
一文理解如何解决Kafka消息积压问题
通常情况下,企业中会采取轮询或者随机的方式,通过Kafka的producer向Kafka集群生产数据,来尽可能保证Kafk分区之间的数据是均匀分布的。
如果对Kafka不了解的话,可以先看这篇博客《一文快速了解Kafka》。
消息积压的解决方法
加强监控报警以及完善重新拉起任务机制,这里就不赘述了。
1.实时/消费任务挂掉导致的消费积压的解决方法
在积压数据不多和影响较小的情况下,重新启动消费任务,排查宕机原因。
如果消费任务宕机时间过长导致积压数据量很大,除了重新启动消费任务、排查问题原因,还需要解决消息积压问题。
解决消息积压可以采用下面方法。
任务重新启动后直接消费最新的消息,对于"滞后"的历史数据采用离线程序进行"补漏"。
如下面图所示。创建新的topic并配置更多数量的分区,将积压消息的topic消费者逻辑改为直接把消息打入新的topic,将消费逻辑写在新的topic的消费者中。
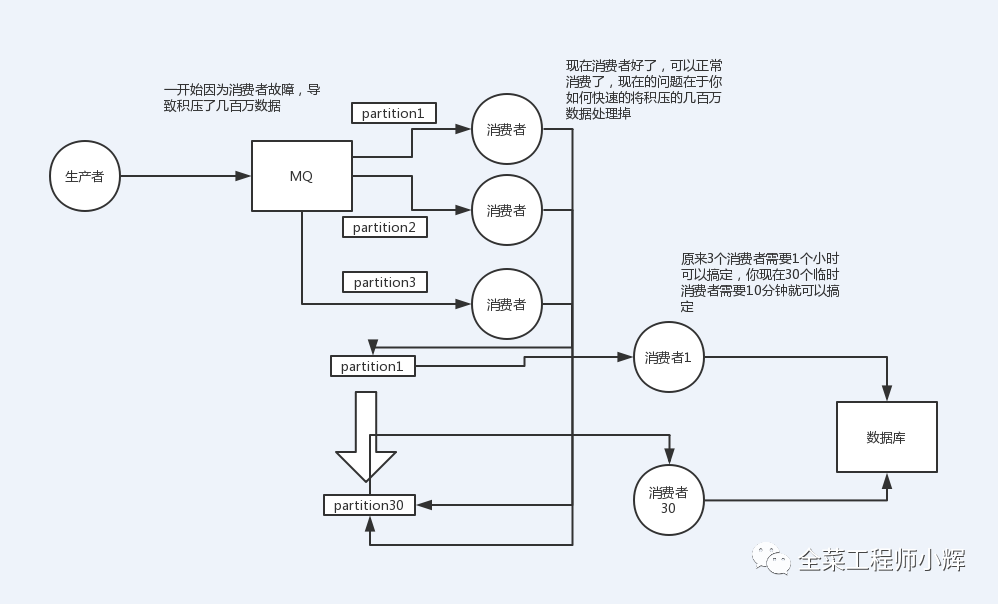
如果还需要保证消息消费的局部有序,可以将消费者线程池改成多个队列,每个队列用单线程处理,更多内容可以查看博客《一文理解Kafka如何保证消息顺序性》
2.Kafka分区数设置的不合理或消费者"消费能力"不足的优化
Kafka分区数是Kafka并行度调优的最小单元,如果Kafka分区数设置的太少,会影响Kafka Consumer消费的吞吐量。
如果数据量很大,Kafka消费能力不足,则可以考虑增加Topic的Partition的个数,同时提升消费者组的消费者数量。
3.Kafka消息key设置的优化
使用Kafka Producer消息时,可以为消息指定key,但是要求key要均匀,否则会出现Kafka分区间数据不均衡。
所以根据业务,合理修改Producer处的key设置规则,解决数据倾斜问题。
评论