
5 层数据开发基本功, 你在第几层?
数据科学家,必备数据开发基本功。
妄谈:高等统计、机器学习、神经网络....
不如脚踏实地从基本功开始,学点基本功和SQL一技之能。
1,指标度量:客户想要什么?
当我们接触到一个数据开发的需求时,我们首先要知道客户想要的是什么?理清客户的诉求,是我们评估可行性方案的第一步。第一步我们要清楚的是每一个数据指标。需要我们拆解出来:什么是原子指标,复合指标以及衍生指标?这离不开对业务场景的理解。
原子指标:又叫基础指标,指表达业务实体原子量化属性的且不可再分的概念集合,如交易笔数、交易金额、交易用户数等。
复合指标:指建立在基础指标之上,通过一定运算规则形成的计算指标集合,如平均用户交易额、资产负债率等。
衍生指标:又叫派生指标、指基础指标或复合指标与维度成员、统计属性、管理属性等相结合产生的指标,如交易金额的完成值、计划值,累计值、同比、环比、占比等。
2,数据从哪里来
数据的可获取性取决于数据的来源,数据的来源也决定了我们处理的方式,数据开发最耗时的部分是数据抽取,即ETL中的E。需要我们对混杂的数据进行模型化,模型化之后我们就可以使用结构化查询语句(SQL)去加工处理。
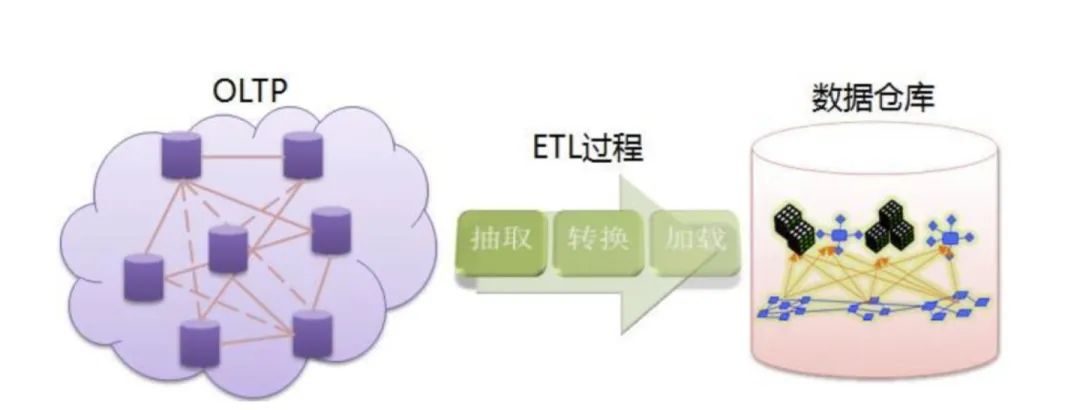
普通的文本文件,我们可以借助脚本语言比如:AWK、Pig、R、Python;让大家欣慰的是R中的sqldf包可以用SQL语句处理数据框;同样Python中的Pysqldf包也可以使用SQL语句处理数据框。所以对于数据开发来说:SQL可以解决90%的工作。
业务系统结构化的数据表,一般是同步到HDFS做数据存储,利用hive利器来处理ETL工作。
3,建仓:如何组织好大量的数据
数据仓库建模是一个综合性技术,需要使用到 ER 建模、关系建模、维度建模等技术。如何将来源多样,格式混杂的数据通过ETL处理组织到一个高性能、低成本、高效率、高质量的数仓中,让业务有数据看、用好数、有价值是数据开发最为重要的任务。
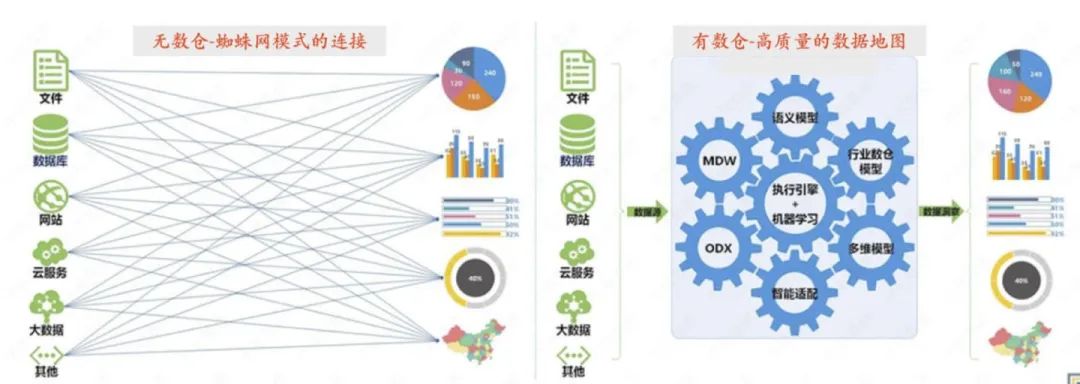
顺便科普一下数仓主要的四种建模方式:
范式建模(Third Normal Form,3NF)是在构建数据模型常用的一个方法,该方法主要由 Inmon 所提倡,主要解决关系型数据库的数据存储,利用的一种技术层面上的方法。目前在关系型数据库中的建模方法,大部分采用的是三范式建模,即通过实体关系(Entity Relationship,ER)模型描述企业业务。
维度建模是数据仓库领域另一位大师 Ralph Kimball 所倡导,是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。维度建模是专门用于分析型数据库、数据仓库、数据集市建模的方法。
Data Vault模型是 Dan Linstedt 在 20 世纪 90 年代提出的,主要在对自然界中发现的复杂网络建模。
Anchor对Data Vault模型做了进一步规范化处理,初衷是设计一个高度可扩展的模型,其核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了k-v结构化模型。
4,数据的应用
基于数据仓中的数据,我们可以开发下一步,提供一个满足业务的数据应用。业务数据应用通常分为两种:一是描述应用,二是推断应用。
描述应用多为数据表格的展示及图表的可视化,支持业务的多维度分析主要用来描述业务现状。推断应用是数据的延展应用多为挖掘发现信息沉淀为认知基于用户偏好的推荐,风险预测等主要为了推动业务增长。

5,数据开发没有边界
数据开发其实是没有边界的,不仅可以写出很风流的SQL,也懂数仓建模,更懂统计分析,很多开发同学对挖掘算法也颇有研究。没有边界就没有发展的限制,一切都是为了生活,技多不压身,为业务和人民(币)服务。积极满足业务需求和质量需求。
业务需求是最终用户作出决策所需的信息内容。开发人员需要作出判断,原始数据源是否能够解决用户的业务需求,也可能会发现数据源额外的能力,从而扩展最终用户的决策支持能力。从更广泛的意义上讲,业务需求和数据源的内容都是不断发生变化的,需要不断地进行校验和讨论。
质量需求是事前调研清楚源数据真实情况。事中保证数仓表真实反映业务场景,对于数据质量有说明可解释。事后对数据质量有监控,及时发现不符合预期的数据情况。