold_stats_feature(train, test, feats, k, seed):'''Target-Encode'''folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=seed) # 这里最好和后面模型的K折交叉验证保持一致…… ……del train['fold']return train, test# 初始化种子与交叉验证折数seed = 2020k = 5…… ……del datagc.collect()print('done...')
(部分代码略)
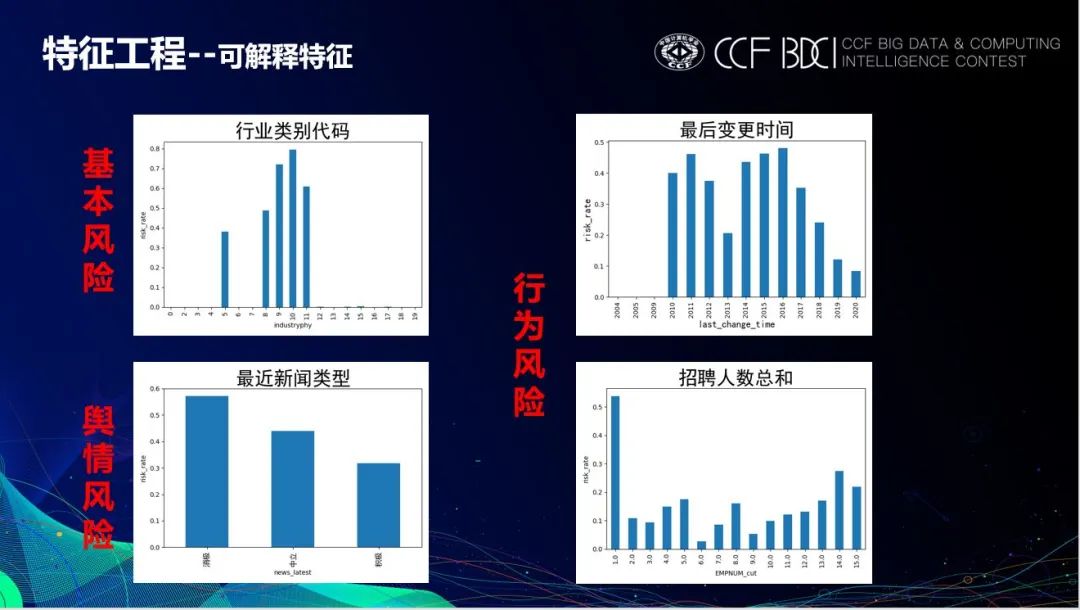
可解释特征的提取是本次比赛的关键,本赛题中仅仅围绕非法集资的四种风险类型构造出一系列可解释性特征,与业务紧密结合,应用价值较高。具体特征如下图:

# 可解释性特征def gen_annual(annual_report):'''年报表特征提取'''新闻表特征提取'''变更表特征提取'''报税表特征提取'''
(部分代码略)
下面是一些可解释性特征的展示,横轴为特征的取值,纵轴为风险概率,可以看出提取的可解释性特征对非法集资有很明显的区分效果
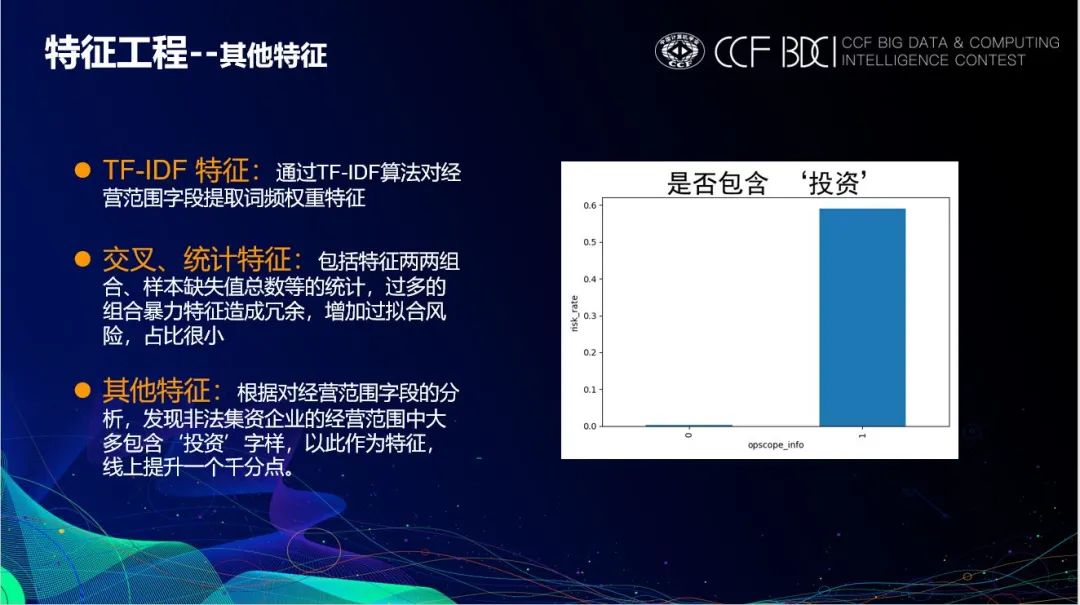
其他特征主要包括一些交叉组合特征,以及特殊字段的特征提取,例如经营范围opscope列,为文本类型字段,通过TF-IDF计算文本中的词频权重,并进行均值等统计特征的提取,取得了一定的提升。
2.3.1 tfidf特征
# 创建一个停用词列表stopwords = [line.strip() for line in open('./datasets/pretrained/cn_stopwords.txt', encoding='UTF-8').readlines()]# 结巴分词…………print('对opscope提取tfidif特征完毕..........')base_info[['id', 'tfidif_opscope']].to_csv('./temp/tfidf_op.csv', index=False)gen_tfidf()
(部分代码略)
2.3.2 特殊特征
# opscope 字段中是否包含投资train['opscope_info'] = train.opscope.apply(lambda x: 1 if '投资' in x else 0)test['opscope_info'] = test.opscope.apply(lambda x: 1 if '投资' in x else 0)
03
模型训练
特征工程完成后,分别构建Catboost模型与Xgboost模型进行训练。
包含了数据读取、特征工程、模型训练完整步骤。
def cal_f1(train_y, train_pred, test_y, val_pred):train_pred[train_pred >= 0.5] = 1train_pred[train_pred < 0.5] = 0#… …# 导入数据print('读取数据...')……sub_df.to_csv('./temp/cat_{}.csv'.format(model_num),index=False)return sub_dfcat1 = cat_model(False, 1)cat2 = cat_model(True, 2)
(部分代码略)
包含了数据读取、特征工程、模型训练完整步骤。
def f1_score_eval(preds, valid_df):'''自定义XGB的早停函数'''# ***导入数据***print()base = pd.read_csv('./datasets/data/train/base_info.csv')'''print('OOF-MEAN-AUC:%.6f, OOF-STD-AUC:%.6f' % (np.mean(offline_score), np.std(offline_score)))print(feature_importance_df.groupby(['Feature'])['importance'].mean().sort_values(ascending=False)) # 特征重要性sub_df = test[['id']].copy().reset_index(drop=True)sub_df['score'] = output_predssub_df.to_csv('./temp/xgb_{}.csv'.format(model_num), index=False)return sub_dfxgb1 = xgb_model(False, 1)xgb2 = xgb_model(True, 2)
(部分代码略)
04
模型融合
对上面两个模型进行模型融合,提升模型的鲁棒性。
模型之间的差异性是提升的关键,可以通过以下三方面提升差异性:
特征差异:特征差异主要依靠不同表特征的组合获得,以base表中的特征为基础特征,分别加上新闻表、变更表、年报表中的不同特征,构造出两套差异性特征,供模型训练。
模型差异:模型差异主要靠Xgboost模型与Catboost模型来实现。
参数差异:通过对模型中列采样率、随机种子等参数的扰动实现。
使用mic值对训练出的模型进行差异性分析,选取差异性大的进行融合,得出四个模型mic值。
def voting(ll):for i, oof in enumerate(ll):oof[f'score_{i}'] = oof.score.apply(lambda x: 1 if x > 0.5 else 0)sub = ll[0].id.copy()sub = pd.DataFrame(sub)for i, tmp in enumerate(ll):sub = sub.merge(tmp, on='id', how='left')sub['score'] = sub.iloc[:, 1:].apply(lambda x:x.mode()[0], axis=1)sub[['id', 'score']].to_csv('./submit/result.csv', index=False)return sub[['id', 'score']]
05
模型结果展示
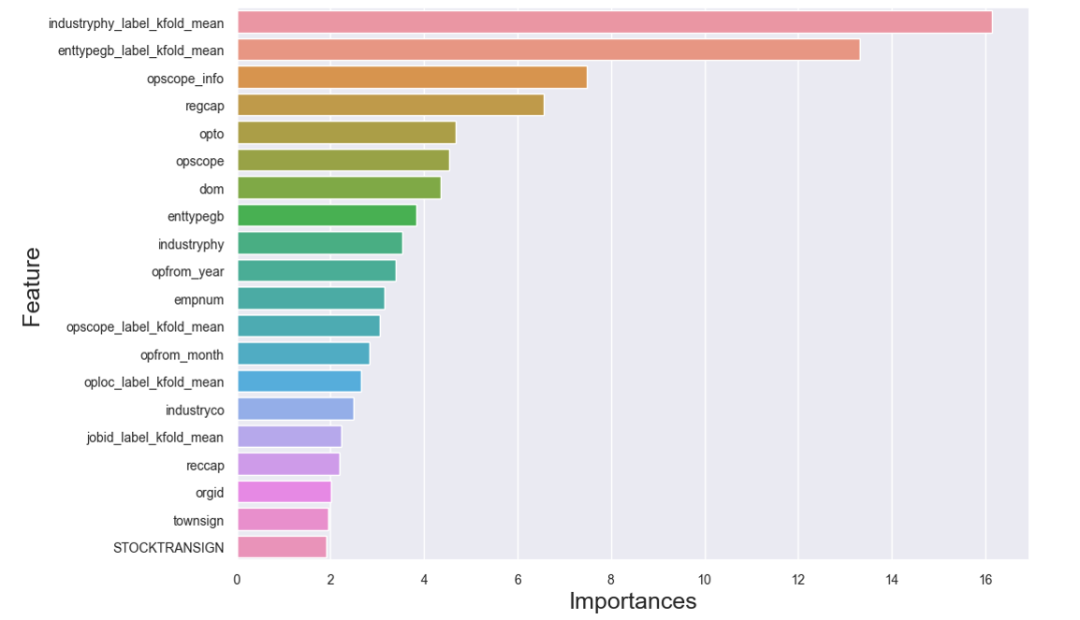
fusion.score.value_counts().plot.bar()fusion.score.value_counts()以Catoost为例,展示前20个重要特征。
06
优化思路
数据清洗:去除缺失率极高的干扰样本。
调整Xgboost、Catboost模型参数。
词向量特征:使用news_info、tax_info等表预训练词向量(word2vec等),并提取统计特征。
后处理:对 F1-score 进行阈值搜索等。
往期精彩回顾
本站qq群851320808,加入微信群请扫码: