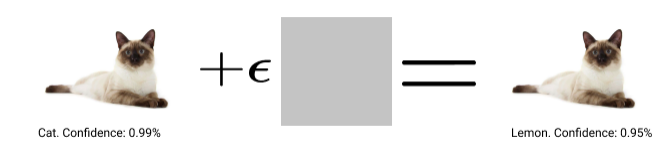人工智能技术解密——机器视觉技术及应用
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
视觉是人类最敏感、最直接的感知方式,在不进行实际接触的情况下,视觉感知可以使得我们获取周围环境的诸多信息。由于生物视觉系统非常复杂,目前还不能使得某一机器系统完全具备这一强大的视觉感知能力。当下,机器视觉的目标即,构建一个在可控环境中处理特定任务的机器视觉系统。由于工业中的视觉环境可控,并且处理任务特定,所以现如今大部分的机器视觉被应用在工业当中。
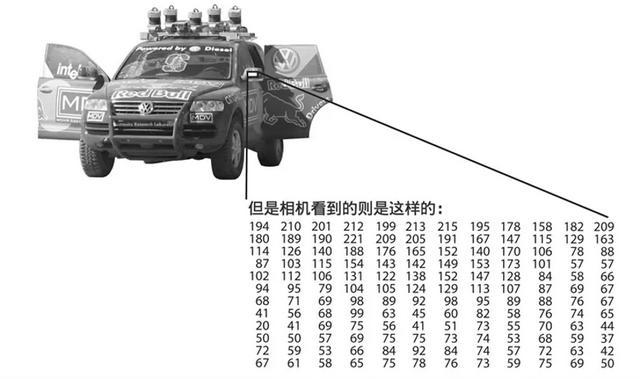
人类视觉感知是通过眼睛视网膜的椎体和杆状细胞对光源进行捕捉,而后由神经纤维将信号传递至大脑视觉皮层,形成我们所看到的图像,而机器视觉却不然。机器视觉系统的输入是图像,输出是对这些图像的感知描述。这组描述与这些图像中的物体或场景息息相关,并且这些描述可以帮助机器来完成特定的后续任务,指导机器人系统与周围的环境进行交互。
那么,迄今为止,主流的机器视觉技术又有哪些呢?
01 中流砥柱——卷积神经网络
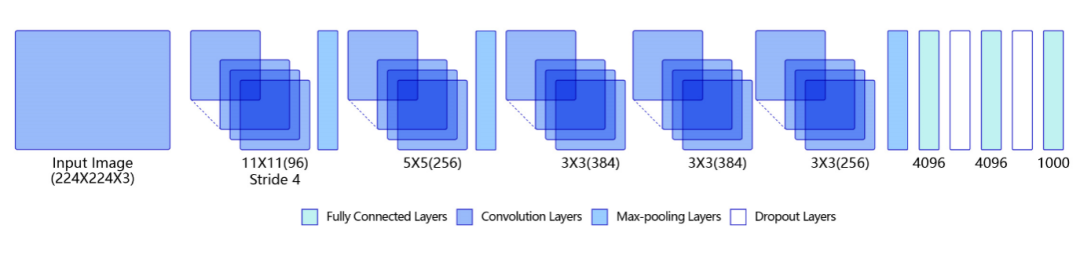
卷积神经网络是目前计算机视觉中使用最普遍的模型结构。引入卷积神经网络进行特征提取,既能提取到相邻像素点之间的特征模式,又能保证参数的个数不随图片尺寸变化。上图是一个典型的卷积神经网络结构,多层卷积和池化层组合作用在输入图片上,在网络的最后通常会加入一系列全连接层,ReLU激活函数一般加在卷积或者全连接层的输出上,网络中通常还会加入Dropout来防止过拟合。
自2012年AlexNet在ImageNet比赛上获得冠军,卷积神经网络逐渐取代传统算法成为了处理计算机视觉任务的核心。
在这几年,研究人员从提升特征提取能力,改进回传梯度更新效果,缩短训练时间,可视化内部结构,减少网络参数量,模型轻量化, 自动设计网络结构等这些方面,对卷积神经网络的结构有了较大的改进,逐渐研究出了AlexNet、ZFNet、VGG、NIN、GoogLeNet和Inception系列、ResNet、WRN和DenseNet等一系列经典模型,MobileNet系列、ShuffleNet系列、SqueezeNet和Xception等轻量化模型。
卷积网络示意图 经典模型,AlexNet:
AlexNet是第一个深度神经网络,其主要特点包括:
1. 使用ReLU作为激活函数。
2. 提出在全连接层使用Dropout避免过拟合。注:当BN提出后,Dropout就被BN替代了。
3. 由于GPU显存太小,使用了两个GPU,做法是在通道上分组。
4. 使用局部响应归一化(Local Response Normalization --LRN),在生物中存在侧抑制现象,即被激活的神经元会抑制周围的神经元。在这里的目的是让局部响应值大的变得相对更大,并抑制其它响应值相对比较小的卷积核。例如,某特征在这一个卷积核中响应值比较大,则在其它相邻卷积核中响应值会被抑制,这样一来卷积核之间的相关性会变小。LRN结合ReLU,使得模型提高了一点多个百分点。
5. 使用重叠池化。作者认为使用重叠池化会提升特征的丰富性,且相对来说会更难过拟合。
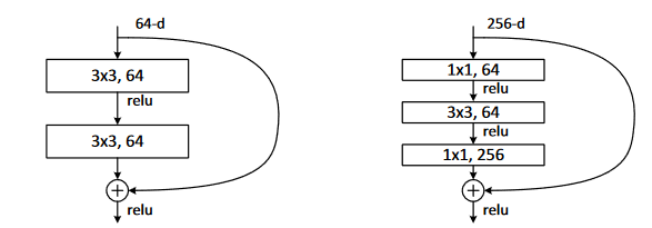
集大成之作,ResNet:
一般而言,网络越深越宽会有更好的特征提取能力,但当网络达到一定层数后,随着层数的增加反而导致准确率下降,网络收敛速度更慢。
传统的卷积网络在一个前向过程中每层只有一个连接,ResNet增加了残差连接从而增加了信息从一层到下一层的流动。FractalNets重复组合几个有不同卷积块数量的并行层序列,增加名义上的深度,却保持着网络前向传播短的路径。相类似的操作还有Stochastic depth和Highway Networks等。这些模型都显示一个共有的特征,缩短前面层与后面层的路径,其主要的目的都是为了增加不同层之间的信息流动。
02 后起之秀——Transformers
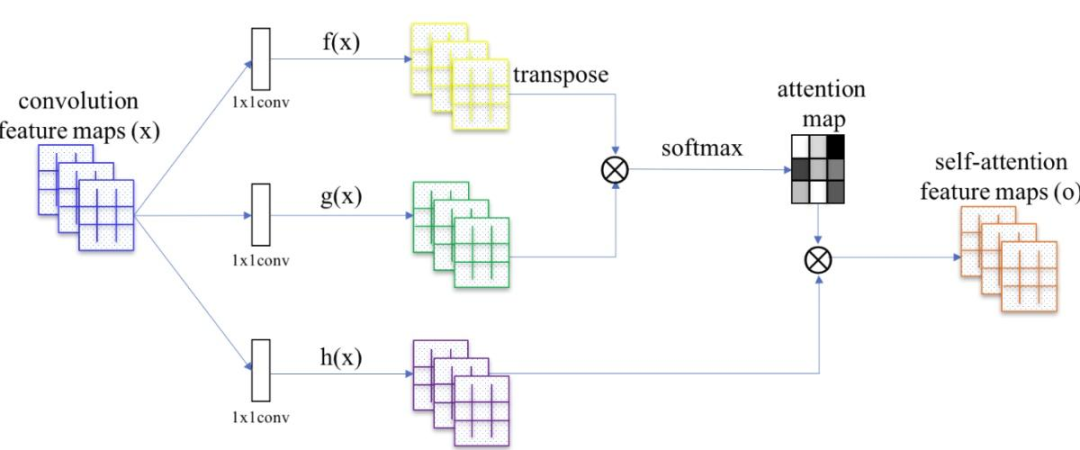
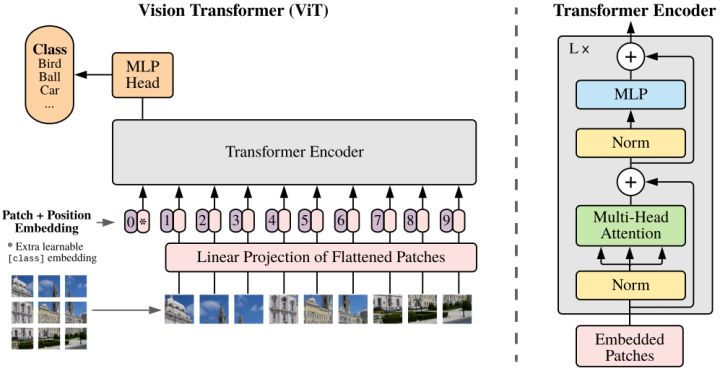
Transformer是一种self-attention(自注意力)模型架构,2017年之后在NLP领域取得了很大的成功,尤其是序列到序列(seq2seq)任务,如机器翻译和文本生成。2020年,谷歌提出pure transformer结构ViT ,在ImageNet分类任务上取得了和CNN可比的性能。之后大量ViT衍生的Transformer架构在ImageNet上都取得了成功。
Transformer 与 CNN相比优点是具有较少的归纳性与先验性,因此可以被认为是不同学习任务的通用计算原语,参数效率与性能增益与 CNN 相当。不过缺点是在预训练期间,对大数据机制的依赖性更强,因为 Transformer 没有像 CNN 那样定义明确的归纳先验。因此当下出现了一个新趋势:当 self-attention 与 CNN 结合时,它们会建立强大的基线 ( BoTNet )。
Vision Transformer(ViT)将纯Transformer架构直接应用到一系列图像块上进行分类任务,可以取得优异的结果。它在许多图像分类任务上也优于最先进的卷积网络,同时所需的预训练计算资源大大减少。
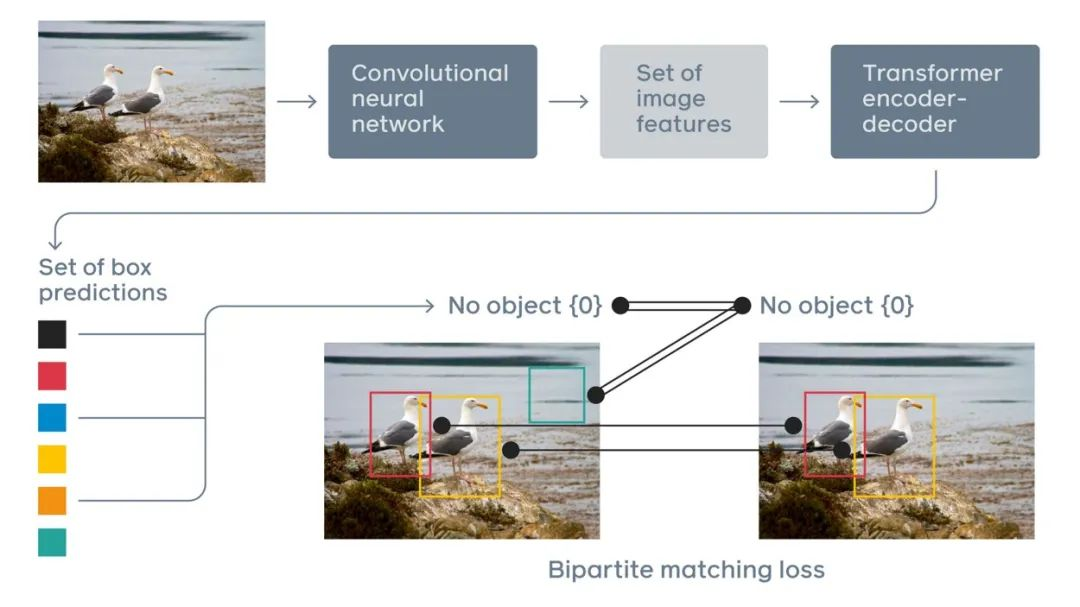
DETR是第一个成功地将Transformer作为pipeline中的主要构建块的目标检测框架。它与以前的SOTA方法(高度优化的Faster R-CNN)的性能匹配,具有更简单和更灵活的pipeline。
Transformer的变体模型是目前的研究热点,主要分为以下几个类型:1)模型轻量化;2)加强跨模块连接;3)自适应的计算时间;4)引入分而治之的策略;4)循环Transformers;5)等级化的Transformer。
03 欺骗机器的眼睛——对抗性示例
最近引起研究界注意的一个问题是这些系统对对抗样本的敏感性。一个对抗性的例子是一个嘈杂的图像,旨在欺骗系统做出错误的预测。为了在现实世界中部署这些系统,它们必须能够检测到这些示例。为此,最近的工作探索了通过在训练过程中包含对抗性示例来使这些系统更强大对抗对抗性攻击的可能性。
现阶段对模型攻击的分类主要分为两大类,即攻击训练阶段和推理阶段。
训练阶段的攻击 (Training in Adversarial Settings) ,主要的方法就是针对模型的参数进行微小的扰动,从让而达到让模型的性能和预期产生偏差的目的。例如直接通过对于训练数据的标签进行替换,让数据样本和标签不对应,从而最后训练的结果也一定与预期的产生差异,或者通过在线的方式获得训练数据的输入权,操纵恶意数据来对在线训练过程进行扰动,最后的结果就是产出脱离预期。
推理阶段的攻击 (Inference in Adversarial Settings),是当一个模型被训练完成后,可以将该模型主观的看作是一个盒子,如果该盒子对我们来说是透明的则可以将其看成“白盒”模型,若非如此则看成“黑盒”模型。所谓的“白盒攻击”,就是我们需要知道里面所有的模型参数,但这在实际操作中并不现实,却有实现的可能,因此我们需要有这种前提假设。黑盒攻击就比较符合现实生活中的场景:通过输入和输出猜测模型的内部结构;加入稍大的扰动来对模型进行攻击;构建影子模型来进行关系人攻击;抽取模型训练的敏感数据;模型逆向参数等等。
对抗攻击的防御机制。抵御对抗样本攻击主要是基于附加信息引入辅助块模型(AuxBlocks)进行额外输出来作为一种自集成的防御机制,尤其在针对攻击者的黑盒攻击和白盒攻击时,该机制效果良好。除此之外防御性蒸馏也可以起到一定的防御能力,防御性蒸馏是一种将训练好的模型迁移到结构更为简单的网络中,从而达到防御对抗攻击的效果。
对抗学习的应用举例,1)自动驾驶;2)金融欺诈。
自动驾驶是未来智能交通的发展方向,但在其安全性获得完全检验之前,人们还难以信任这种复杂的技术。虽然许多车企、科技公司已经在这一领域进行了许多实验,但对抗样本技术对于自动驾驶仍然是一个巨大的挑战。几个攻击实例:对抗攻击下的图片中的行人在模型的面前隐身,对抗样本使得模型“无视”路障;利用 AI 对抗样本生成特定图像并进行干扰时,特斯拉的 Autopilot 系统输出了「错误」的识别结果,导致车辆雨刷启动;在道路的特定位置贴上若干个对抗样本贴纸,可以让处在自动驾驶模式的汽车并入反向车道;在Autopilot 系统中,通过游戏手柄对车辆行驶方向进行控制;对抗样本使得行人对于机器学习模型“隐身”。
04 自学也能成才——自监督学习
深度学习需要干净的标记数据,这对于许多应用程序来说很难获得。注释大量数据需要大量的人力劳动,这是耗时且昂贵的。此外,数据分布在现实世界中一直在变化,这意味着模型必须不断地根据不断变化的数据进行训练。自监督方法通过使用大量原始未标记数据来训练模型来解决其中的一些挑战。在这种情况下,监督是由数据本身(不是人工注释)提供的,目标是完成一个间接任务。间接任务通常是启发式的(例如,旋转预测),其中输入和输出都来自未标记的数据。定义间接任务的目标是使模型能够学习相关特征,这些特征稍后可用于下游任务(通常有一些注释可用)。
自监督学习是一种数据高效的学习范式。监督学习方法教会模型擅长特定任务。另一方面,自监督学习允许学习不专门用于解决特定任务的一般表示,而是为各种下游任务封装更丰富的统计数据。在所有自监督方法中,使用对比学习进一步提高了提取特征的质量。自监督学习的数据效率特性使其有利于迁移学习应用。
目前的自监督学习领域可大致分为两个分支。一个是用于解决特定任务的自监督学习,例如上次讨论的场景去遮挡,以及自监督的深度估计、光流估计、图像关联点匹配等。另一个分支则用于表征学习。有监督的表征学习,一个典型的例子是ImageNet分类。而无监督的表征学习中,最主要的方法则是自监督学习。
自监督学习方法依赖于数据的空间和语义结构,对于图像,空间结构学习是极其重要的,因此在计算机视觉领域中的应用广泛。一种是将旋转、拼接和着色在内的不同技术被用作从图像中学习表征的前置任务。对于着色,将灰度照片作为输入并生成照片的彩色版本。另一种广泛用于计算机视觉自监督学习的方法是放置图像块。一个例子包括 Doersch 等人的论文。在这项工作中,提供了一个大型未标记的图像数据集,并从中提取了随机的图像块对。在初始步骤之后,卷积神经网络预测第二个图像块相对于第一个图像块的位置。还有其他不同的方法用于自监督学习,包括修复和判断分类错误的图像。
结语:
自2012年AlexNet问世这十年来,机器视觉领域的技术可以说是日新月异。机器视觉在诸多领域也逐渐接近甚至超越了我们人类的眼睛。随着技术的不断进步,机器视觉技术也一定会变得更加的强大,无论是安全防护、自动驾驶、缺陷检测还是目标识别等领域,相信机器视觉会带给我们更多的惊喜。
本文仅做学术分享,如有侵权,请联系删文。