
如何选择合适的数据库(对象存储、SQL、NoSQL等)?

数据库本身功能非常单一,仅可作为数据的存储介质,但错误的数据库选型带来的代价可能就是项目性能的大幅下降,对于很多企业应用来说这也是致命的伤害,另外,选择不同数据库类型同样会决定系统中其他模块的设计,因此,数据库选型对于整个项目非常重要,我们通常也称这种需求为非功能性需求(NFRs,non-functional requirements),对于数据库,主要需要考虑如下三点因素:
数据结构 查询模式 数据规模
目前,市面上已经有各类存储解决方案了,本文我们就来讨论一下如何在这些方案中选择最适合自己的方案。
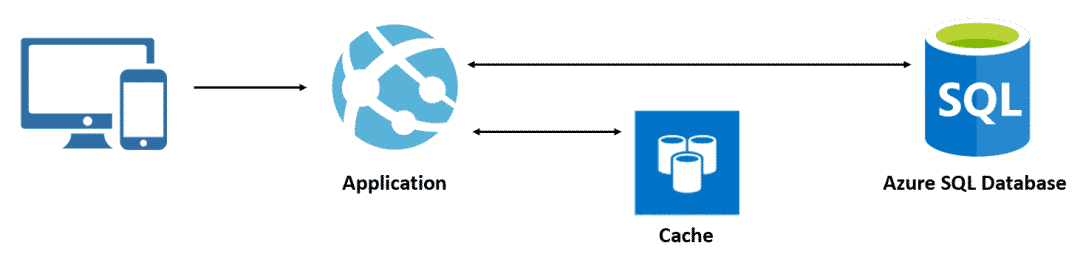
缓存
如果项目需要频繁调用数据库 API 或者一些高延迟的远程服务,那么可能需要最先考虑在客户端和数据库之间使用缓存来降低延迟。目前,常用的缓存方案有 Memcached,Hazelcast,Redis,这些方案大同小异,但 Redis 使用最广泛且稳定,是目前国内最常用的数据库缓存解决方案。
文件存储
如果需要开发一款抖音、B 站之类的产品,就需要存储大量图像、视频等数据,仅仅一个数据库可能并不能满足我们的需求,因为这时需要存储的是文件而非一般的数据信息,数据库本质依然只能用来查询信息数据而已,而文件本身也并不用“查询”,只需要按需拿到这整个文件即可,这种情况下,符合项目要求的解决方案就是对象(Blob)存储方案,如 Amazon S3,通常,Blob 存储方案还可以与 CDN 结合使用来减少延迟,这样就可以实现无地理位置差异提供内容服务。
提供文本搜索功能
淘宝、京东这些大型应用都会提供内容的搜索功能,这样就可以方便用户按照商品类型、品牌对数据进行分类搜索,这种功能通常会使用 Solr 或 Elasticsearch 之类的搜索引擎服务,这类搜索服务通常也会支持模糊搜索,例如会考虑到用户拼写错误的情况,这会很大程度上提升用户体验。
但是,搜索引擎不是是数据库,并不能保证我们的数据不会丢失,因此我们不能使用 Elasticsearch 这类搜索引擎作为数据源,这里就需要我们配合两者使用,将数据库中的内容加载到 Elasticsearch 中来降低搜索延迟,然后在以此为基础提供搜索功能。
时序数据库(TSDB,Time series database)
时序数据库全称为时间序列数据库(Time series database),是关系型数据库的一种,主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
如果我们要开发的系统对时间特别敏感,如股票交易、财务分析系统,此时就需要经常对一定时间的内数据分析,如过去 1周,10天,1个月,1 年等等,TSDB 会以毫秒级的速度给出这些我们需要的数据,传统数据库很难做到这一点。
目前,市面上常用的时序数据库有 OpenTSDB、InfluxDB 等。
数据仓库
很多项目也会需要一类能够存储巨量数据的数据库,如滴滴需要存储所有订单信息来分析哪个城市、那个时间段为使用率最高,这些系统通常和常规用户可感知的交易不同,可以使用脱机类型的数据仓库。Hadoop 是目前主流的数据仓库解决方案。
SQL OR NoSQL
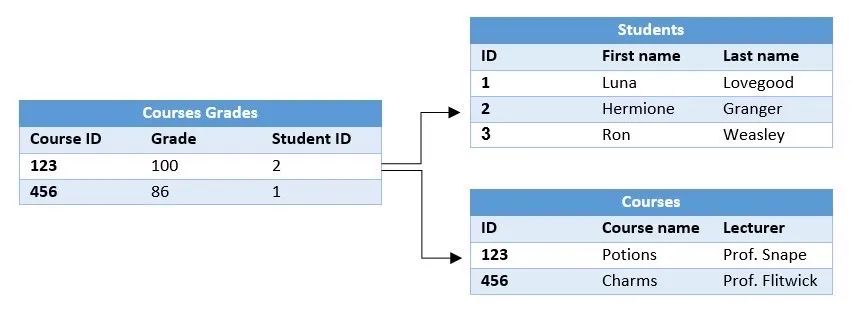
如文章开头所述,数据结构是我们用来做数据库选型时的重要因素之一,如果我们要存储结构化或者可以表格形式表示的数据,则可以使用关系型数据库。
同时,我们还将考虑数据库是否需要拥有 ACID 性质,即原子性(Atomicity),一致性(Consistency),隔离型(Isolation),持久性(Durability)四大性质。
原子性,保证所有操作要么全有要么全无。
一致性,保证操作前后数据库状态一致。
隔离性,意味着多个事务单独进行,一个事务将不受另一正在进行的并行事务的影响。这能保证数据库应该能够处理并发事务而不会导致数据不一致的情况。
持久性,保证一旦事务完成,更改将被永久写入磁盘,并且不会因系统故障而丢失。
如果我们的项目需要 ACID,则需要使用关系数据库(RDBMS),如 MySQL,Oracle,Postgres 等,但是,如果不需要 ACID,那么也可以非关系性数据库。
例如,项目中需要为商品建立目录索引,每个商品通常会有不同的属性和信息,如药品有保质期,冰箱有节能等级等等,再例如我们的用户表单中每位用户也可能会有不同的属性值,在这种情况下我们的数据就不能够以表格形式表示,可以选择使用 NoSQL 数据库。

另外,除了储存,我们通常还需要查询这些类型的得到数据,这就需要考虑查询模式这个要素,我们会根据存储的数据类型和查询类型来决定最终使用哪种数据库。如果项目中会含有大量数据,包括各种各样的属性和各种各种的查询请求,就需要使用文档型数据库(Document DB),如 Couchbase、MongoDB。
Elasticsearch 和 Solr 也是特殊文档型数据库。
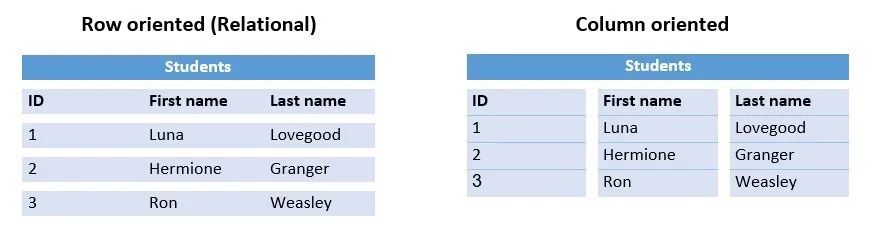
如果我们的数据并没有各种各样的属性,查询类型也很有限,简单增删改查足以,但是数据库的存储量很大,如滴滴司机的位置,这类数据每时每刻都会增加,这种情况下,我们通常会使用柱状存储模型的数据库,也称列型(Columnar DBs)数据库,如 Cassandra、HBase。这类数据库每个列都有一个 column key 标识,每个 column key下对应若干 value,可以很轻松的获得包含某个列的数据。
在个人的小型项目我们通常会选择 Cassandra,因为非常轻量而且部署起来非常方便,性能也完全不亚于 HBase,而 HBase 基于 Hadoop 显得过于臃肿。因此,我们可以说在数据查询时可以直接通过 where 语句指定 key 查询时,可以选择 Cassandra。
如果我们将滴滴中与打车相关的订单数据存储在 Cassandra 后,司机的 id 可以作为每个列分区的 column key,当我们想要查询特定时间段内该司机的路程,Cassandra 就可以立即帮我们在对应列中查询到这些数据,但这时,当我们想要查询某个日期内乘客的乘车记录,由于客户 ID 并不是分区 column key,因此 Cassandra 就需要查询整个分区,这时 Cassandra 性能就会大打折扣!
这种情况下,我们可以使用不同的分区 key 将相同的数据复制到另一个表或列中,这时,当我们收到有关客户 ID 和日期的查询时,我们可以将其直接定向到分区 kay 为客户 ID 的表中,这就是查询的种类少但数据量大的意思,只要查询的类型相似,Cassandra(和 HBase)就可以无限扩展,但如果查询的种类非常多的话,我们就必须为每个分区 key 一次又一次地复制,直到达到一定的限制。
如果我们不能控制查询的类型,还是选择采用 MongoDB 之类的方案,但是,如果我们只需要针对少数几种查询的大规模扩展,那么 Cassandra 就是完美的解决方案。
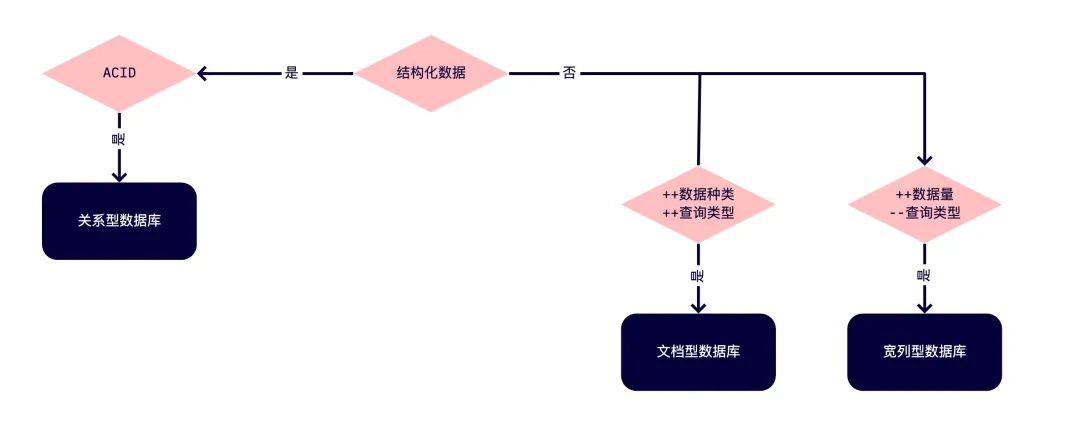
现在,我们大概知道了基本的方向了,如果存储结构化数据并且需要 ACID 性质,则使用关系数据库(如 MySQL),如果存储具有许多属性的海量数据,则可以使用文档数据库(如 Mongo DB),如果数据非常简单,查询种类较少,则使用列式数据库(如 Cassandra),但是实际项目中,还并不这么简单。
混合使用
我们再以淘宝为例,对于一个商品来说,库存中只有一件,但是很多用户想要买,那么最终应该只能卖给一个用户,这就需要我们的数据库拥有 ACID 性质,因此,需要 MySql 这类关系型数据库,但是淘宝中的商品数据也在不断增加,属性也多种多样,我们也需要使用 Cassandra 这种列存储模型的 NoSQL 数据库。我们应该选择哪一种?在实际项目中,我们通常会混合使用这两种数据库,例如,将尚未交付的订单数据存储在 MySQL 数据库中,一旦订单完成,我们就可以将其移至 Cassandra 进行永久存储。
我们的需求还会变得更复杂,假如我们需要为购买商品的客户构建一个报告系统,淘宝上的商品通常会由不同品牌、不同版本向不同的客户出售,因此,报告也不能针对单个产品,而应针对产品的子集,这类需求可以使用 Cassandra 或 MySQL 实现,但是更好的方案是使用 Mongo DB 这类文档型数据库,我们可以将订单数据的子集保存在 MongoDB 中,这些数据可以告诉我们哪些用户在什么时候,什么日期购买了某种商品的数量。
因此,如果我们要查询有多少人在上个月购买了 MacBook,我们可以从 MongoDB 中获得订单 ID,并使用此订单 ID 来从 Cassandra 或 MySQL 中查询其他的数据。