
Flanneld续租IP异常导致网络问题分析
版本信息:
K8S版本:1.14.8Flannel版本:0.7.1
一、现象:
业务反馈有部署集群的节点上的pod无法做域名解析。pod到coredns pod网络不通。登录到节点查看日志发现flannel有如下报错:
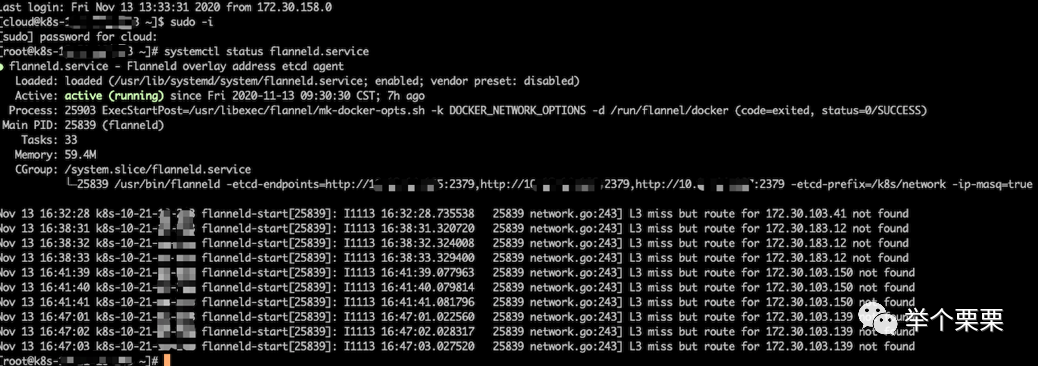
二、分析:
查看flannel.1和dockerd的bip,网段都不是172.30.103.0。而在etcd中存储的是172.30.103.0网段。导致flannel网段和docker网段不一致无法通信。
继续查看日志,发现Flanneld续租有问题:

这里需要介绍一下Flanneld续租SubNet的机制。

三、临时解决方式:
1)需要重启docker:删除flannel.1网桥,重启Flanneld和docker。
systemctl status flanneldps -ef | grep dockerdsystemctl stop flanneldifconfig flannel.1 downip link del flannel.1systemctl restart flanneldsystemctl restart docker
2)不需要重启docker
1. etcd删除新的网段配置;2. etcd加回来旧的网段配置;3. 重启异常机器上flanneld;4. 若问题依旧可以设置定时重启flanneld进程重新续租。
3)设置etcd中对应的TTL时间为0,即不过期。
# etcdctl -o extended get /k8s/network/subnets/172.30.103.0-24Key: /k8s/network/subnets/172.30.103.0-24Created-Index: 280421902Modified-Index: 280421902TTL: 0Index: 280421995{"PublicIP":"10.21.xxx.xxx","BackendType":"vxlan","BackendData":{"VtepMAC":"2a:a0:03:b8:34:5a"}}
4)设置flannel的启动参数,缩短续租时间
-subnet-lease-renew-margin=720扩展:
Flanneld网段扩容方案:
Flannel子网有几种获取方式:
第一种是所有flanneld都直连etcd,自主决定要使用的子网,抢占的方式。
第二种是部署flannel server(运行在server模式的flannel),flanneld连接flannel server。
第三种是flanneld直连kube-apiserver,从kube-apiserver中获取子网网段,-kube-subnet-mgr。
这里的方案适用于第一种方式:只要每个node上的子网前缀是不变的,调整flannel整个网段的前缀就是安全的,已有node分配的网段不会发生变化,新增node的网段不会与其它node的网段重叠。(通过分析0.7.0版本申请子网的代码 tryAcquireLease --> allocateSubnet --> createSubnet 可知)
直接修改Flannel网段:
# etcdctl set /coreos.com/network/config '{"Network":"11.0.0.0/8"}'// 扩容之后,新增node的网段情况如下:$ cat /run/flannel/subnet.envFLANNEL_NETWORK=11.0.0.0/8 // 网段前缀是/8FLANNEL_SUBNET=11.0.47.1/24FLANNEL_MTU=1426FLANNEL_IPMASQ=false// 已有node的上的网段还是以前的配置:$ cat /run/flannel/subnet.envFLANNEL_NETWORK=11.0.0.0/16 // 注意还是/16FLANNEL_SUBNET=11.0.98.1/24FLANNEL_MTU=1426FLANNEL_IPMASQ=false// Pod之间的通信不受影响,并且将已有node上的flannel重启后,子网配置会自动刷新:$ cat /run/flannel/subnet.envFLANNEL_NETWORK=11.0.0.0/8 // 前缀刷新FLANNEL_SUBNET=11.0.98.1/24 // 子网网段不变FLANNEL_MTU=1426FLANNEL_IPMASQ=false