
2022年最新版 | Flink经典线上问题小盘点

本文已经加入「大数据成神之路PDF版」中提供下载。
你可以关注公众号,后台回复:「PDF」 即可获取。
2020年和2021年分别写了很多篇类似的文章,这篇文章是关于Flink生产环境中遇到的各种问题的汇总。
这个版本在Flink新版本的基础上梳理了一个更加完整的版本。
新增了一些Flink CDC和大作业的启停已经数据缺失的问题。
如果你遇到过一些共性的问题,希望对你有帮助。本文参考了我在查问题中找到的网上的资源和一些博客。
如何规划生产中的集群大小?
第一步是仔细考虑应用程序的运维指标,以达到所需资源的基线。需要考虑的关键指标是:
每秒记录数和每条记录的大小 已有的不同键(key)的数量和每个键对应的状态大小 状态更新的次数和状态后端的访问模式
最后,一个更实际的问题是与客户之间围绕停机时间、延迟和最大吞吐量的服务级别协议(SLA),因为这些直接影响容量规划。接下来,根据预算,看看有什么可用的资源。例如:
网络容量,同时把使用网络的外部服务也纳入考虑,如 Kafka、HDFS 等。 磁盘带宽,如果您依赖于基于磁盘的状态后端,如 RocksDB(并考虑其他磁
盘使用,如 Kafka 或 HDFS)可用的机器数量、CPU 和内存
Flink CheckPoint问题如何排查?
Flink 的 Checkpoint 包括如下几个部分:
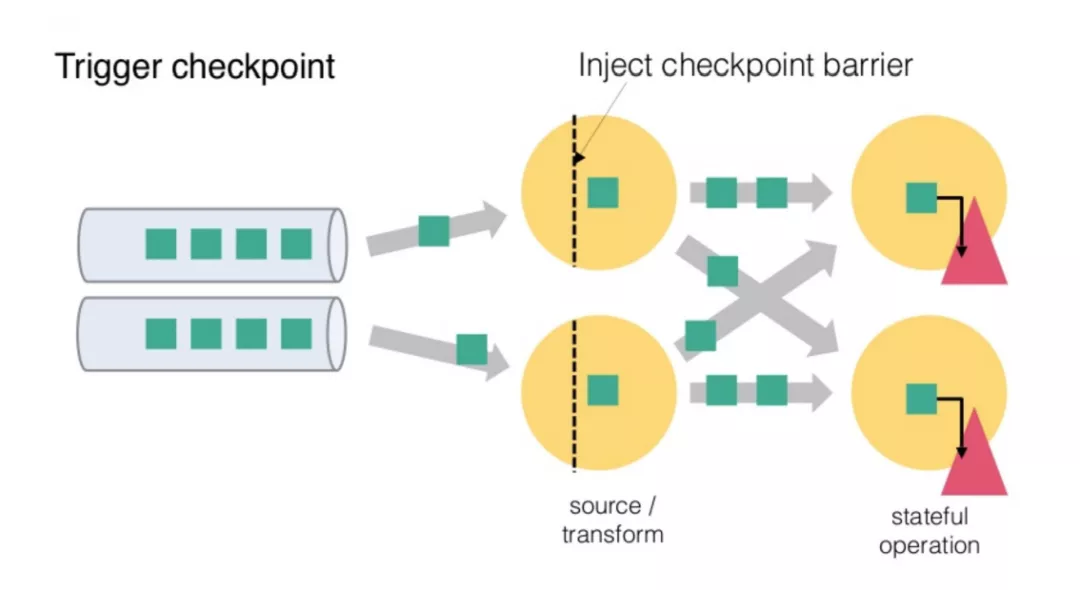
JM trigger checkpoint Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier 下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint) Task 开始同步阶段 snapshot Task 开始异步阶段 snapshot Task snapshot 完成,汇报给 JM
上面的任何一个步骤不成功,整个 checkpoint 都会失败。
Checkpoint问题可以分为下面几个大类:
Checkpoint失败
假如我们在 Checkpoint 界面看到如下图所示,下图中 Checkpoint 10423 失败了。点击Checkpoint10423 的详情,我们可以看到类系下图所示的表格。

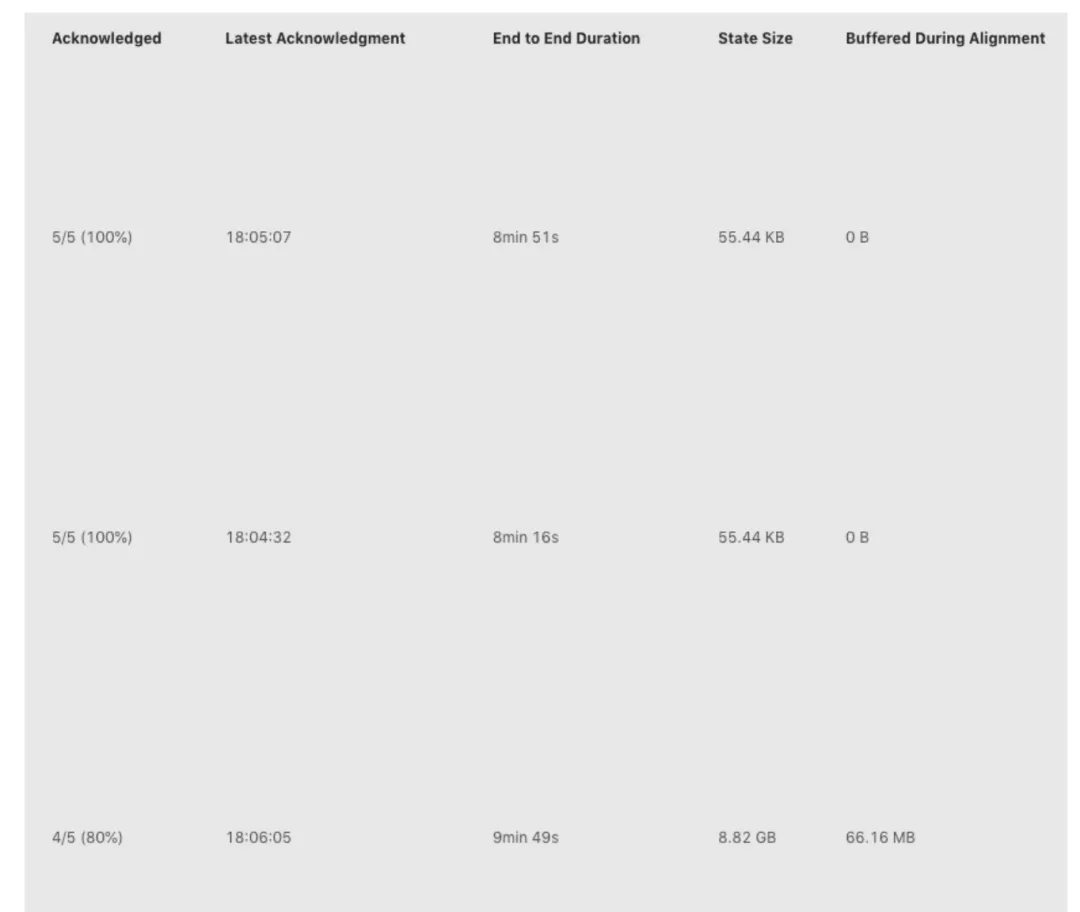
Checkpoint 失败大致分为两种情况:Checkpoint Decline 和 CheckpointExpire。
Checkpoint Decline发生时我们可以在日志汇总发现类似下面这样的日志:
Decline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178. 其中 10423 是 checkpointID,0b60f08bf8984085b59f8d9bc74ce2e1 是 execution id,85d268e6fbc19411185f7e4868a44178 是 job id,我们可以在 jobmanager.log 中查找 execution id,找到被调度到哪个 taskmanager 上,类似如下所示:
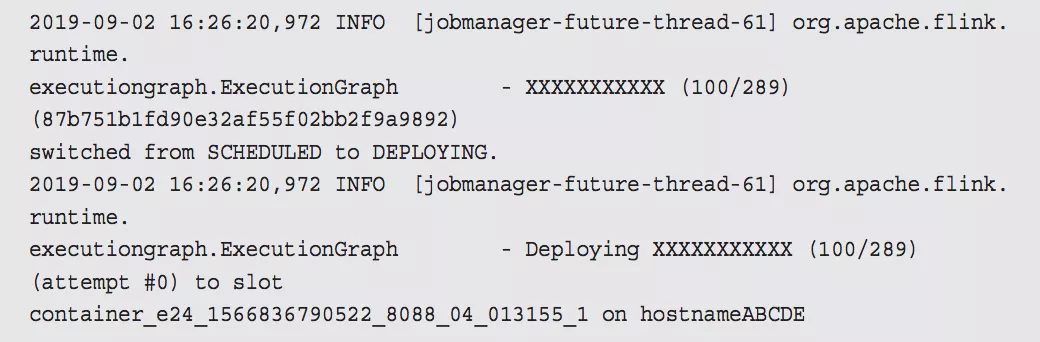
从上面的日志我们知道该 execution 被调度到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot 上,接下来我们就可以到 container container_e24_1566836790522_8088_04_013155 的 taskmanager.log 中查找Checkpoint 失败的具体原因了。
Checkpoint Expire
如果 Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。当一个 Checkpoint 由于超时而失败是,会在 jobmanager.log 中看到如下的日志:
Checkpoint 1 of job 85d268e6fbc19411185f7e4868a44178 expired before completing.
表示 Chekpoint 1 由于超时而失败,这个时候可以可以看这个日志后面是否有类似下面的日志:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
我们就可以按照上面的方法找到对应的 taskmanager.log 查看具体信息。
Checkpoint 慢
Checkpoint 慢的情况如下:比如 Checkpoint interval 1 分钟,超时 10 分钟,Checkpoint 经常需要做 9 分钟(我们希望 1 分钟左右就能够做完),而且我们预期
state size 不是非常大。对于 Checkpoint 慢的情况,我们可以按照下面的顺序逐一检查。
Source Trigger Checkpoint 慢 使用增量 Checkpoint 作业存在反压或者数据倾斜 Barrier 对齐慢 主线程太忙,导致没机会做 snapshot 同步阶段做的慢 异步阶段做的慢
反压问题如何排查?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。由于实时计算应用通常使用消息队列来进行生产端和消费端的解耦,消费端数据源是 pull-based 的,所以反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。
要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法 :
通过 Flink Web UI 自带的反压监控面板 通过 Flink Task Metrics
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,原理是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为OK,0.1 至 0.5 为 LOW,而超过 0.5 则为 HIGH。
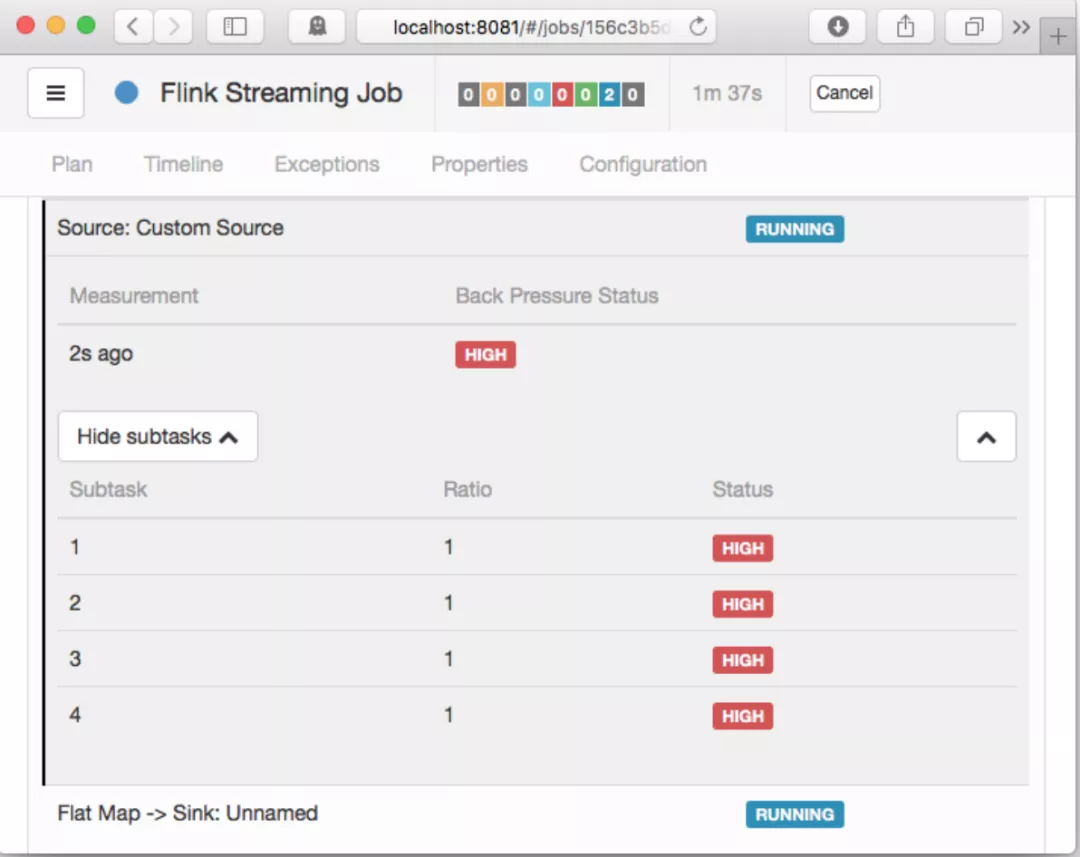
如果处于反压状态,那么有两种可能性:
该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条
输出的 Operator(比如 flatmap)。下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。
如果是第一种状况,那么该节点则为反压的根源节点,它是从 Source Task 到Sink Task 的第一个出现反压的节点。如果是第二种情况,则需要继续排查下游节点。
值得注意的是,反压的根源节点并不一定会在反压面板体现出高反压,因为反压面板监控的是发送端,如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。总体来看,如果我们找到第一个出现反压的节点,那么反压根源要么是就这个节点,要么是它紧接着的下游节点。
此外,Flink 提供的 Task Metrics 是更好的反压监控手段,我们在监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics:

分析反压的大致思路是:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。反压情况可以根据以下表格进行对号入座:
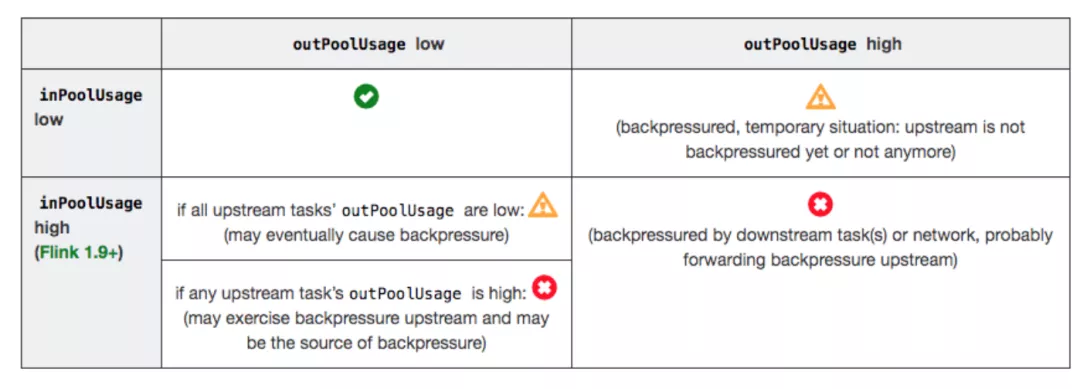
outPoolUsage 和 inPoolUsage 同为低或同为高分别表明当前 Subtask 正常或处于被下游反压,这应该没有太多疑问。而比较有趣的是当 outPoolUsage 和
inPoolUsage 表现不同时,这可能是出于反压传导的中间状态或者表明该 Subtask就是反压的根源。
如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高,我们可以根据这点来进一步判断。值得注意的是,反压有时是短暂的且影响不大,比如来自某个 Channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下我们可以不用处理。
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
此外,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题)。最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到Task Thread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面,比如我们生产环境中就偶尔遇到卡在 Regex 的用户函数(ReDoS);如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
另外 TaskManager 的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。推荐可以通过给TaskManager 启用 G1 垃圾回收器来优化 GC,并加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。
客户端常见问题
应用提交控制台异常信息:Could not build the program from JAR file.
这个问题的迷惑性较大,很多时候并非指定运行的 JAR 文件问题,而是提交过程中发生了异常,需要根据日志信息进一步排查。最常见原因是未将依赖的 Hadoop JAR 文件加到 CLASSPATH,找不到依赖类(例如:ClassNotFoundException:org.apache.hadoop.yarn.exceptions.YarnException)导致加载客户端入口类(FlinkYarnSessionCli)失败。
用户应用和框架 JAR 包版本冲突问题
该问题通常会抛出 NoSuchMethodError/ClassNotFoundException/IncompatibleClassChangeError 等异常,要解决此类问题:
首先需要根据异常类定位依赖库,然后可以在项目中执行 mvn dependency:tree 以树形结构展示全部依赖链,再从中定位冲突的依赖库,也可以增加参数 -Dincludes 指定要显示的包,格式为 [groupId]:[artifactId]:[-type]:[version],支持匹配,多个用逗号分隔,例如:mvn dependency:tree-Dincludes=power,javaassist。 定位冲突包后就要考虑如何排包,简单的方案是用 exclusion 来排除掉其从他依赖项目中传递过来的依赖,不过有的应用场景需要多版本共存,不同组件依赖不同版本,就要考虑用 Maven Shade 插件来解决,详情请参考Maven Shade Plugin。
Flink 应用资源分配问题排查思路
如果 Flink 应用不能正常启动达到 RUNNING 状态,可以按以下步骤进行排查:
步骤1. 需要先检查应用当前状态,根据上述对启动流程的说明,我们知道:
处于 NEW_SAVING 状态时正在进行应用信息持久化,如果持续处于这个状态我们需要检查 RM 状态存储服务(通常是 ZooKeeper 集群)是否正常; 如果处于 SUBMITTED 状态,可能是 RM 内部发生一些 hold 读写锁的耗时操作导致事件堆积,需要根据 YARN 集群日志进一步定位. 如果处于 ACCEPTED 状态,需要先检查 AM 是否正常,跳转到步骤 2; 如果已经是 RUNNING 状态,但是资源没有全部拿到导致 JOB 无法正常运行,跳转到步骤 3;
步骤2. 检查 AM 是否正常,可以从 YARN 应用展示界面(http:// /cluster/app/)或YARN 应用 REST API(http:///ws/v1/cluster/apps/)查看 diagnostics 信
息,根据关键字信息明确问题原因与解决方案:
Queue’s AM resource limit exceeded. 原因是达到了队列 AM 可用资源上限,即队列的 AM 已使用资源和 AM 新申请资源之和超出了队列的AM 资源上限,可以适当调整队列 AM 可用资源百分比的配置项:yarn.scheduler.capacity..maximum-am-resource-percent。 User’s AM resource limit exceeded. 原因是达到了应用所属用户在该队列的 AM 可用资源上限,即应用所属用户在该队列的 AM 已使用资源和 AM新申请资源之和超出了应用所属用户在该队列的 AM 资源上限,可以适当提高用户可用 AM 资源比例来解决该问题,相关配置项:yarn.scheduler.capacity..user-limit-factor 与 yarn.scheduler.capacity..minimum-user-limit-percent。 AM container is launched, waiting for AM container to Register with RM. 大致原因是 AM 已启动,但内部初始化未完成,可能有 ZK 连接超时等问题,具体原因需排查 AM 日志,根据具体问题来解决。 Application is Activated, waiting for resources to be assigned for AM.该信息表示应用 AM 检查已经通过,正在等待调度器分配,此时需要进行调度器层面的资源检查,跳转到步骤 4。
步骤3. 确认应用确实有 YARN 未能满足的资源请求:从应用列表页点击问题应用ID 进入应用页面,再点击下方列表的应用实例 ID 进入应用实例页面,看
Total Outstanding Resource Requests 列表中是否有 Pending 资源,如果没有,说明 YARN 已分配完毕,退出该检查流程,转去检查 AM;如果有,说明调度器未能完成分配,跳转到步骤 4。
步骤4.调度器分配问题排查YARN-9050 支持在 WebUI 上或通过 REST API 自动诊断应用问题,将在 Hadoop3.3.0 发布,之前的版本仍需进行人工排查:
检查集群或 queue 资源,scheduler 页面树状图叶子队列展开查看资源信息:Effective Max Resource、Used Resources:(1)检查集群资源或所在队列资源或其父队列资源是否已用完;(2)检查叶子队列某维度资源是否接近或达到上限;
检查是否存在资源碎片:(1)检查集群 Used 资源和 Reserved 资源之和占总资源的比例,当集群资源接近用满时(例如 90% 以上),可能存在资源碎片的情况,应用的分配速度就会受影响变慢,因为大部分机器都没有资源了,机器可用资源不足会被 reserve,reserved 资源达到一定规模后可能导致大部分机器资源被锁定,后续分配可能就会变慢;(2)检查 NM 可用资源分布情况,即使集群资源使用率不高,也有可能是因为各维度资源分布不同造成,例如 1/2 节点上的内存资源接近用满 CPU 资源剩余较多,1/2 节点上的 CPU 资源接近用满内存资源剩余较多,申请资源中某一维度资源值配置过大也可能造成无法申请到资源;
检查是否有高优先级的问题应用频繁申请并立即释放资源的问题,这种情况会造成调度器忙于满足这一个应用的资源请求而无暇顾及其他应用;
检查是否存在 Container 启动失败或刚启动就自动退出的情况,可以查看Container 日志 ( 包括 localize 日志、launch 日志等 )、YARN NM 日志或YARN RM 日志进行排查。
TaskManager 启动异常
org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container. This token is expired. current time is ... found ...
该异常在 Flink AM 向 YARN NM 申请启动 token 已超时的 Container 时抛出,通常原因是 Flink AM 从 YARN RM 收到这个 Container 很久之后(超过了Container 有效时间,默认 10 分钟,该 Container 已经被释放)才去启动它,进一步原因是 Flink 内部在收到 YARN RM 返回的 Container 资源后串行启动。
当待启动的 Container 数量较多且分布式文件存储如 HDFS 性能较慢(启动前需上传 TaskManager配置)时 Container启动请求容易堆积在内部,FLINK-13184 对这个问题进行了优化,一是在启动前增加了有效性检查,避免了无意义的配置上传流程,二是进行了异步多线程优化,加快启动速度。
PyFlink如何定义UDF
在 Apache Flink 1.10 中我们有多种方式进行 UDF 的定义,比如:
Extend ScalarFunction, e.g.:
class HashCodeMean(ScalarFunction):
def eval(self, i, j):
return (hash(i) + hash(j)) / 2
Lambda Functio
lambda i, j: (hash(i) + hash(j)) / 2
Named Function
def hash_code_mean(i, j):
return (hash(i) + hash(j)) / 2
Callable Function
class CallableHashCodeMean(object):
def __call__(self, i, j):
return (hash(i) + hash(j)) / 2
现上面定义函数除了第一个扩展 ScalaFunction 的方式是 PyFlink 特有的,其他方式都是 Python 语言本身就支持的,也就是说,在 Apache Flink 1.10中PyFlink 允许以任何 Python 语言所支持的方式定义 UDF。
那么定义完 UDF 我们应该怎样使用呢?Apache Flink 1.10 中提供了2种Decorators,如下:
Decorators - udf(), e.g. :
udf(lambda i, j: (hash(i) + hash(j)) / 2,
[for input types], [for result types])
Decorators - @udf, e.g. :
@udf(input_types=..., result_type=...)
def hash_code_mean(…):
然后在使用之前进行注册,如下:
st_env.register_function("hash_code", hash_code_mean)
接下来就可以在 Table API/SQL 中进行使用了,如下:
my_table.select("hash_code_mean(a, b)").insert_into("Results")
数据倾斜导致子任务积压
业务背景
一个流程中,有两个重要子任务:一是数据迁移,将kafka实时数据落Es,二是将kafka数据做窗口聚合落hbase,两个子任务接的是同一个Topic GroupId。上游 Topic 的 tps 高峰达到5-6w。
问题描述
给 24个 TaskManager(CPU) 都会出现来不及消费的情况
问题原因
做窗口聚合的任务的分组字段,分组粒度太小,hash不能打散,数据倾斜严重,导致少数 TaskManager 上压力过大,从而影响落Es的效率,导致背压。
解决方式
将两个任务独立开来,作为不同的流程。
结果
修改之前 24个 TaskManager(CPU) 来不及消费,改完之后 20 个 CPU 可完成任务。Kafka实时数据落Es的16个TaskManager,将kafka数据做窗口聚合落hbase的4个TaskManager。
另:
同样的数据、同样的Tps作为数据输入,Hbase的输出能力远超过Es,考虑实时任务落数据进Es要慎重。
Flink任务落Es时要考虑设置微批落数据,设置 bulk.flush.max.actions 和 bulk.flush.interval.ms至合适值,否则影响吞吐量。
Kafka 消息大小默认配置太小,导致数据未处理
业务背景
正常的Flink任务消费 Topic 数据,但是Topic中的数据为 XML 以及 JSON,单条数据较大
问题描述
Flink各项metrics指标正常,但是没处理到数据
问题原因
Topic中单条数据 > 1M,超过 Kafka Consumer 处理单条数据的默认最大值。
解决方式
有三种可选方式:扩大kafka consumer 单条数据的数据大小:fetch.message.max.bytes。对消息进行压缩:上游 kafka producer 设置 compression.codec 和 commpressed.topics。业务上对数据切片,在上游 kafka producer 端将数据切片为 10K,使用分区主键确保同一条数据发送到同一Partition,consumer对消息重组。
结果
方式一:按业务要求扩大 Kafka Consumer 可处理的单条数据字节数即可正常处理业务
方式二:Kafka Consumer 需先解码,再进行业务处理。方式三:Kafka Consumer 需先重组数据,再进行业务处理。
Tps 很大,Kafka Ack 默认配置 拖慢消息处理速度
业务背景
实时任务,上游接流量页面点击事件的数据,下游输出Kafka,输出tps很大。流量数据不重要,可接受丢失的情况
问题描述
CPU资源耗费较多的情况下,才能正常消费,考虑如果缩减资源。
问题原因
Kafka Producer 默认 acks=1,即Partition Leader接收到消息而且写入本地磁盘了,就认为成功了
解决方式
Kafka Producer 设置 :props.put(“acks”, “0”);
将 acks=0,即KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,直接就认为这个消息发送成功了。
结果
资源降低三分之一。
The assigned slot container_e08_1539148828017_15937_01_003564_0 was removed.
org.apache.flink.util.FlinkException: The assigned slot container_e08_1539148828017_15937_01_003564_0 was removed.
at org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:786)
at org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:756)
at org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:948)
at org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:372)
at org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:803)
at org.apache.flink.yarn.YarnResourceManager.lambda0(YarnResourceManager.java:340)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:332)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:158)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:70)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:142)
程序内存占用过大,导致TaskManager在yarn上kill了,分析原因应该是资源不够,可以将程序放在资源更大的集群上,再不行就设置减少Slot中共享的task的个数,也可能是内存泄露或内存资源配置不合理造成,需要进行合理分配。
The heartbeat of TaskManager with id container ....... timed out
此错误是container心跳超时,出现此种错误一般有两种可能:
1、分布式物理机网络失联,这种原因一般情况下failover后作业能正常恢复,如果出现的不频繁可以不用关注;2、failover的节点对应TM的内存设置太小,GC严重导致心跳超时,建议调大对应节点的内存值。
Caused by: java.util.concurrent.CompletionException: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@flink88:15265/user/taskmanager_0#6643546564]] after [10000 ms]. Sender[null] sent message of type "org.apache.flink.runtime.rpc.messages.RemoteRpcInvocation".
在flink-conf.yaml中添加或修改:akka.ask.timeout: 100s
web.timeout: 100000
Checkpoint:Checkpoint expired before completing
checkpointConf.setCheckpointTimeout(5000L)这个值设置过小,默认是10min,需要进行调大测试。
Kafka partition leader切换导致Flink重启
Flink重启,查看日志,显示:
java.lang.Exception: Failed to send data to Kafka: This server is not the leader for that topic-partition.
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.checkErroneous(FlinkKafkaProducerBase.java:373)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.invoke(FlinkKafkaProducerBase.java:280)
at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:41)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:206)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:263)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:702)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
查看Kafka的Controller日志,显示:
INFO [SessionExpirationListener on 10], ZK expired; shut down all controller components and
try to re-elect (kafka.controller.KafkaController$SessionExpirationListener)
关于producer参数设置,设置retries参数,可以在Kafka的Partition发生leader切换时,Flink不重启,而是做3次尝试:
kafkaProducerConfig
{
"bootstrap.servers": "192.169.2.20:9093,192.169.2.21:9093,192.169.2.22:9093"
"retries":3
}
注意 mapWithState & TTL 的重要性
在处理包含无限多键的数据时,要考虑到 keyed 状态保留策略(通过 TTL 定时器来在给定的时间之后清理未使用的数据)是很重要的。术语『无限』在这里有点误导,因为如果你要处理的 key 以 128 位编码,则 key 的最大数量将会有个限制(等于 2 的 128 次方)。但这是一个巨大的数字!你可能无法在状态中存储那么多值,所以最好考虑你的键空间是无界的,同时新键会随着时间不断出现。
如果你的 keyed 状态包含在某个 Flink 的默认窗口中,则将是安全的:即使未使用 TTL,在处理窗口的元素时也会注册一个清除计时器,该计时器将调用 clearAllState 函数,并删除与该窗口关联的状态及其元数据。
如果要使用 Keyed State Descriptor 来管理状态,可以很方便地添加 TTL 配置,以确保在状态中的键数量不会无限制地增加。
但是,你可能会想使用更简便的 mapWithState 方法,该方法可让你访问 valueState 并隐藏操作的复杂性。虽然这对于测试和少量键的数据来说是很好的选择,但如果在生产环境中遇到无限多键值时,会引发问题。由于状态是对你隐藏的,因此你无法设置 TTL,并且默认情况下未配置任何 TTL。这就是为什么值得考虑做一些额外工作的原因,如声明诸如 RichMapFunction 之类的东西,这将使你能更好的控制状态的生命周期。
部署和资源问题
(0) JDK版本过低
这不是个显式错误,但是JDK版本过低很有可能会导致Flink作业出现各种莫名其妙的问题,因此在生产环境中建议采用JDK 8的较高update(我们使用的是181)。
(1) Could not build the program from JAR file
该信息不甚准确,因为绝大多数情况下都不是JAR包本身有毛病,而是在作业提交过程中出现异常退出了。因此需要查看本次提交产生的客户端日志(默认位于$FLINK_HOME/logs目录下),再根据其中的信息定位并解决问题。
(2) ClassNotFoundException/NoSuchMethodError/IncompatibleClassChangeError/...
一般都是因为用户依赖第三方包的版本与Flink框架依赖的版本有冲突导致。
(3) Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
就是字面意思,YARN集群内没有足够的资源启动Flink作业。检查一下当前YARN集群的状态、正在运行的YARN App以及Flink作业所处的队列,释放一些资源或者加入新的资源。
(4) java.util.concurrent.TimeoutException: Slot allocation request timed out
slot分配请求超时,是因为TaskManager申请资源时无法正常获得,按照上一条的思路检查即可。
(5) org.apache.flink.util.FlinkException: The assigned slot < container_id> was removed
TaskManager的Container因为使用资源超限被kill掉了。首先需要保证每个slot分配到的内存量足够,特殊情况下可以手动配置SlotSharingGroup来减少单个slot中共享Task的数量。如果资源没问题,那么多半就是程序内部发生了内存泄露。建议仔细查看TaskManager日志,并按处理JVM OOM问题的常规操作来排查。
(6) java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id < tm_id>timed out
TaskManager心跳超时。有可能是TaskManager已经失败,如果没有失败,那么有可能是因为网络不好导致JobManager没能收到心跳信号,或者TaskManager忙于GC,无法发送心跳信号。JobManager会重启心跳超时的TaskManager,如果频繁出现此异常,应该通过日志进一步定位问题所在。
在Flink中,资源的隔离是通过Slot进行的,也就是说多个Slot会运行在同一个JVM中,这种隔离很弱,尤其对于生产环境。Flink App上线之前要在一个单独的Flink集群上进行测试,否则一个不稳定、存在问题的Flink App上线,很可能影响整个Flink集群上的App。
(7)资源不足导致 container 被 kill
The assigned slot container_container编号 was removed.Flink App 抛出此类异常,通过查看日志,一般就是某一个 Flink App 内存占用大,导致 TaskManager(在 Yarn 上就是 Container )被Kill 掉。
但是并不是所有的情况都是这个原因,还需要进一步看 yarn 的日志( 查看 yarn 任务日志:yarn logs -applicationId -appOwner),如果代码写的没问题,就确实是资源不够了,其实 1G Slot 跑多个Task( Slot Group Share )其实挺容易出现的。
因此有两种选择,可以根据具体情况,权衡选择一个。
将该 Flink App 调度在 Per Slot 内存更大的集群上。通过 slotSharingGroup("xxx") ,减少 Slot 中共享 Task 的个数
(8)启动报错,提示找不到 jersey 的类
java.lang.NoClassDefFoundError: com/sun/jersey/core/util/FeaturesAndProperties
解决办法进入 yarn中 把 lib 目中的一下两个问价拷贝到flink的lib中
hadoop/share/hadoop/yarn/lib/jersey-client-1.9.jar /hadoop/share/hadoop/yarn/lib/jersey-core-1.9.jar
(9)Scala版本冲突
java.lang.NoSuchMethodError:scala.collection.immutable.HashSet$.empty()Lscala/collection/
解决办法,添加:
import org.apache.flink.api.scala._
(10)没有使用回撤流报错
Table is not an append一only table. Use the toRetractStream() in order to handle add and retract messages.
这个是因为动态表不是 append-only 模式的,需要用 toRetractStream (回撤流) 处理就好了.
tableEnv.toRetractStream[Person](result).print()
(11)OOM 问题解决思路
java.lang.OutOfMemoryError: GC overhead limit exceeded
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.(String.java:207)
at com.esotericsoftware.kryo.io.Input.readString(Input.java:466)
at com.esotericsoftware.kryo.serializers.DefaultSerializers$StringSerializer.read(DefaultSerializers.java:177)
......
at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:524)
解决方案:
检查 slot 槽位够不够或者 slot 分配的数量有没有生效。程序起的并行是否都正常分配了(会有这样的情况出现,假如 5 个并行,但是只有 2 个在几点上生效了,另外 3 个没有数据流动)。检查flink程序有没有数据倾斜,可以通过 flink 的 ui 界面查看每个分区子节点处理的数据量。
(12)解析返回值类型失败报错
The return type of function could not be determined automatically
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(RemoteEnvironmentTest.java:27)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.java.DataSet.getType(DataSet.java:178)
at org.apache.flink.api.java.DataSet.collect(DataSet.java:410)
at org.apache.flink.api.java.DataSet.print(DataSet.java:1652)
解决方案:产生这种现象的原因一般是使用 lambda 表达式没有明确返回值类型,或者使用特使的数据结构 flink 无法解析其类型,这时候我们需要在方法的后面添加返回值类型,比如字符串。
input.flatMap((Integer number, Collector< String> out) -> {
......
})
// 提供返回值类型
.returns(Types.STRING)
(13)Hadoop jar 包冲突
Caused by: java.io.IOException: The given file system URI (hdfs:///data/checkpoint-data/abtest) did not describe the authority (like for example HDFS NameNode address/port or S3 host). The attempt to use a configured default authority failed: Hadoop configuration did not contain an entry for the default file system ('fs.defaultFS').
at org.apache.flink.runtime.fs.hdfs.HadoopFsFactory.create(HadoopFsFactory.java:135)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:399)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:318)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:298)
解决:pom 文件中去掉和 hadoop 相关的依赖就好了
作业问题
(1)org.apache.flink.streaming.runtime.tasks.ExceptionInChainedOperatorException: Could not forward element to next operator
该异常几乎都是由于程序业务逻辑有误,或者数据流里存在未处理好的脏数据导致的,继续向下追溯异常栈一般就可以看到具体的出错原因,比较常见的如POJO内有空字段,或者抽取事件时间的时间戳为null等。
(2) java.lang.IllegalStateException: Buffer pool is destroyed || Memory manager has been shut down
很多童鞋拿着这两条异常信息来求助,但实际上它们只是表示BufferPool、MemoryManager这些Flink运行时组件被销毁,亦即作业已经失败。具体的原因多种多样,根据经验,一般是上一条描述的情况居多(即Could not forward element to next operator错误会伴随出现),其次是JDK版本问题。具体情况还是要根据TaskManager日志具体分析。
(3) akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka://...]] after [10000 ms]
Akka超时导致,一般有两种原因:一是集群负载比较大或者网络比较拥塞,二是业务逻辑同步调用耗时的外部服务。如果负载或网络问题无法彻底缓解,需考虑调大akka.ask.timeout参数的值(默认只有10秒);另外,调用外部服务时尽量异步操作(Async I/O)。
(4) java.io.IOException: Too many open files
这个异常我们应该都不陌生,首先检查系统ulimit -n的文件描述符限制,再注意检查程序内是否有资源(如各种连接池的连接)未及时释放。值得注意的是,Flink使用RocksDB状态后端也有可能会抛出这个异常,此时需修改flink-conf.yaml中的state.backend.rocksdb.files.open参数,如果不限制,可以改为-1。
(5) org.apache.flink.api.common.function.InvalidTypesException: The generic type parameters of '< class>' are missing
在Flink内使用Java Lambda表达式时,由于类型擦除造成的副作用,注意调用returns()方法指定被擦除的类型。
(6)Checkpoint失败:Checkpoint expired before completing
原因是因为checkpointConf.setCheckpointTimeout(8000L)。设置的太小了,默认是10min,这里只设置了8sec。当一个Flink App背压的时候(例如由外部组件异常引起),Barrier会流动的非常缓慢,导致Checkpoint时长飙升。
检查点和状态问题
(1) Received checkpoint barrier for checkpoint < cp_id> before completing current checkpoint < cp_id>. Skipping current checkpoint
在当前检查点还未做完时,收到了更新的检查点的barrier,表示当前检查点不再需要而被取消掉,一般不需要特殊处理。
(2) Checkpoint < cp_id> expired before completing
首先应检查CheckpointConfig.setCheckpointTimeout()方法设定的检查点超时,如果设的太短,适当改长一点。另外就是考虑发生了反压或数据倾斜,或者barrier对齐太慢。
(3) org.apache.flink.util.StateMigrationException: The new state serializer cannot be incompatible
我们知道Flink的状态是按key组织并保存的,如果程序逻辑内改了keyBy()逻辑或者key的序列化逻辑,就会导致检查点/保存点的数据无法正确恢复。所以如果必须要改key相关的东西,就弃用之前的状态数据吧。
(4) org.apache.flink.util.StateMigrationException: The new serializer for a MapState requires state migration in order for the job to proceed. However, migration for MapState currently isn't supported
在1.9之前的Flink版本中,如果我们使用RocksDB状态后端,并且更改了自用MapState的schema,恢复作业时会抛出此异常,表示不支持更改schema。这个问题已经在FLINK-11947解决,升级版本即可。
(5)时钟不同步导致无法启动
启动Flink任务的时候报错
Caused by: java.lang.RuntimeException: Couldn't deploy Yarn cluster。
然后仔细看发现:system times on machines may be out of sync。
意思说是机器上的系统时间可能不同步。同步集群机器时间即可。
不同的kafka版本依赖冲突
不同的kafka版本依赖冲突会造成cdc报错,参考这个issue:
http://apache-flink.147419.n8.nabble.com/cdc-td8357.html#a8393
2020-11-04 16:39:10.972 [Source: Custom Source -> Sink: Print to Std. Out (1/1)] WARN org.apache.flink.runtime.taskmanager.Task - Source: Custom Source -> Sink: Print to Std. Out (1/1) (7c3ccf7686ccfb33254e8cb785cd339d) switched from RUNNING to FAILED.
java.lang.AbstractMethodError: org.apache.kafka.connect.json.JsonSerializer.configure(Ljava/util/Map;Z)V
at org.apache.kafka.connect.json.JsonConverter.configure(JsonConverter.java:300)
at org.apache.kafka.connect.json.JsonConverter.configure(JsonConverter.java:311)
at io.debezium.embedded.EmbeddedEngine.(EmbeddedEngine.java:583)
at io.debezium.embedded.EmbeddedEngine.(EmbeddedEngine.java:80)
at io.debezium.embedded.EmbeddedEngine$BuilderImpl.build(EmbeddedEngine.java:301)
at io.debezium.embedded.EmbeddedEngine$BuilderImpl.build(EmbeddedEngine.java:217)
at io.debezium.embedded.ConvertingEngineBuilder.build(ConvertingEngineBuilder.java:139)
at com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction.run(DebeziumSourceFunction.java:299)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:213)
源码如下:
public class CdcTest {
public static void main(String[] args) throws Exception {
SourceFunction sourceFunction = MySQLSource.builder()
.hostname("localhost")
.port(3306)
.databaseList("sohay") // monitor all tables under inventory database
.username("root")
.password("123456")
.deserializer(new StringDebeziumDeserializationSchema()) // converts SourceRecord to String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(sourceFunction).print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute();
}
}
确实是pom中存在一个Kafka的依赖包,导致冲突,去掉后问题解决。
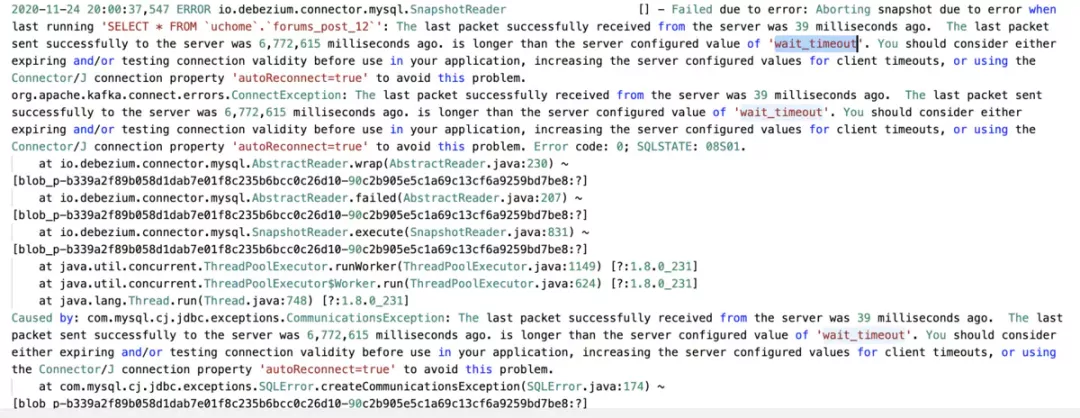
MySQL CDC源等待超时
在扫描表期间,由于没有可恢复的位置,因此无法执行checkpoints。为了不执行检查点,MySQL CDC源将保持检查点等待超时。超时检查点将被识别为失败的检查点,默认情况下,这将触发Flink作业的故障转移。因此,如果数据库表很大,则建议添加以下Flink配置,以避免由于超时检查点而导致故障转移:
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
数据库切换,重新开启binlog,Mysql全局锁无法释放

原因是因为切换了数据库环境,重新开启binlog,所有的作业都重新同步binlog的全量数据,导致了全局锁一直在等待,所有作业都无法执行。解决方法:记录checkpoint的地址,取消作业,然后根据checkpoint重启作业。
使用Flink SQL CDC模式创建维表异常
CREATE TABLE cdc_test
(
id STRING,
ip STRING,
url STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'database-name' = 'xx',
'table-name' = 'xx',
'username' = 'xx',
'password' = 'xx'
);
执行查询:
SELECT * FROM cdc_test;
任务无法运行,抛出异常
User does not have the 'LOCK TABLES' privilege required to obtain a consistent snapshot by preventing concurrent writes to tables.
原因是连接MySQL的用户缺乏必要的CDC权限。
Flink SQL CDC基于Debezium实现。当启动MySQL CDC源时,它将获取一个全局读取锁(FLUSH TABLES WITH READ LOCK),该锁将阻止其他数据库的写入,然后读取当前binlog位置以及数据库和表的schema,之后将释放全局读取锁。然后它扫描数据库表并从先前记录的位置读取binlog,Flink将定期执行checkpoints以记录binlog位置。如果发生故障,作业将重新启动并从checkpoint完成的binlog位置恢复,因此它保证了仅一次的语义。
解决办法:创建一个新的MySQL用户并授予其必要的权限。
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
mysql> FLUSH PRIVILEGES;
Flink作业扫描MySQL全量数据出现fail-over
Flink 作业在扫描 MySQL 全量数据时,checkpoint 超时,出现作业 failover,如下图:
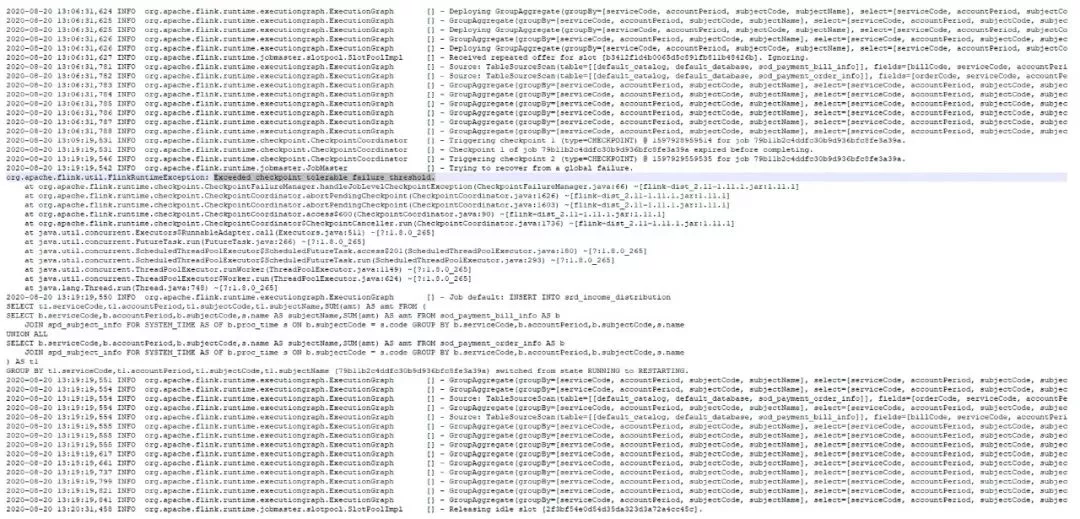
原因:Flink CDC 在 scan 全表数据(我们的实收表有千万级数据)需要小时级的时间(受下游聚合反压影响),而在 scan 全表过程中是没有 offset 可以记录的(意味着没法做 checkpoint),但是 Flink 框架任何时候都会按照固定间隔时间做 checkpoint,所以此处 mysql-cdc source 做了比较取巧的方式,即在 scan 全表的过程中,会让执行中的 checkpoint 一直等待甚至超时。超时的 checkpoint 会被仍未认为是 failed checkpoint,默认配置下,这会触发 Flink 的 failover 机制,而默认的 failover 机制是不重启。所以会造成上面的现象。
解决办法:在 flink-conf.yaml 配置 failed checkpoint 容忍次数,以及失败重启策略,如下:
execution.checkpointing.interval: 10min # checkpoint间隔时间
execution.checkpointing.tolerable-failed-checkpoints: 100 # checkpoint 失败容忍次数
restart-strategy: fixed-delay # 重试策略
restart-strategy.fixed-delay.attempts: 2147483647 # 重试次数
作业在运行时 mysql cdc source 报 no viable alternative at input 'alter table std'
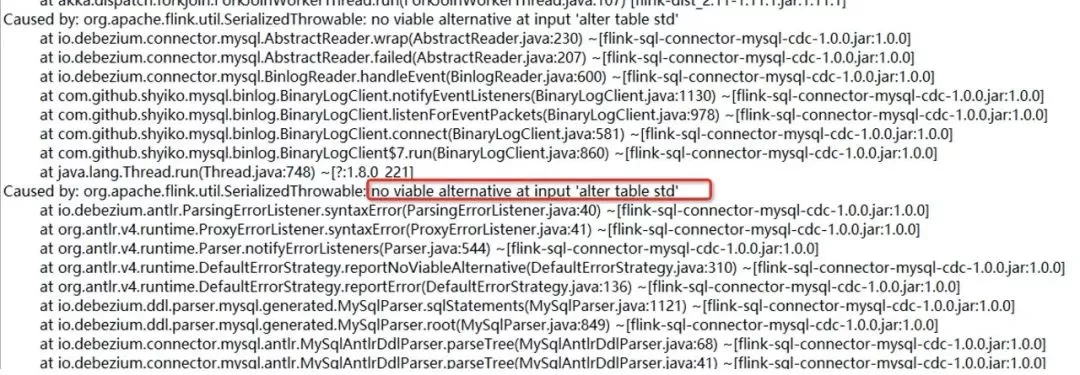
原因:因为数据库中别的表做了字段修改,CDC source 同步到了 ALTER DDL 语句,但是解析失败抛出的异常。
解决方法:在 flink-cdc-connectors 最新版本中已经修复该问题(跳过了无法解析的 DDL)。升级 connector jar 包到最新版本 1.1.0:flink-sql-connector-mysql-cdc-1.1.0.jar,替换 flink/lib 下的旧包。
多个作业共用同一张 source table 时,没有修改 server id 导致读取出来的数据有丢失。
原因:MySQL binlog 数据同步的原理是,CDC source 会伪装成 MySQL 集群的一个 slave(使用指定的 server id 作为唯一 id),然后从 MySQL 拉取 binlog 数据。如果一个 MySQL 集群中有多个 slave 有同样的 id,就会导致拉取数据错乱的问题。
解决方法:默认会随机生成一个 server id,容易有碰撞的风险。所以建议使用动态参数(table hint)在 query 中覆盖 server id。如下所示:
FROM bill_info /*+ OPTIONS('server-id'='123456') */ ;
CDC source 扫描 MySQL 表期间,发现无法往该表 insert 数据
原因:由于使用的 MySQL 用户未授权 RELOAD 权限,导致无法获取全局读锁(FLUSH TABLES WITH READ LOCK), CDC source 就会退化成表级读锁,而使用表级读锁需要等到全表 scan 完,才能释放锁,所以会发现持锁时间过长的现象,影响其他业务写入数据。
解决方法:给使用的 MySQL 用户授予 RELOAD 权限即可。所需的权限列表详见文档:
https://github.com/ververica/flink-cdc-connectors/wiki/mysql-cdc-connector#setup-mysql-server
如果出于某些原因无法授予 RELOAD 权限,也可以显式配上 'debezium.snapshot.locking.mode' = 'none'来避免所有锁的获取,但要注意只有当快照期间表的 schema 不会变更才安全。
下面这些问题来自腾讯云大数据官方博客,供大家参考。
Flink 作业自动停止
现象:本应长期运行的作业,突然停止运行,且再也不恢复。
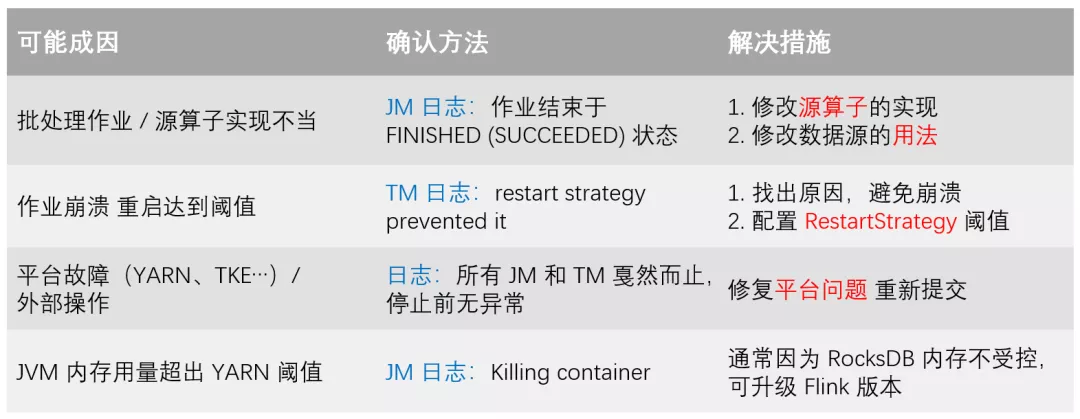
如果 Flink 作业在编程时,源算子实现不当,则可能造成源算子处理完数据以后进入 FINISHED 状态。如果所有源算子都进入了 FINISHED 状态,那整个 Flink 作业也会跟着结束。
Flink 作业默认的容错次数是 2,即发生两次崩溃后,作业就自动退出了,不再进行重试。当出现此种场景时,TaskManager 的日志中会有“restart strategy prevented it”字样。我们首先要找到作业崩溃的原因,其次可以适当调大 RestartStrategy 中容错的最大次数,毕竟节点异常等外部风险始终存在,作业不会在理想的环境中运行。
此外,旧版Flink(低于 1.11.0)的 RocksDB 内存使用不受管控,造成很容易由于超量使用而被外界(YARN、Kubernetes 等)KILL 掉。如果经常受此困扰,可以考虑升级 Flink 版本到最新,其默认开启自动内存管理功能。
Flink作业频繁重启
现象:作业频繁重启又自行恢复,陷入无尽循环,无法正常处理数据。

作业频繁重启的成因非常多,例如异常数据造成的作业崩溃,可以在 TaskManager 的日志中找到报错。数据源或者数据目的等上下游系统超时也会造成作业无法启动而一直在重启。此外 TaskManager Full GC 太久造成心跳包超时而被 JobManager 踢掉也是常见的作业重启原因。如果系统内存严重匮乏,那么 Linux 自带的 OOM Killer 也可能把 TaskManager 所在的 JVM 进程 kill 了。
当一个正常运行的作业失败时,日志里会有 from RUNNING to FAILED 的关键字,我们以此为着手点,查看它后面的 Exception 原因,通常最下面的 caused by 即是直接原因。当然,直接原因不一定等于根本原因,后者需要借助下文提到的多项技术进行分析。
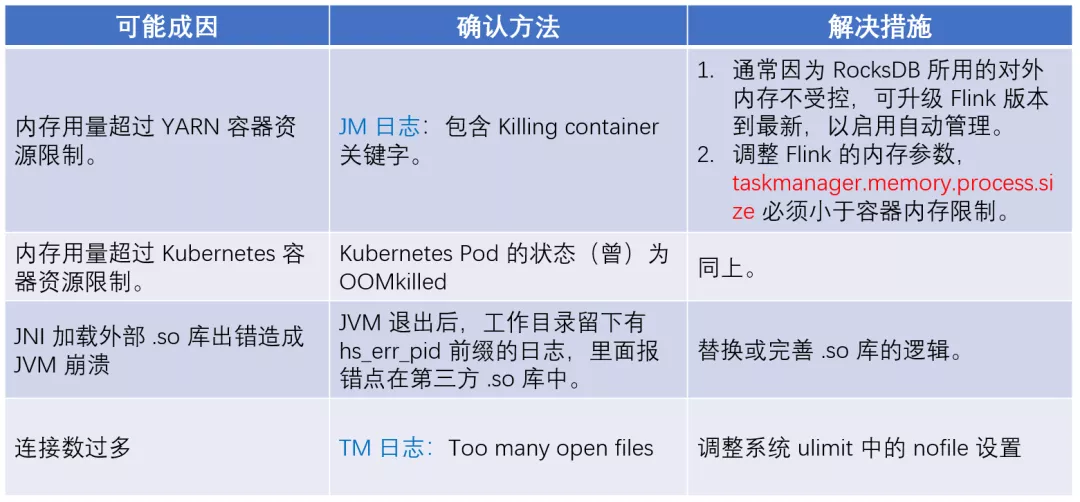
如果 JVM 的内存容量超出了平台方(例如 YARN 或 Kubernetes 等)的容器限制,则可能被 KILL。问题的确认方式也是查看作业日志以及平台组件的运行状态。值得一提的是,在最新的 Flink 版本中,只要设置 taskmanager.memory.process.size 参数,基本可以保证内存用量不会超过该值(前提是用户没有使用 JNI 等方式申请 native 内存)。
作业的崩溃重启还有一些原因,例如使用了不成熟的第三方 so 库,或者连接数过多等,都可以从日志中找到端倪。
作业输出整体稳定,但是个别数据缺失
现象:作业输出整体稳定,但是个别数据缺失,造成结果的精度下降,甚至结果完全错乱。
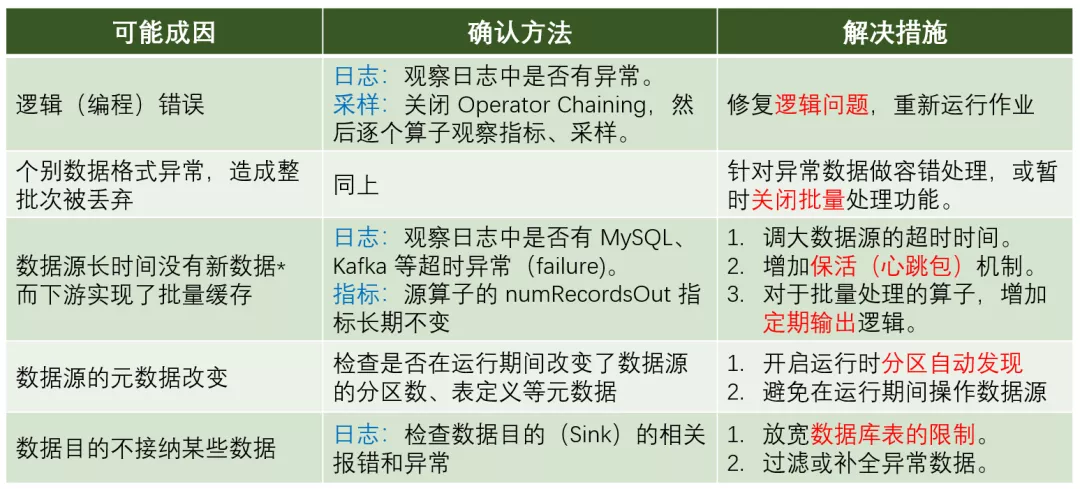
当遇到怀疑数据缺失造成的计算结果不正确时,首先需要检查作业逻辑是否不小心过滤了一些正常数据。检查方法可以在本地运行一个 Mini Cluster,也可以在远端的调试环境进行远程调试或者采样等。具体技巧后文也会提到。
另外还有一种情况是,如果用户定义了批量存取的算子(通常用于与外部系统进行交互),则有可能出现一批数据中有一条异常数据,导致整批次都失败而被丢弃的情况。
对于数据源 Source 和数据目的Sink,请务必保证 Flink 作业运行期间不要对其进行任何改动(例如新增 Kafka 分区、调整 MySQL 表结构等),否则可能造成正在运行的作业无法感知新增的分区或者读写失败。尽管 Flink 可以开启 Kafka 分区自动发现机制(在 Configuration 里设置 flink.partition-discovery.interval-millis 值),但分区发现仍然需要一定时间,数据的精度可能会稍有影响。
「PDF」就可以看到阿里云盘下载链接了!
Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
