
【NLP】图解 Attention完整版
本文约4000字,建议阅读11分钟
审稿人:Jepson,Datawhale成员,毕业于中国科学院,目前在腾讯从事推荐算法工作。
序列到序列(seq2seq)模型是一种深度学习模型,在很多任务上都取得了成功,如:机器翻译、文本摘要、图像描述生成。谷歌翻译在 2016 年年末开始使用这种模型。有2篇开创性的论文:
Sutskever等2014年发布的:https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf,
Cho等2014年发布的:http://emnlp2014.org/papers/pdf/EMNLP2014179.pdf
都对这些模型进行了解释。
然而,我发现,想要充分理解模型并实现它,需要拆解一系列概念,而这些概念是层层递进的。我认为,如果能够把这些概念进行可视化,会更加容易理解。这就是这篇文章的目标。你需要先了解一些深度学习的知识,才能读完这篇文章。我希望这篇文章,可以对你阅读上面提到的 2 篇论文有帮助。
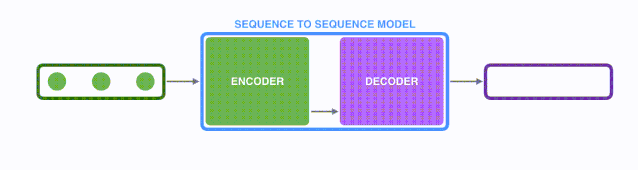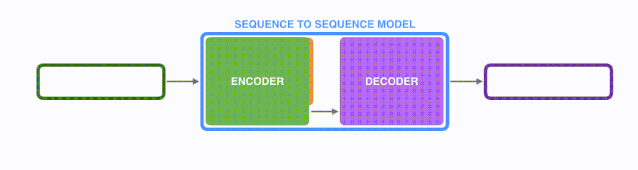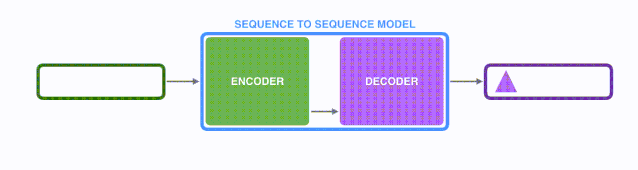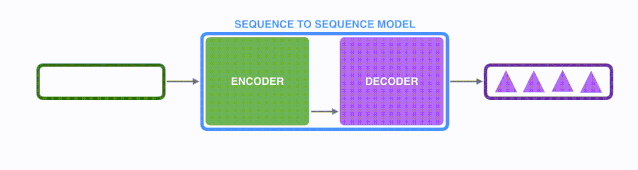
一个序列到序列(seq2seq)模型,接收的输入是一个输入的(单词、字母、图像特征)序列,输出是另外一个序列。一个训练好的模型如下图所示:

在神经机器翻译中,一个序列是指一连串的单词。类似地,输出也是一连串单词。

进一步理解细节
模型是由编码器(Encoder)和解码器(Decoder)组成的。其中,编码器会处理输入序列中的每个元素,把这些信息转换为一个向量(称为上下文(context))。当我们处理完整个输入序列后,编码器把上下文(context)发送给解码器,解码器开始逐项生成输出序列中的元素。
这种机制,同样适用于机器翻译。
在机器翻译任务中,上下文(context)是一个向量(基本上是一个数字数组)。编码器和解码器一般都是循环神经网络,一定要看看 Luis Serrano写的一篇关于循环神经网络(https://www.youtube.com/watch?v=UNmqTiOnRfg)的精彩介绍

你可以在设置模型的时候设置上下文向量的长度。这个长度是基于编码器 RNN 的隐藏层神经元的数量。上图展示了长度为 4 的向量,但在实际应用中,上下文向量的长度可能是 256,512 或者 1024。
根据设计,RNN 在每个时间步接受 2 个输入:
输入序列中的一个元素(在解码器的例子中,输入是指句子中的一个单词) 一个 hidden state(隐藏层状态)
然而每个单词都需要表示为一个向量。为了把一个词转换为一个向量,我们使用一类称为 "word embedding" 的方法。这类方法把单词转换到一个向量空间,这种表示能够捕捉大量的单词的语义信息(例如,king - man + woman = queen (http://p.migdal.pl/2017/01/06/king-man-woman-queen-why.html))。
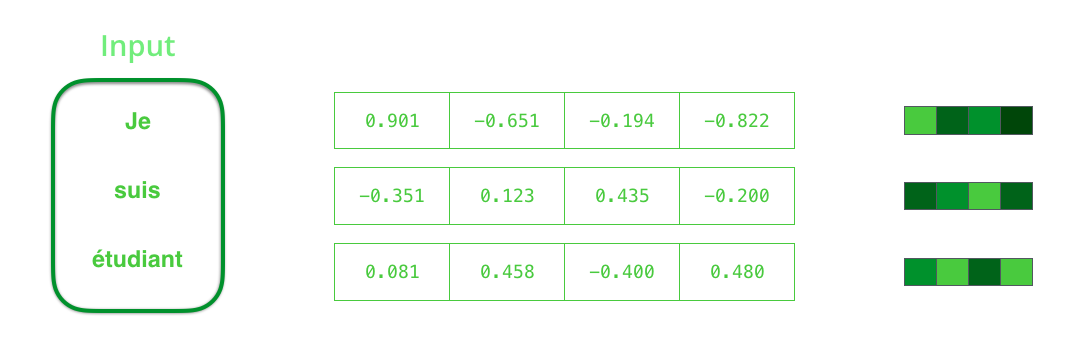
现在,我们已经介绍完了向量/张量的基础知识,让我们回顾一下 RNN 的机制,并可视化这些 RNN 模型:
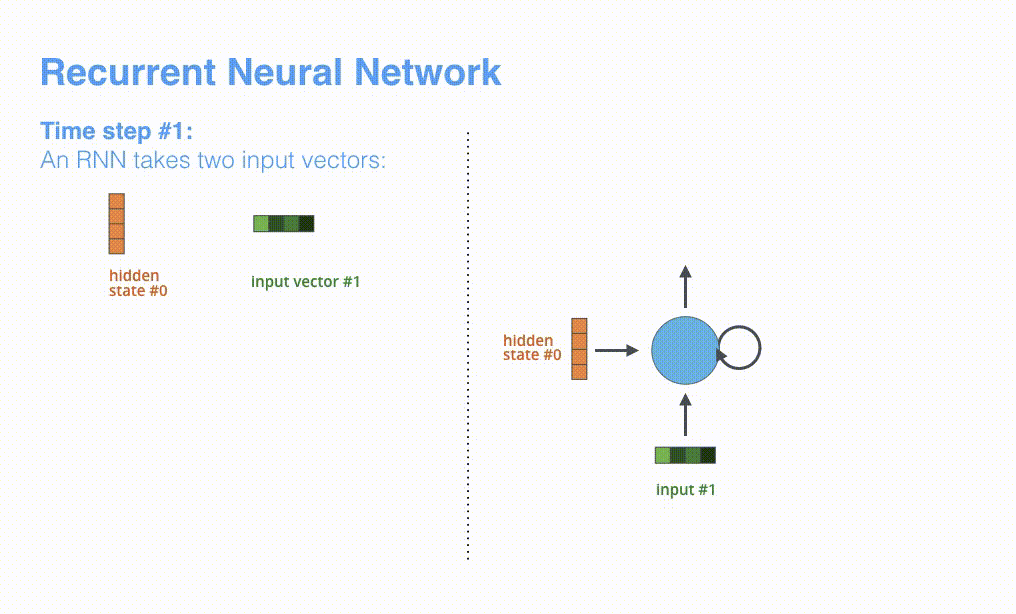
RNN 在第 2 个时间步,采用第 1 个时间步的 hidden state(隐藏层状态) 和第 2 个时间步的输入向量,来得到输出。在下文,我们会使用类似这种动画,来描述神经机器翻译模型里的所有向量。
在下面的可视化图形中,编码器和解码器在每个时间步处理输入,并得到输出。由于编码器和解码器都是 RNN,RNN 会根据当前时间步的输入,和前一个时间步的 hidden state(隐藏层状态),更新当前时间步的 hidden state(隐藏层状态)。
让我们看下编码器的 hidden state(隐藏层状态)。注意,最后一个 hidden state(隐藏层状态)实际上是我们传给解码器的上下文(context)。
解码器也持有 hidden state(隐藏层状态),而且也需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。我们没有在上图中可视化解码器的 hidden state,是因为这个过程和解码器是类似的,我们现在关注的是 RNN 的主要处理过程。现在让我们用另一种方式来可视化序列到序列(seq2seq)模型。下面的动画会让我们更加容易理解模型。这种方法称为展开视图。其中,我们不只是显示一个解码器,而是在时间上展开,每个时间步都显示一个解码器。通过这种方式,我们可以看到每个时间步的输入和输出。
Attention 讲解
事实证明,上下文向量是这类模型的瓶颈。这使得模型在处理长文本时面临非常大的挑战。
在 Bahdanau等2014发布的(https://arxiv.org/abs/1409.0473) 和 Luong等2015年发布的(https://arxiv.org/abs/1508.04025) 两篇论文中,提出了一种解决方法。这 2 篇论文提出并改进了一种叫做注意力(Attention)的技术,它极大地提高了机器翻译的质量。注意力使得模型可以根据需要,关注到输入序列的相关部分。
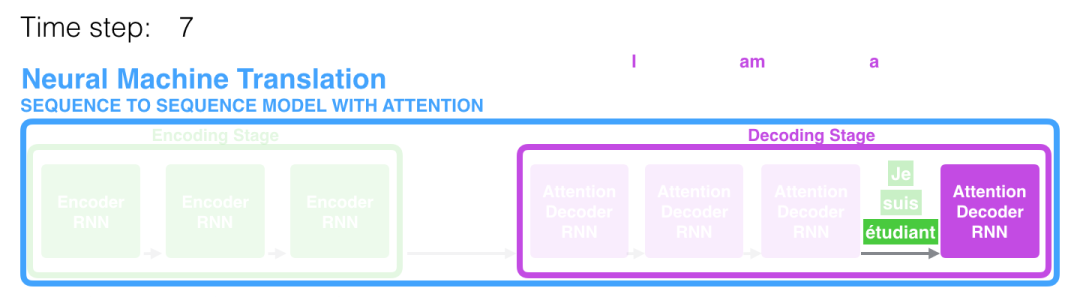
让我们继续从高层次来理解注意力模型。一个注意力模型不同于经典的序列到序列(seq2seq)模型,主要体现在 2 个方面:
首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态)。
第二,注意力模型的解码器在产生输出之前,做了一个额外的处理。为了把注意力集中在与该时间步相关的输入部分。解码器做了如下的处理:
查看所有接收到的编码器的 hidden state(隐藏层状态)。其中,编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词。 给每个 hidden state(隐藏层状态)一个分数(我们先忽略这个分数的计算过程)。 将每个 hidden state(隐藏层状态)乘以经过 softmax 的对应的分数,从而,高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
这个加权平均的步骤是在解码器的每个时间步做的。
现在,让我们把所有内容都融合到下面的图中,来看看注意力模型的整个过程:
注意力模型的解码器 RNN 的输入包括:一个embedding 向量,和一个初始化好的解码器 hidden state(隐藏层状态)。 RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state(隐藏层状态 h4 向量),其中输出会被忽略。 注意力的步骤:我们使用编码器的 hidden state(隐藏层状态)和 h4 向量来计算这个时间步的上下文向量(C4)。 我们把 h4 和 C4 拼接起来,得到一个向量。 我们把这个向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。 前馈神经网络的输出的输出表示这个时间步输出的单词。 在下一个时间步重复这个步骤。
下图,我们使用另一种方式来可视化注意力,看看在每个解码的时间步中关注输入句子的哪些部分:

如果你觉得你准备好了学习注意力机制的代码实现,一定要看看基于 TensorFlow 的 神经机器翻译 (seq2seq) 指南(https://github.com/tensorflow/nmt)
本文经原作者 @JayAlammmar(https://twitter.com/JayAlammar) 授权翻译,期望你的反馈。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: