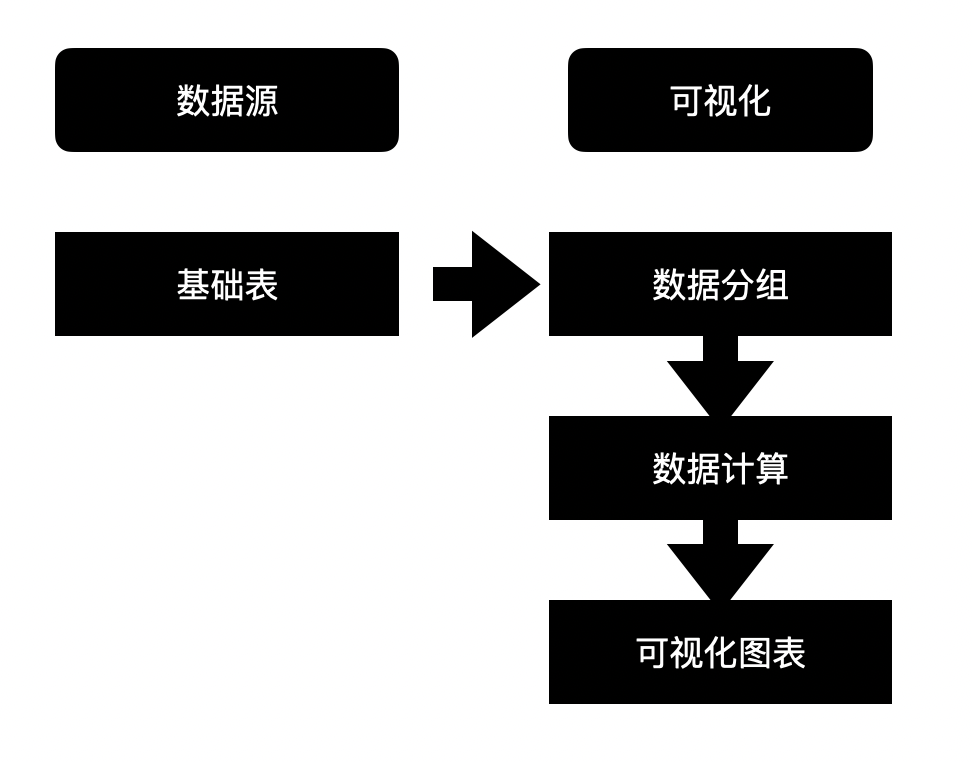
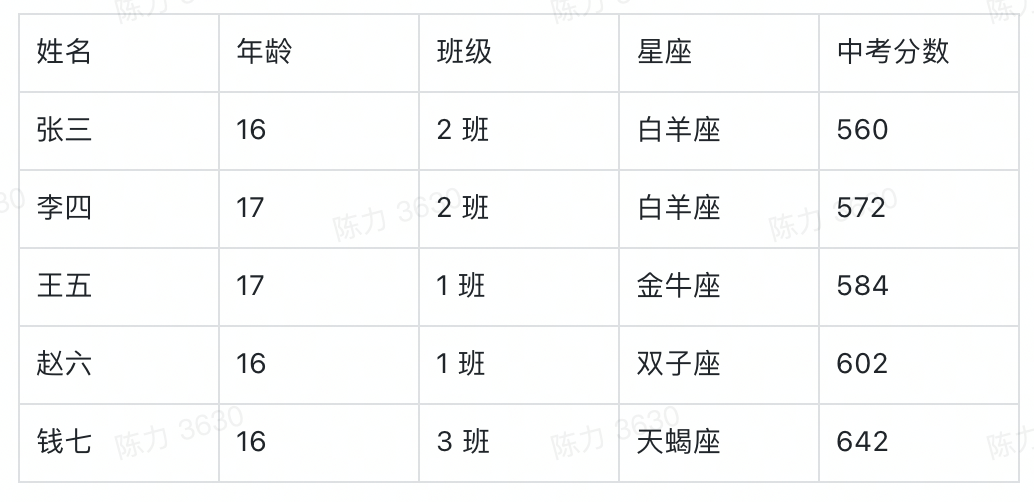
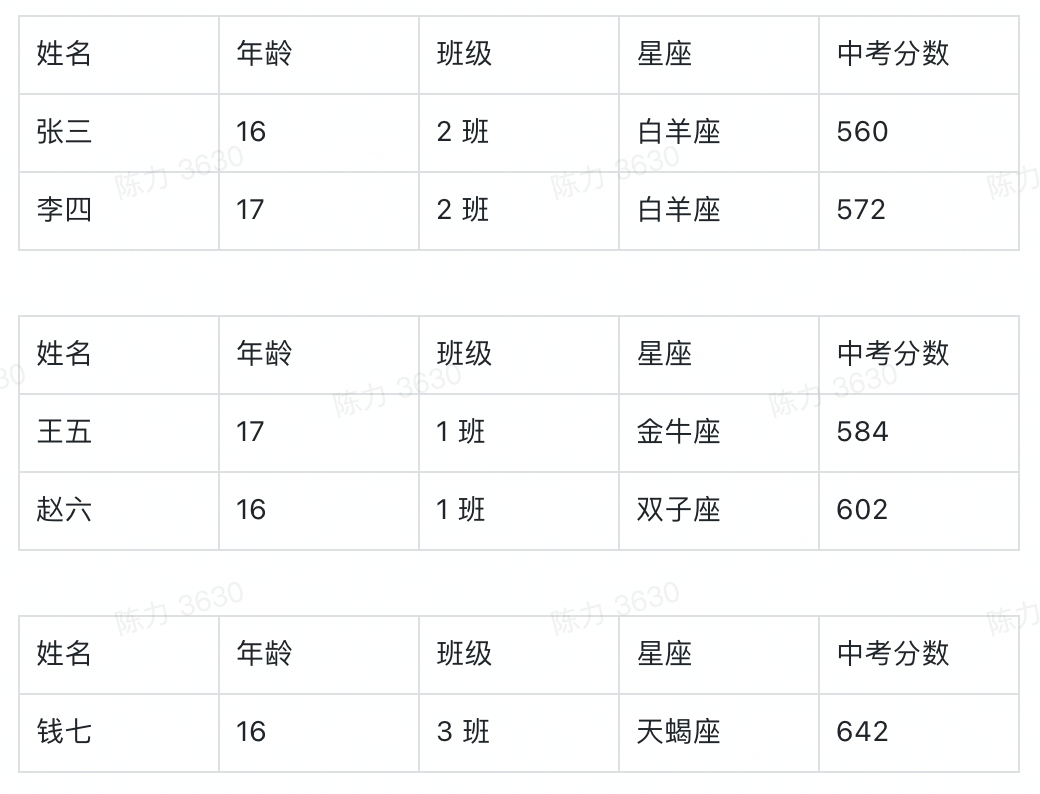
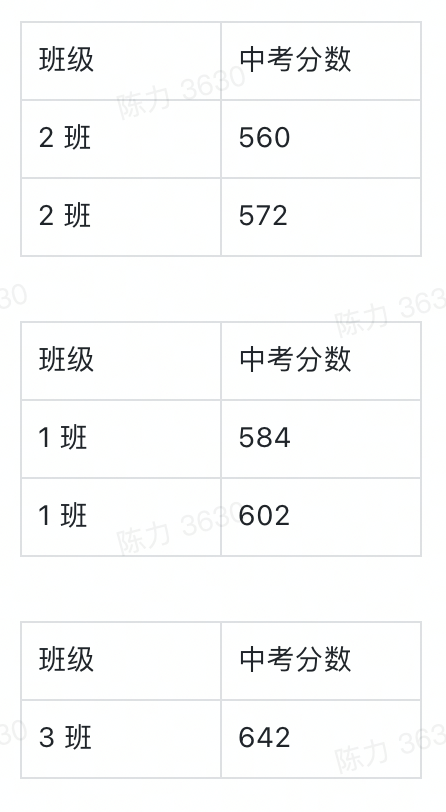
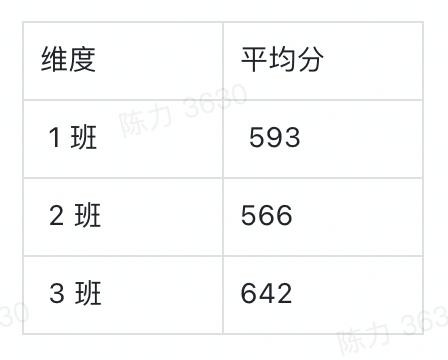
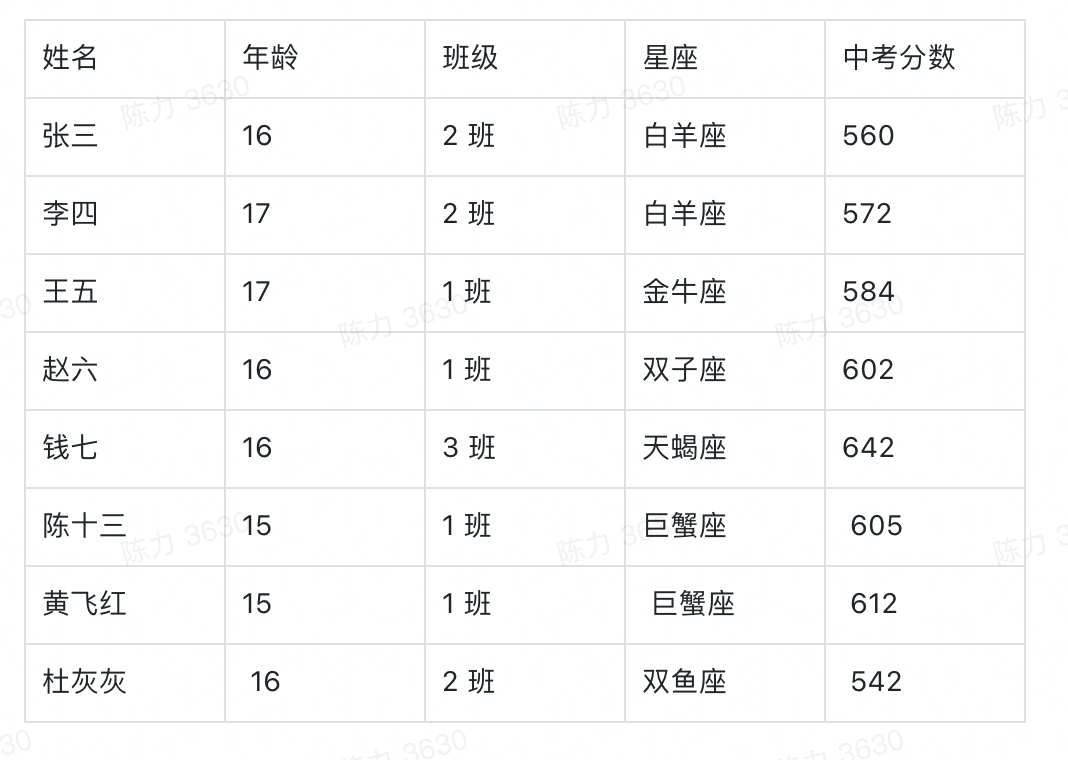
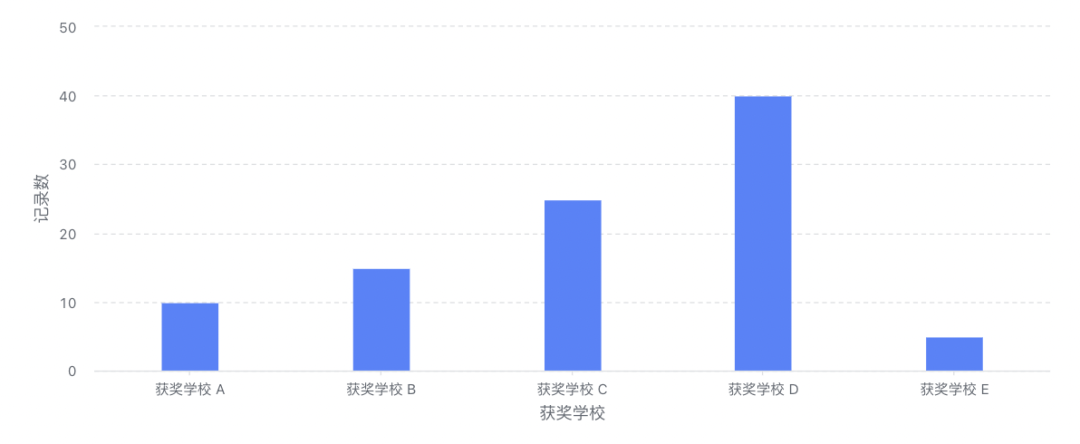
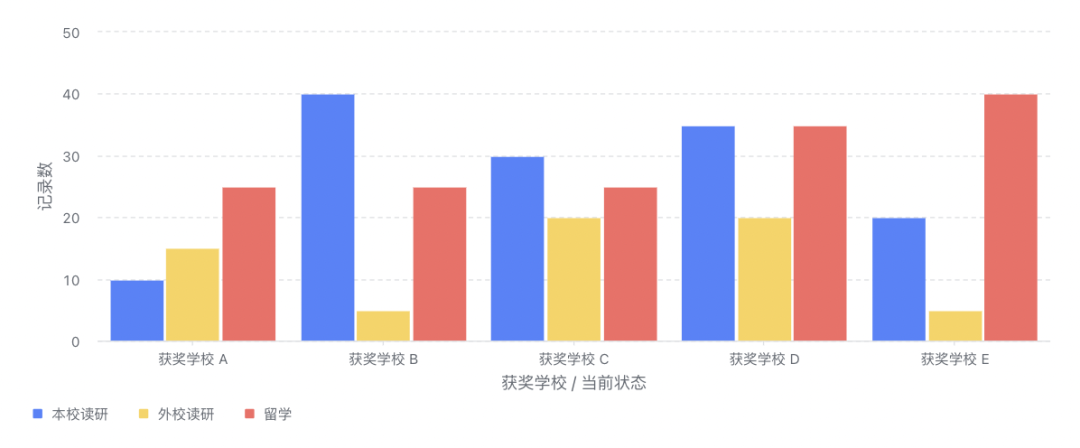
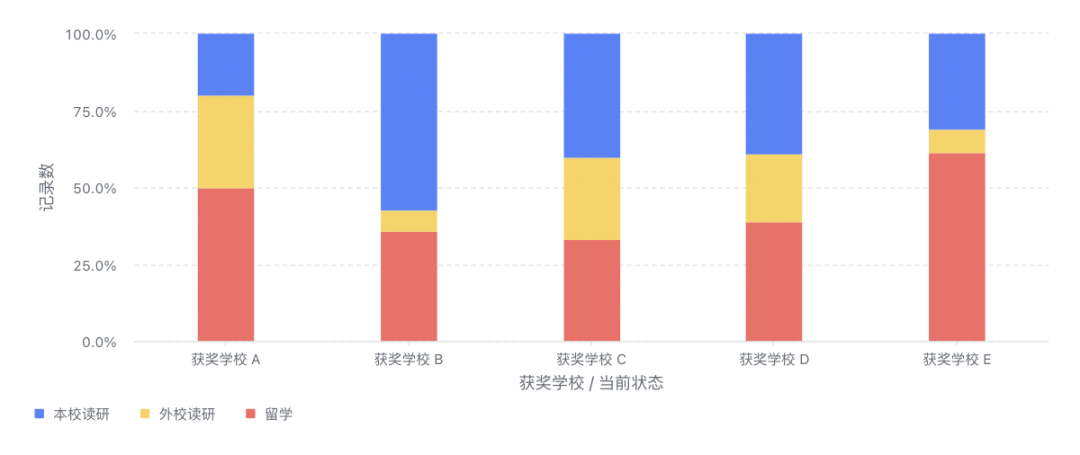
聊聊 aPaaS 中的可视化图表大力哥关注共 3825字,需浏览 8分钟 ·2022-06-03 01:54 如果不了解一个产品的底层逻辑,有可能你就从未了解过它。在小学数学课堂上,我就学习到了柱状图和折线图之间的区别,但是这之后的 20 多年,我从未想过一张图表到底是怎么产生的。直到我最近开始转行低代码,负责图表模块之后,我才有机会去探索它的底层逻辑。进一步地我发现,掌握了一个产品的底层逻辑,才算是真正入门了。一今年3月份我开始转行到低代码产品领域,负责的第一个模块就是图表。图表产品通常会包括两大块:数据源和可视化,我负责的是可视化这一部分。在我之前的认识中,数据可视化其实就是各种图表,了解清楚每个图表的应用场景就够了。比如你应该知道柱状图、折线图和环图之间的区别,这对于使用者来说就可以了。但是负责了低代码产品的图表模块之后,我需要让用户可以通过拖拽的方式自己搭建出不同类型的图表,这倒逼着我需要从原理上去了解一个图表是如何产生的。这种从底层逻辑到业务应用的推演非常有意思,当然对于我入门低代码的图表模块也非常重要。我想要把最近一段时间的学习成果写出来,也是想跟大家分享如何从底层去认识一个我们之前可能以为自己比较了解的产品。二一个图表的结构通常如下图所示:包括数据源和数据可视化两部分。数据源其实就是通过各种方式得到一张基础表,这个基础表代表了我们记录业务的所有明细数据。典型的基础表格式是 1+N,第一行是记录信息所需要的所有字段,第 2-N 行代表的是每一个实体的具体信息。举个例子,我可以用下面这张表记录一个学校高一年级所有学生的基本信息。从第二行开始,我就要录入每一个学生的信息,假设现在有 5 名学生,则这个基础表的信息可以展示为,而这个对于可视化系统来说,就是一个标准的数据源。顺便说一句,虽然本文不聊数据源,但数据结构的确定是可视化的重要前提,非常非常重要。当我们要去建立一个业务的数据模型时,我们一定要想清楚到底有哪些字段是需要添加的,每个字段的类型是什么。字段可以多,但一定不能缺。如果我们一开始没有星座这个字段,忽然有一天你突发奇想,觉得我们可以看看学校里不同星座的学生的占比,那意味着底层的数据模型就要变动,这时候所有用到这个模型的图表,可能都会受到影响。回到正题,「可视化」就是要通过更直观的方式呈现我们想要看到的结论。它满足两点要求:首先必须要直观,为了这一点,我们应该发明了很多不同的图表类型,后面会讲到;其次,它必须要支撑我们想看的结论,不带任何目标的可视化,都是无用功。我将可视化部分总结为三个具有前后顺序的动作:数据分组、数据计算和可视化。这也是本文的重点,我将详细说明。三数据分组是确定从什么视角看什么数据,这与我们想要分析的结论息息相关。事实上,当我们准确描述我们想要看的结论时,我们就已经在无形中确定了我们的数据分组。比如,我们想要看不同班级学生的中考分数,这时候「不同班级」就是我们的切分视角,「班级」这个字段,就成了我们的维度。确定分组之后,我们就可以按照班级这个字段的不同值,将基础表分为如下几张表:在上述结论中,隐含的另一个重要概念是指标,我们切分不同的班级之后,想看的不是年龄,也不是星座,而是中考分数。指标,就是我们想要看的数据。确定了维度和指标,真正的数据分组才算完整,他们应该是下面这三组表。四数据计算,就是给指标附上一个具有统计意义的值。这个值是从指标字段的明细数据中计算得来的,也可以说是聚合得来的,所以我们一般叫做聚合函数。例如对于 2 班的两个学生来说,中考分数分别为 560 和 572,如果我想看大家的平均分,那就是对这两个明细数据求平均,如果我想看每个班学生的最高分呢,用的就是求最大值函数。相同的明细数据经过不同的聚合函数作用后,会得到不同的结果,因而聚合函数直接反映了我们想要统计的目标。如果我们想要评估的是不同班级学生的底子水平如何呢?那可能平均分是一个不错的聚合函数。但如果某些班级有中考加分的学生,而这里的分数是正常文化课的分数,那我们看平均分可能就不客观了,这之后中位数应该是一个更好的选择。无论如何,随着我们想要分析的结论和明细数据的质量不同,我们选择不同的聚合函数,这个过程,就是数据计算。经过数据计算之后,维度和指标就都有了统计含义,以平均分为例。事实上,实际情况可能比这个复杂得多。实际场景中的维度可能不止一个,想要看的指标也不止一个,或者指标不是数字,这时候该怎么办呢?五聊聊维度嵌套和多指标。什么时候我们会有维度嵌套呢,就是某一个单独的字段无法满足我们切分数据的需求。我们对上述的例子扩充一些样本来解释这个问题。如果我想看不同班级中不同年龄学生的中考分数,那「不同班级中不同年龄」这个分组标准可以用一个字段分出来么?显然是不行的。此时我们分组的角度会变成先看「班级」,再看「年龄」,这就是维度嵌套的情况,它是由两个字段合起来决定一个分组的。这时候的分组就会变成1 班-15 岁-平均分1 班-16 岁-平均分1 班-17 岁-平均分2 班 -16 岁-平均分2 班-17 岁 -平均分3 班-16 岁 -平均分很明显,维度嵌套时,分组就变多了。理论上,维度可以一直嵌套下去,比如我在上述每一个分组的基础上,再按照星座去进一步细分组别。当然,这只是逻辑上的可行性,是否需要这么分,完全要看「要得到目标结论是否需要这么分」,还是那句话,可视化建立在业务分析目标上的。除了维度嵌套,还有多指标的情况。如果我想要看的是不同班级学生的年龄数据和中考分数数据,这时候「年龄」就不再是维度,而变成了指标。多指标不存在嵌套的情况,每个指标都是独立计算的,所以相较于多维度来说,多指标的情况应该更简单一些。六在我小学的时候,其实就已经接触过图表了,那时候所有的指标都默认是数字,所以他们可以做很多聚合运算。但是当我做低代码产品的时候,我发现任何具有统计意义的字段都可以作为指标。具有统计意义和数字类型不一定是相等的:金额、年龄、分数,这些数字类型的字段当然具有统计意义,但是你想过没有,文本类型的字段有没有统计意义呢?还是上面那个表,如果 2 班的文艺委员,想了解自己班上一共有多少个不同星座的学生,能不能统计呢?可以。那不同的星座该怎么统计呢?这就要用到去重计数这个聚合函数。所以,非数字类型字段作为指标时,如果具有统计意义,往往会用到计数和去重计数这两个聚合函数。你只需要记住,非数字类型的字段也是可以作为指标的。但并不是所有的都可以,如果某个字段存储的是一张照片,那确实就没啥统计的必要了。有人问?难道我不能统计一堆照片的平均像素大小么?可以的,但这时候,照片和照片像素应该是两个字段,你要统计的,其实是照片像素这个字段,本质上还是一个数字类型的字段。七讲到这里总结一下,基础表在可视化中需要完成两个基本的步骤,分组和计算。分组主要看维度和指标,计算主要看聚合函数。当然维度可以有多个,指标可以有多个。接下来便是可视化的核心步骤,从数据到图表的映射,更简单一些,就是将表格承载的数据,变成可视化的图表。目前市面上主流 BI 产品支持的图表类型非常多,常见的包括:透视表、指标卡、柱状图、条形图、折线图、面积图、组合图、饼图、散点图、雷达图、漏斗图、热力图、地图、桑基图等等。我们以常见的柱状图为例来说明数据到图表的映射,其他类型的图表分析欢迎大家订阅我的小报童,我会在那里做更详细的记录。面对任何一种图表,我们首先要想的是,维度和指标分别放在哪里。以柱状图为例,它的 x 轴一般作为维度,y 轴一般作为指标,且只有一个 x 轴和一个 y 轴,常见的用法如下:这张图我们能直接看到的就是不同学校有多少人获奖。除此之外,还有第三个能够承载信息的元素,颜色。它既可以是维度,也可以是指标,就看怎么用,如下图:这种情况下,我的 y 轴就是三个指标字段共用了,用颜色这个元素来区分,但本质上,他们是被独立观察的三个指标。我也可以用颜色承载维度,做维度的嵌套,看一个指标。这时候,我们看的就是不同学校中不同状态的学生的获奖记录数据。需要注意的是,一张图表中,颜色只能承载维度或者指标,不能同时兼任。八完成了数据到图表的映射之后,一张基本的图表就渲染出来了。当然我们还可以给它配置更多的信息,比如标题,比如每个柱子上的数据标签,甚至用堆积柱状图看不同状态学生的百分比。但是万变不离其宗。在丰富的展示样式背后,其实都是从数据源→数据分组→数据计算→可视化这一套系统流程。我们在脑子里思考后手动绘制也好,我们通过无代码的方式搭建出来也好,底层逻辑基本都是这一条链路。掌握了底层逻辑,才能在处理不同场景下的应用问题时做到有条不紊。九说点题外话,当我刚刚接手图表这个功能模块的时候,有很多业务方提了各种需求过来,也有之前积压的很多遗留需求。那时候我觉得,真的好难。面对每一个单点的问题,虽然我能够通过自己做产品的基本素养去理解问题并提出解决方案,但解决这个问题和解决下个问题之间,我并没找到本质上的联系。用经济学的话来说,我解决问题的边际成本是没有变的。但是当我逐渐理解了一张图表背后的底层逻辑之后,很多问题在我看来都是一个问题,我开始梳理清楚了不同需求之间的关系和脉络。在这个时候我才逐渐觉得,这项新工作我应该是入门了。我把这一切分享出来,也是希望大家,尤其是各位产品经理,在自己负责的领域内,努力找到你所能挖掘到的最深层次的通用逻辑。 浏览 46点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 聊聊Python中的6个三维可视化库Python大数据分析0使用RoughViz可视化Vue.js中的草绘图表前端全栈开发者0Seaborn的15种可视化图表详解数据派THU0PyG2Plot可视化图表库PyG2Plot是一个可视化图表库在Python3上的输出实现。安装$pipinstallpyg2plot使用frompyg2plotimport__version__,Plotline=Plot("AnyChart-AndroidAndroid 可视化图表库AnyChart-Android 是一个数据可视化库,包含多种内置图表类型,可轻松在 Android可视化图表实现揭秘趣谈前端0PyG2Plot可视化图表库PyG2Plot 是一个可视化图表库在 Python3 上的输出实现。安装$ pip installAnyChart-AndroidAndroid 可视化图表库AnyChart-Android是一个数据可视化库,包含多种内置图表类型,可轻松在Android应用程序中创建交互式图表。它能够在API19+(Android4.4)及以上版本运行。部分图表类型示例:3个超好用的数据可视化图表大数据DT0独家 | 可视化101:选取合适类型的可视化图表(下)数据派THU0点赞 评论 收藏 分享 手机扫一扫分享分享 举报


 下载APP
下载APP