
视频会议一体机的技术实践和发展趋势
作者 | 伟隆 钉钉蜂鸣鸟音频实验室 算法专家
在混合办公的常态趋势下,远程沟通协作的效率至关重要。然而,远程会议目前依然存在不少影响沟通的问题,比如缺乏会议室拾音和放音设备、软硬件设备不兼容、因远场拾音导致听不清等,这些问题都会消磨与会者的耐心,影响会议效果,让团队逐渐失去讨论的激情。
因此,无论是国外的微软、Zoom,还是国内的钉钉、腾讯会议,都在建立自己的硬件终端生态,期望通过硬件来解决线上、线下混合办公中的拾音问题,比如麦克风、音视频一体机、会议平板等。但即便如此,在线下开会时最常见的一个现象,依然听不清甚至听不到。解决这一问题的关键,是解决远场拾音的问题。
实际上,自从上世纪 80 年代以来,远场拾音就是工业界的痛点与学术界的难点,难点主要来自于三方面音频问题:混响、噪声、回声,其中去除“混响”更是曾被美国工程院列为“当代未解决的十大工程问题之一”。
目前,业界并没有成熟的、可量产的解决方案。基于此,钉钉蜂鸣鸟音频实验室自研了差分麦克风阵列算法,并率先在 F2 视频会议一体机中实现单机 10 米远场拾音的突破,并且这一技术方案,可以进行模块化拆分,共享给硬件厂商,来提升他们硬件设备的拾音或者视频的能力。
1 远场拾音要攻克哪些技术难点?
音视频行业经常说“no video, we talk; no audio, we walk”,意思是说,音频在音视频会议中的重要性要高于视频,而音频却一直是薄弱点。
在中大型会议场景中,比如商务会议、汇报会议等,会议室的物理距离会造成声音能量的衰减。
为了解决这一难题,市面上之前主流的产品主要为分体式设备,通过部署多台麦克风在会议桌上来拾音。而视频会议一体机则需要实现单机远场拾音,克服远距离传输、混响、噪声、回声等技术难点,让参会者能更好地听见与被听见,在每一场会议中尽情地表达、充分地交流。
1、远距离传输
在大型会议室交流时由于听不清对方的说话声,只好“喂喂喂”反复确认,有时候还不得不走到设备跟前,确认通信是否正常。
其实这种场景下,通信链路往往是正常的,问题是因为设备拾音质量不高、人和设备的距离较远造成的。声音能量衰减是随着传播距离的平方成正比的,相对 1 米处的拾音能量,4 米处会衰减到 1/16、10 米处会衰减 100 倍。远距离声音物理衰减会造成目标语音的一些成分在频谱上消失。因此,一旦距离远了,麦克风原始信号里面的目标信号就会被更近距离的噪声覆盖。
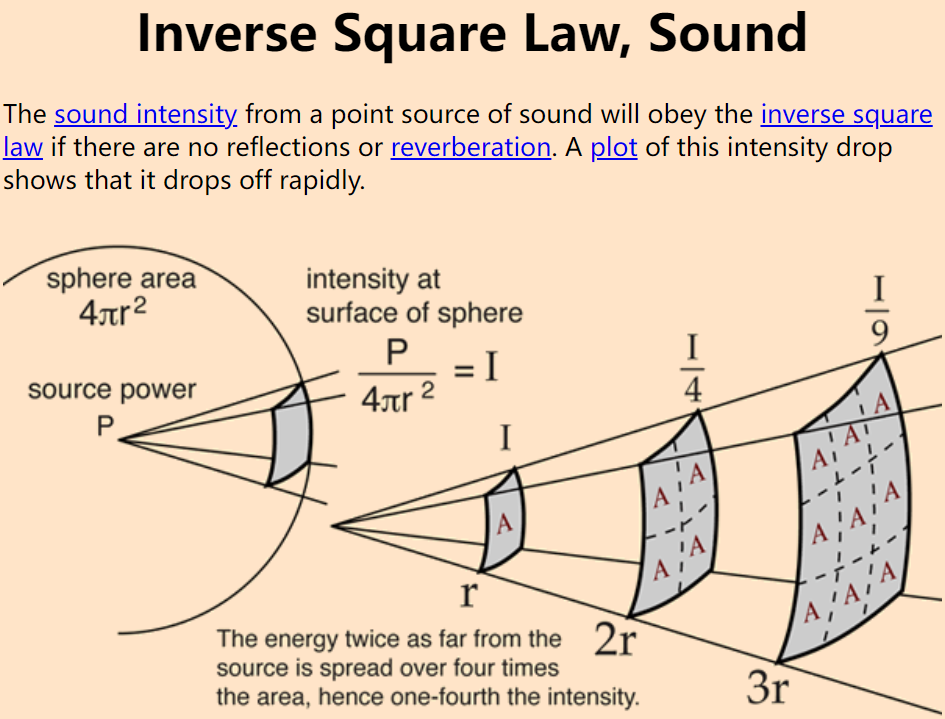
2、混响(reverberation)
我们在开会时偶尔会听到对方的声音感觉很浑浊,像来自很遥远的山谷,这就是混响导致的问题。
混响产生在密闭的空间内,接收端接受到的声音是通过多途径传播而来,由于墙面的反射造成的多途径传播,其中反射分为低阶反射和高阶反射,分别形成了早期混响和晚期混响。而这些混响对于人有两个明显的主观听感效应(perceptual effect):
盒子效应(box effect):感觉声音从四面八方而来,让听到的人似乎身处一个盒子里面(“inside a box”),听上去很浑浊不舒服。
远距离说话人效应(distant talker effect):感觉声音来自很远的地方,甚至比实际距离还要远。
2 钉钉蜂鸣鸟实验室在远场拾音的探索及应用
在远场拾音或远场语音交互过程中,近年来麦克风阵列技术起到了不可或缺的作用。
实验室自研的麦克风阵列技术是业界首次将麦克风声学特性和差分波束理论的优势进行结合的实践,将差分波束在低频段的白噪声增益明显提升,从而明显改善了语音低频拾音的鲁棒性,使得 F2 远场拾音中语音质量明显提升。
F2 麦克风阵列技术主要包括差分波束成形技术(differential beamforming)和多通道去混响算法。
1、差分指向性麦克风阵列波束形成技术

波束成形(beamforming)源自雷达天线技术 - 传感器阵列,如上图,在通信领域,波束成形能够为基站带来更远的信号覆盖范围。相似的,近年来麦克风阵列技术起到了不可或缺的作用,基于麦克风阵列的波束成形在空间形成一个空间滤波器,在目标声音直达声方向现成一个拾音波束,将被淹没的目标方向语音从来自其他干扰信号中无损恢复出来。
其中差分麦克风阵列技术(DMA,differential microphone array)或者差分波束成形技术(differential beamforming),由于具有较多的物理特性优势,尤其适合语音信号处理,近年来成为信号处理领域研究热点,同时在工业界也被广泛使用。
关于差分麦克风阵列,钉钉蜂鸣鸟实验室业界首次将麦克风声学特性和差分波束理论融合优化,提出了自研的差分指向性麦克风阵列(differential directional microphone array),明显改善了该技术领域上的痛点问题: 语音低频拾音的鲁棒性,将差分波束在低频段的白噪声增益明显提升 20db。

实验室的研究工作以系列论文的形式发表在了 INTERSPEECH、ICASSP 等国际语音顶会,得到同行评审的认可(见文末论文 list)。独立测试表明,无论在客观测试 - 语音识别准确率和主观测试 - 音质评估方面,其远场拾音性能在业内均处于领先地位:
远场语音识别准确率比业界标杆竞品高 7~9 个百分点,音质清晰度则超越所有在市场上能找到的全球知名品牌;钉钉音视频一体机 F2 则是该理论的又一个落地产品。
2、多通道去混响技术
目前大多数语音去混响算法可以分为三大类:频谱增强(spectral enhancement), 间接逆滤波(indirect inverse filtering), 直接逆滤波(direct inverse filtering)。
频谱增强(spectral enhancement)的方法往往在混响语音频谱上应用一个实数或者复数掩码(mask),将混响当作噪声抑制掉,而这种方法性能有限且带来一定的失真,因为混响并不是一个加性噪声。
间接逆滤波(indirect inverse filtering)往往需要声源和接收端之间的传播函数,此方法可以完美地去混响,但是在现实应用中,这些传播函数是不可以获得的。
直接逆滤波(direct inverse filtering)往往依赖麦克风阵列信号本身而不是传播函数进行混响预测,适合实际应用。行业内应用地最多的直接逆滤波(direct inverse filtering)方法是基于多通道线性预测(MCLP:multichannel linear prediction)。
实验室基于 MCLP 算法持续研究,调研复现最新的研究成果,在 F2 的实际应用中相继解决了当前 MCLP 中的多个实际问题:较多麦克风数量的计算复杂度问题,较少麦克风数量的性能下降问题,滤波器的精度爆炸问题,基本上形成了自有的低复杂度高性能鲁棒多通道去混响算法。
3 视频会议硬件行业会如何发展?
视频会议硬件的本质是什么?是让在相同时间、不同空间下多人的协同效率更高。一开始远程互动只需要邮件、电话就可以满足,随着技术的不断发展,大家开始追求更沉浸式的实时音视频互动体验,而硬件提供的是更专业的拾音麦克风、高清摄像头及丰富的接口,软硬一体解决方案为会议提供更高品质的保障。
我们认为视频会议硬件会随着行业的深入往两个方向发展:一是高度集成化、二是智能化。高度集成化是兼顾了性能、美观度和易用性,这在未来企业级产品中会成为重要的指标;而智能化是软硬一体行业的大趋势,通过技术让拾音更精准,降噪更智能,让音视频硬件更好地服务各种工作、生活场景。

钉钉 F2 是国内首款单机实现 10 米高清音视频体验的视频会议一体机,基于软硬件算法、AI 技术与工程设计上的突破,实现了单机 10 米清晰拾音、智能导播(发言人特写)、双人分屏布局、4K 高清画质等特性,满足线上线下混合办公的开会需求,大幅提升中大型会议场景中的效率和沉浸感。
一款产品上市前,必定要经过一定范围内的应用或测试,钉钉 F2 也不例外。钉钉会议 Rooms 产品团队曾带着我们音频科学家们几乎跑遍整个阿里集团的会议室,去录制各种不同大小、不同构造的会议室的测试数据,从而提升产品的鲁棒性。
阿里有一种邀请企业做新品共创的文化,F2 的产研团队为了进一步验证用户需求和场景的适配度,常常申请直接坐到客户会议室里旁听,观察用户应用设备过程中是否是符合初始设计构想、有没有遇到问题、有没有新的需求。
在技术能力增强方面,针对挑战性场景,我们下一步可能会考虑增加定向拾音、智能音幕等功能。例如,当设备在一个嘈杂的环境中使用,开启智能音幕能够让特定区域目标说话人的声音更加清晰地被拾取,从而让参会者能够在复杂声学环境中更加轻松地交流。
在企业内,80% 的会议可能是线下的会议、20% 是线上会议。我们也一直在探索如何实现线下会议的数字化,比如分角色的会议记录,这里就会用到声源定位、声纹识别等技术。
F2 的定位就是一个硬件的载体,是一个容器。我们将通过音频模组、音视频模组、板卡模组以及整机集成等多种合作方式,向硬件厂商开放钉钉在音视频领域的产品、技术与算法,助力伙伴打造软硬一体、线上线下混合的会议体验。
基于远场拾音、智能降噪等音视频技术的突破,结合软硬一体产品的落地和开放的数字化平台,钉钉能够帮助用户更好地实现线上和线下会议数字化,并成为企业的资产沉淀下来。
附:钉钉蜂鸣鸟实验室在国际顶会上发表的自研麦克风阵列相关论文:
1.Weilong Huang,Jinwei Feng, ‘Minimum-Norm Differential Beamforming for Linear Array with Directional Microphones’,Interspeech 2021;
2.Weilong Huang,Jinwei Feng, ‘Differential Beamforming for Uniform Circular Array with Directional Microphones’, Interspeech 2020
3.Cheng Xue, Weilong Huang, Weiguang Chen, Jinwei Feng, ‘Real-time Multi-channel Speech Enhancement Based on Neural Network Masking with Attention Model’, Interspeech 2021;
4.ShiLiang Zhang, Siqi Zheng, Weilong Huang, Ming Lei, Hongbin Suo, Jinwei Feng and Zhijie Yan, ‘Investigation of Spatial-Acoustic Features for Overlapping Speech Detection in Multiparty Meetings’, Interspeech 2021;
5.Siqi Zheng, Weilong Huang, Xianliang Wang, Hongbin Suo, Jinwei Feng, Zhijie Yan, ‘A real-time speaker diarization system based on spatial spectrum’, ICASSP 2021;
6.Weiguang Chen (intern), Cheng Xue(intern), Xionghu Zhong“Cramer-Rao Lower Bound for DOA Estimation with an Array of Directional ´ Microphones in Reverberant Environments”; InterSpeech 2021
7.Fan Yu, .., Weilong Huang, etc“M2MET: THE ICASSP 2022 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE”, ICASSP 2022
8.Fan Yu, .., Weilong Huang, etc“ Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge”, ICASSP2022
9.Pengyu Wang, Feifei Xiong, Zhongfu Ye and Jinwei Feng, “Joint Estimation of Direction-Of-Arrival and Distance for Arrays with Directional Sensors Based on Sparse Bayesian Learning”, Accepted for Publication at Inter-Speech 2022
10.Feifei Xiong, Weiguang Chen, Pengyu Wang, Xiaofei Li and Jinwei Feng, “Spectro-Temporal SubNet for Real-Time Monaural Speech Denoising and Dereverberation”, Accepted for Publication at Inter-Speech 2022